| 8.7. Wissensrecherche - Antwortzeitverhalten |
|
|
Letztmalig dran rumgefummelt: 07.01.10 08:49:20 |
| Wie kommt man an
Informationen, die dann z. B. für Aufsätze, Referate usw. verwendet werden
können? Grundsätzlich können immer andere Personen (z. B. in Interviews)
befragt und verschiedene Medien (Zeitungen, Bücher, Filme usw.) genutzt
werden. Mit dem neuen Informationssystem Computer stehen aber auch neue Möglichkeiten der Informationsbeschaffung zur Verfügung. Das World Wide Web (WWW) birgt Datenbanken, Bilder und Texte zu jedem denkbaren Thema. Es gibt z. Z. - so wird geschätzt - weit über fünf Milliarden Dokumente in vielen Sprachen im WWW. Das Problem ist also: "Wie finde ich in kürzester Zeit die umfassendste und genaueste Information?" Diese Frage wurde mit der Entwicklung von Suchmaschinen beantwortet. |
||||||||||
|
1. Funktionsprinzip 2. Arten von Suchmaschinen 3. Verfeinerung der Anfrage 4. Katalogsysteme & thematische Kataloge 5. Intelligente Agenten 6. Web-Crawler 7. Metaindizierer (Spider oder auch Worms) 8. Übersicht Suchdienste 9. Wiki-Systeme 10. Filtern von Informationen 11. Verwandte Themen |
||||||||||
|
||||||||||
Quellen:
|
||||||||||
|
|
| 1. Funktionsprinzip |
|
|
|
| Suchen wir im Internet nach
bestimmten Begriffen, in unserem Fall "Ausländer", so werden wir unzählige
Stichworte finden (wie z. B. Ausländerzahl, -heime, -problematik, -herkunft
usw.), die es uns erschweren, schnell die für uns richtigen Ergebnisse zu
finden. Hier kommen die Suchmaschinen zur Anwendung. Suchmaschinen (in deutscher Sprache gibt es allein schon ca. 50) durchsuchen möglichst alle WWW-Dokumente und merken sich die Fundstellen der bestimmten Stichworte. Es gibt mittlerweile auch Suchmaschinen, die andere Suchmaschinen durchsuchen, damit nicht jede einzelne Suchmaschine aufgerufen werden muss (z. B. "MetaGer", die alle deutschen Suchmaschinen durchsucht: www.metager.de). Die Hinweise auf die Ergebnisse werden dann in Datenbanken gespeichert und stehen fortan zum Abruf bereit. Ein anderes, nur im weitesten Sinn ähnliches Suchsystem bilden die Kataloge. Hier sind die Einträge gezielt von einer Redaktion zusammengetragen und alphabetisch und thematisch geordnet worden. Die Vielfalt der Informationen - wie bei den allgemeinen Suchmaschinen - ist hier nicht vorhanden, doch sind die Informationen, wenn man das Suchen beherrscht sehr effektiv. Ein deutscher Katalog ist beispielsweise www.dino-online.de. |
|
| Damit für einen Begriff nicht alle damit zusammenhängenden Stichworte
(dies können Hunderte mit den entsprechenden Fundstellen sein) erscheinen,
müssen genauere Angaben gemacht werden. 10 goldene Regeln für die Recherche
|
|
|
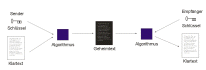
Eine Suchmaschine ist ein Programm zur Recherche von Dokumenten, die in
einem Computer oder einem Computernetzwerk wie z. B. dem World Wide Web
gespeichert sind. Internet-Suchmaschinen haben ihren Ursprung in
Information-Retrieval-Systemen. Sie erstellen einen Schlüsselwort-Index
für die Dokumentbasis, um Suchanfragen über Schlüsselwörter mit einer
nach Relevanz geordneten Trefferliste zu beantworten. Nach Eingabe eines
Suchbegriffs liefert eine Suchmaschine eine Liste von Verweisen auf
möglicherweise relevante Dokumente, meistens dargestellt mit Titel und
einem kurzen Auszug des jeweiligen Dokuments. Dabei können verschiedene
Suchverfahren Anwendung finden. Die wesentlichen Bestandteile bzw. Aufgabenbereiche einer Suchmaschine sind:
|
|
|
|
| 2. Arten von Suchmaschinen und ihre Anforderungen |
|
|
|
|
|
Wir bezeichnen das jetzige
Zeitalter als den Übergang zur Informationsgesellschaft - bemerken aber
spätestens mit der allgemeinen Verfügbarkeit des Internet, dass wir
eigentlich mit Information Wissen meinen. Leider ist nicht jede Information
Wissen - im Gegenteil: weitaus der größte Anteil der im Internet vorhanden
Information ist „Informationsschrott". Allerdings ist eben die Menge an
Informationen heute schon derartig groß, dass selbst der verbleibende kleine
wirkliche Wissensanteil für sich genommen gigantisch ist. Das World Wide Web stellt heute einen riesigen Wissensspeicher dar. Leistungsfähige Suchmaschinen werden benötigt, um in dieser heterogenen, weltweit verteilten Datenbank Informationen zu finden. Aufgrund der Tatsache, dass die meisten Inhalte in semistrukturierter Form vorliegen, versagen herkömmliche Abfragesprachen, die aus der Datenbanktechnologie bekannt sind. Vergleichbar wäre hier ein Buch, welches die Informationen enthält und die Suchmaschinen sind das Sachwortregister. |
| In der noch recht jungen Geschichte des World Wide Web sind bereits eine Vielzahl von Suchhilfen entwickelt worden. Als erster Suchdienst ist hier WAIS (Wide Area Information Server) zu nennen, welcher um 1991 entwickelt wurde. Es handelt sich hierbei jedoch um einen lokale Indexierer, mit dem keine Suche über mehrere Server des World Wide Webs möglich ist. Ein weiterer Nachteil ist der große Bedarf an Speicherplatz für den Index, der in etwa dem der indizierten Dokumente entspricht. Dieses Manko wurde durch die Suchmaschine Glimpse 1993 ausgeglichen. Zeitgleich entstanden die ersten serverübergreifenden Suchmaschinen, wie Lycos, AltaVista, Yahoo oder Excite . Die sog. All-in-One-Formulare sind in der Lage, mehrere Suchdienste nacheinander über eine einheitliche Eingabemaske abzufragen. Hierbei entsteht allerdings kein Performancegewinn. Dieser ist erst durch den Einsatz von Metasuchmaschinen zu erreichen, die einfache Suchdienste parallel abfragen und darüber hinaus noch weitere Vorteile aufweisen, worauf später detailliert eingegangen wird. | |
|
| 3. Verfeinerung der Suchanfrage |
|
|
|
|
|
Mit einem einzigen Suchwort kommt man häufig nicht sehr weit. Nur selten erzielt man gar keine Treffer, sehr oft lande ich so viele Treffer, dass das Durchsuchen aller Ergebnisse auch schon wieder Arbeit wird. Hier genau setzt die Verfeinerung des Suchkriteriums an. |
| 4. Katalogsysteme & thematische Kataloge |
|
|
|
|
|
|
| 5. Intelligente Agenten |
|
|
|
|
|
Mit
dem Fortschreiten der weltweiten Vernetzung und der damit verbundenen
steigenden Komplexität bedarf es neben den teilweise schon ausgereiften
Suchdiensten auch der Erforschung und Entwicklung neuer Methoden zur
Unterstützung der Nutzer für ein effizientes und zielgerichtetes Arbeiten im
Internet. In diesem Zusammenhang hört man oft den Begriff »Intelligente« oder »Mobile« Agenten. Diese weiterführenden Konzepte aus dem Bereich der Künstlichen Intelligenz versprechen eine weitere Professionalisierung des Umgangs mit dem Internet. Die aufgrund dieser Konzepte entwickelten intelligenten Agenten sind Programme, die Aufträge eines Benutzers oder eines anderen Programmes mit einem gewissen Grad an Eigenständigkeit und Unabhängigkeit ausführen und dabei Wissen über die Ziele und Wünsche des Benutzers anwenden. Wenn auch momentan keine universell gültige und akzeptierte Definition des Begriffs »Agenten« existiert, gibt es doch einige Charakteristiken, die solche Agenten gemeinsam haben (sollten): |
||||||||||||
Als »Mobile Agenten« werden solche bezeichnet, die sich selbst mitsamt ihrem Code und ihrem inneren Zustand, d.h. mit den bis dahin von ihnen gesammelten Informationen, durch das Internet bewegen können. Die hier besprochenen Charakteristiken sind nicht notwendig mobil. Nicht alle mobilen Agenten benutzen Mittel der Künstlichen Intelligenz. Bsp.: Webhound (http://webhound.www.media.mit.edu/projects/webhound/) |
| 6. Web-Crawler |
|
|
|
|
|
Zunächst indiziert ein Roboter (auch Spider
oder Worm genannt) die Dokumente
des World Wide Webs. Ausgehend von der
URL eines Dokuments traversiert der
Roboter das Internet in einem Breiten-
oder Tiefendurchlauf. Beim Breitendurchlauf
werden zunächst alle per Hyperlink
referenzierten externen Dokumente abgesucht.
Innerhalb dieser Dokumente wird genauso
verfahren. Der Algorithmus stoppt nach
einer vorher eingestellten Suchbreite
oder sobald der gesamte Graph abgesucht ist.
Beim Tiefendurchlauf wird zuerst den
Hypertextverweisen gefolgt, die auf einer
tieferen Ebene des Verzeichnispfades
liegen als das aktuelle Dokument. Dies geschieht
solange, bis eine bestimmte Tiefe
erreicht wurde oder der Algorithmus auf ein Dokument
stößt, das keinen weiteren Hyperlink
enthält. In diesem Fall wird einen Schritt
zurückgegangen, um mit der nächsten
Adresse fortzufahren. Kurz: Hier werden Programme ins Netz geschickt, die Seiten im WWW, Wort für Wort indizieren. Diese Ergebnisse werden dann statistisch ausgewertet und in Datenbanken abgelegt. Bsp.: Altavista, Lycos,... |
|
|
|
| 7. Meta-Indizierer (Spider oder auch Worms) |
|
|
|
|
|
Die auf diese Arten erreichten Dokumente werden einer lexikalischen Analyse unterzogen und die dabei gewonnenen Ergebnisse in die Metadatenbank des Suchdienstes eingestellt. Bei dieser Extraktion der Metadaten setzen die Suchmaschinen unterschiedliche Verfahren ein. Zunächst bietet sich an, die gesamten Textinformationen innerhalb des Dokuments zu indizieren. Dieses automatische Indizieren bringt jedoch Probleme mit sich. Kleinste Änderungen an den Dokumenten führen sofort zu einem Veralten der Metadaten. Auch ist so keine Gewichtung der Bedeutung der indizierten Daten möglich. Bedingt durch die Größe des Internets erfassen viele Suchmaschinen lediglich den Anfang des Dokuments. |
| 8. Übersicht über Suchdienste |
|
|
|
|
|
Eine Suchmaschine ist ein
Programm zur Recherche von Dokumenten, die in einem Computer oder einem
Computernetzwerk wie z. B. dem World Wide Web gespeichert sind.
Internet-Suchmaschinen haben ihren Ursprung in
Information-Retrieval-Systemen. Sie erstellen einen Schlüsselwort-Index für
die Dokumentbasis, um Suchanfragen über Schlüsselwörter mit einer nach
Relevanz geordneten Trefferliste zu beantworten. Nach Eingabe eines
Suchbegriffs liefert eine Suchmaschine eine Liste von Verweisen auf
möglicherweise relevante Dokumente, meistens dargestellt mit Titel und einem
kurzen Auszug des jeweiligen Dokuments. Dabei können verschiedene
Suchverfahren Anwendung finden. Die wesentlichen Bestandteile bzw. Aufgabenbereiche einer Suchmaschine sind:
|
|
|
| 9. Wiki-Systeme |
|
|
|
|
|
Eine relativ neue Geschichte ist die Tatsache, dass die Benutzer ihr Internet und natürlich auch die gewünschten Inhalten selbst erstellen. Den Anfang in dieser Richtung haben historisch die Blogs gemacht - eine Art Online-Tagebuch für begeisterte Webnutzer in Communities. Nicht lange hat es gedauert, und der Name wurde Programm: WIKIPEDIA ist ein System, welches aus unserem Leben wohl schon nicht mehr wegzudenken ist (auch wenn Du "googelst", landest Du auf den meist indizierten Seiten - und die stehen bei WIKIPEDIA) |
| 10. Filtern von Informationen |
|
|
|
|
|
Häufig sind die Ergebnisse einer Suchanfrage für viele Problemstellungen unbrauchbar. Entweder kommt gar keine sinnvolle Antwort, oder aber (das ist viel häufiger der Fall) ist die Anzahl der Treffer so groß, dass die ganze Menge zu durchsuchen auch wieder mit erhöhtem Aufwand verbunden ist. | ||||||||||||||||||||
Suche nach Redewendungen (zusammengehörende Wörter)Wenn man nach einer Redewendung wie z.B. sicheres Fahren oder Frankfurt am Main suchen möchten, in denen die Wörter in exakt dieser Reihenfolge erscheinen, dann setzt man diese Anfrage in Anführungszeichen. Bei einer Suche nach sicheres Fahren werden als Ergebnis sämtliche Seiten auflistet, auf denen einer oder sämtliche angegebene Begriffe in beliebiger Reihenfolge irgendwo auf der Seite vorkommen (natürlich werden all jene Seiten als relevanter bewertet, auf denen alle Begriffe erscheinen). Eine Suche nach "Frankfurt am Main" jedoch findet ausschließlich jene Seiten, auf denen exakt diese Wortfolge vorkommt. Plus (+) und Minus (-) ZeichenDiese Zeichen teilen den Suchmaschinen mit, welche Begriffe in den ausgeworfenen Dokumenten vorhanden sein müssen (+) und welche nicht vorhanden sein dürfen (-). Man muss aber darauf achten, dass man zwischen Zeichen und Wort keine Leerstelle eingibt. Plus (+)
Minus (-)
Der Joker (*)Der Stern besitzt Joker-Funktion. Er dient als Platzhalter. Bei der Eingabe von bund* wird zum Beispiel auch der Bundestag bei der Suche mit berücksichtigt. Der Punkt (.)Der Punkt am Wortende sorgt für genaue Übereinstimmung. So gibt schiff. bei der Suche nur Schiff an. Bool'sche OperatorenÜber die Bool'schen Operatoren wird der auf inhaltlichen Zusammenhängen basierende Suchmechanismus des jeweiligen Suchprogramms ausgeschaltet, so dass man nach Dokumenten suchen kann, die exakt die gewünschten Wörter enthalten. Zu den Bool'schen Operatoren gehören AND, AND NOT, OR und die Klammern. Diese Operatoren müssen unbedingt in KAPITALIEN (Großbuchstaben) eingegeben werden und von je einer Leertaste auf beiden Seiten umgeben werden - ansonsten funktionieren sie nicht. Wie in allen Programmiersprachen und SQL-Systemen (Datenbankabfragesprachen) haben die Bool'schen Operatoren eine Vorrangautomatik (Wertigkeit) - so wird NOT als erstes ausgwertet, gefogt von AND dann erst OR - andere Bindungsfolgen müssen gekalmmert werden. AND
OR
AND NOT
( )
|
|||||||||||||||||||||
Spezialfunktionen für die Suche im WWW
|
| 11. Verwandte Themen |
|
|
|
|
|
Kryptologie ist eine der Disziplinen, die sich mit der Sicherheit auch und vor allem von Passworten befasst. Allerdings ist hier auch eine moralische und eine ganz menschlich Seite (eher Schwäche) mit einzurechnen. Aber auch Netzwerktechnik und ihr Schutz ganz allgemein spielen hier mit hinein. | |||||||||||||||||||||
|
|
|
|||||||||||||||||||||
|
|
|
|||||||||||||||||||||
|
||||||||||||||||||||||
|
||||||||||||||||||||||
|
||||||||||||||||||||||
|
|
|
|||||||||||||||||||||
|
|
|
|||||||||||||||||||||
|
zur Hauptseite |
© Samuel-von-Pufendorf-Gymnasium Flöha | © Frank Rost Oktober 2007 |
|
... dieser Text wurde nach den Regeln irgendeiner Rechtschreibreform verfasst - ich hab' irgendwann einmal beschlossen, an diesem Zirkus (das haben wir schon den Salat - und von dem weiß ich!) nicht mehr teilzunehemn ;-) „Dieses Land braucht eine Steuerreform, dieses Land braucht eine Rentenreform - wir schreiben Schiffahrt mit drei „f“!“ Diddi Hallervorden, dt. Komiker und Kabarettist |
|
Diese Seite wurde ohne Zusatz irgendwelcher Konversationsstoffe erstellt ;-) |















{kind=link}
{kind=link}
{kind=link}