| 1.8. SQL - also die System-Query-Language - die Sprache der Datenbanktechnik |
|
|
Letztmalig dran rumgefummelt: 24.01.18 20:22:41 |
|
Verschiedene Datenbankmanagementsysteme realisieren bereits
heute Funktionen erwarteter späterer SQL-Standards, d. h. solcher nach SQL89. Andererseits fehlen auch in einigen namhaften DBMS noch Funktionen, die von SQL89 vorgeschrieben sind. Entsprechend den aktuellen Erfordernissen der Praxis gibt es SQL in folgenden Formen:
Die einzelnen Statements (Anweisungsfolgen)
werden in der Regel wie folgt dargestellt: Name des Statements, Bedeutung, Syntax, Beschreibung, Beschränkungen, Hinweise, Beispiele. |
|||||||
|
1. Geschichte der SQL 2. Entstehung von SQL 3. Relationale Datenbanken - Objektrelationale Datenbanken 4. Datenbankorganisation 5. Erweiterter Begriffkatalog der Datenbanktechnik 6. Verwandte Themen |
|||||||
|
|||||||
|
|
Quellen:
|
||||||
|
|
|
| 1. Entstehung von SQL |
|
|
|
|
|
SQL—Strukturierte Abfragesprache für Datenbanken Quelle Dr. Wilfried Grafik, Berlin
„SQL-strukturierte
Abfragesprache für Datenbanken“; Mikroprozessortechnik; © Verlag Technik
Berlin 1992; S. 22 ff. SQL ist eine standardisierte Sprache für das Erstellen und Bearbeiten (relationaler) Datenbanken. Der Beitrag untersucht Ursprung, Wesen, Ziel und Entwicklungsperspektiven von SQL (Structured Query Language). Die wichtigsten Sprachkonstrukte werden in ihrer Syntax und an Beispielen erläutert. Natürlich hat jeder implementierte Standard seine Besonderheiten. Auch dBase IV unterstützt in Anfängen die Verwendung von SQL. |
|
Von ALPHA zu SQL 1970 veröffentlichte E.F. Codd /1/, ein Mitarbeiter von IBM, sein relationales Datenmodell. Dieses Datenmodell sollte durch seine theoretische Grundlage einige Nachteile der anderen beiden Datenmodelle, des hierarchischen und des Netzwerk-Datenmodells, beseitigen. Zum einen ging es um eine konsequentere Trennung von logischer und physischer Ebene einer Datenbank und zum anderen um die Entwicklung einer Datenbanksprache, die das "Was" und nicht das "Wie" in den Vordergrund stellt. Mit anderen Worten: Es ging nicht so sehr um die Formulierung von Algorithmen, sondern um eine deskriptive Notation von Datenbeziehungen und Anfragen. Auf dem Gebiet der höheren Programmiersprachen lagen Erfahrungen in der Formulierung von Algorithmen vor. Eine Entwicklung im evolutionären Sinne führte zu Erweiterungen von Sprachen der dritten Generation für die dauerhafte (persistente) Datenhaltung und schließlich zu Datenmanipulationssprachen, beispielsweise DL/1 (DL-data language) im hierarchischen Datenverwaltungssystem IMS von IBM. (Man beachte die Ähnlichkeit in der Namensgebung zu PUI, programming language, von IBM). zu viele Angaben in diesen Spra-chen beschrieben, wie ein Datensatz aufgebaut ist, wie er gespeichert wird, wie seine Verbindung zu Sätzen anderer Typen ist, wie Indexstrukturen organisiert sind usw. Diese Angaben haben mit dem logischen Schema einer Datenbank nur wenig zu tun. Allerdings, und das muß man diesen Kalten DBMSS lassen, wird dadurch die Verarbeitungsgeschwindigkeit wesentlich gesteigert (DBMS - database Management System). Standardisie-rungsbestrebungen gab es auch für das Netzwerk-Datenmodell, die letztlich in CODASYL-Vorschlägen (CODASYL - conference on data Systems languages) der DBTG(databasetaskgroup)von 1971 bis 1978 zusammengefaSt sind. Um die Semantik klarer zu fassen, ging das Bemü-hen dahin, eine möglichst deskriptive Sprache zu finden, also das Swasi zu modellieren und die konkrete Implementation auf der physischen Ebene weitgehend dem Datenbankverwaltungssystem zu überlassen. |
|
|
Standard-Sprache-Datenmodell SQL wurde also primär für relationale DBMS entworfen. Der erste Versuch einer ernsthaften Implementation wurde von IBM im DBMS System R unternommen. System R stellt mehr einen Prototyp dar, da ernsthafte Anwendungen im kommerziellen Bereich in der Literatur kaum zitiert werden. Aus dem System R entstanden zwei wesentliche relationale Datenbankverwaltungssysteme, DB2 von IBM für große Mainframes und Oracle von der Firma Oraele GmbH. So verwundert die in Oracle ausgewiesene Kompatibilität zu DB2 auch nicht. Selbstverständlich gibt es weitere bedeutende relationale DBMS (Informix, Sybase, Ingres, DDB4, ...), die hier weder alle erwähnt noch besprochen werden sollen.
Kennern der Softwareszene drängt sich in diesem Zusammenhang die Erinnerung an das Schicksal des Pascal-Standards auf, der durch Turbo-Pascal aufgeweicht wurde. Auf dem Gebiet der Datenbanken ist die Notwendigkeit eines Standards nach meiner Auffassung noch dringlicher. Denken wir nur an den Datenaustausch zwischen Datenbanken, an die kooperative Arbeit unterschiedlicher Datenbanken in einem Netz usw. (vgl. dazu 13). Bezieht sich eine Anfrage gleichzeitig auf mehrere Datenbanken, so kann diese Anfrage nur in einer Sprache formuliert sein und muss von allen angesprochenen Datenbanken verstanden werden. Hier liegt sicher ein erheblicher Qualitätsunterschied zur Portabilität von Quellprogrammen, etwa in Pascal oder C. Hersteller und Nutzer sind gleichermaßen gezwungen, einen Standard zu formulieren und ihn einzuhalten. Welche Stellung hat SQL, als Sprache für das relationale Datenmodell (RDM), im Verhältnis zu anderen Datenmodellen? Drei Dinge sind zu berücksichtigen:
Ein Datenbankentwurf nach dem ER-Modell lässt sich relativ leicht ins relationale Modell überführen. CASE-Toolsfürdiesen Schritt sind im Angebot. |
|
|
Die Datenmanipulationssprache Wir verschieben zunächst die Definition von Relationen auf einen späteren Abschnitt und beschäftigen uns mit der zentralen Anweisung der DML von SQL: der SELECT-Anweisung. Sie hat, stark vereinfacht, die Grundstruktur |
| 2. Entstehung von SQL |
|
|
|
|
|
Das American National Standard Institute (ANSI) bildete Ende der 70er Jahre eine Gruppe zur Entwicklung eines Standards für relationale Datenbanksprachen. Am Anfang standen Untersuchungen der bis dahin voneinander isoliert entwickelten und implementierten Sprachen von DBMS mit dem Ziel, gemeinsame Funktionen zu erkennen, die sich einer Vereinheitlichung besonders anboten. Die Arbeit verlief zunächst analytisch, wurde aber bald zunehmend von theoretischen Vorstellungen getragen.
Erstaunlich ist, dass zur damaligen Zeit wichtige Forderungen des Standards bezüglich der Integritätssicherung nicht erfüllt wurden.:
|
|
Das American National Standard Institute (ANSI) bildete Ende der 70er Jahre eine Gruppe zur Entwicklung eines Standards für relationale Datenbanksprachen. Am Anfang standen Untersuchungen der bis dahin voneinander isoliert entwickelten und implementierten Sprachen von DBMS mit dem Ziel, gemeinsame Funktionen zu erkennen, die sich einer Vereinheitlichung besonders anboten. Die Arbeit verlief zunächst analytisch, wurde aber bald zunehmend von theoretischen Vorstellungen getragen. 1981 begann die Entwicklung des Standards auf der Grundlage einer Datenbanksprache, die durch die Fa. IBM im System/R bereits implementiert worden war. Seit 1982 wurden die Standardisierungsbestrebungen durch die International Standards Organization (ISO) (Westeuropa) und verschiedene nationale Standardisierungsorganisationen, die mit der ISO assoziiert waren, übernommen. Es entstand die ISO-Gruppe für Database Languages, um den ANSI-Standard zu analysieren und als Grundlage für die Entwicklung eines ISO-Standards zu nutzen. ISO und ANSI veröffentlichten 1986 gemeinsam den ersten Standard für SQL, heute im allgemeinen SQL86 genannt. Im Standard SQL86 wurden grundlegende Sprachkonstrukte zur Datendefinition und -manipulation definiert. Aufgrund der bis dahin sehr differenzierten Datenbanksprachen umfasste dieser Standard nur die wichtigsten Funktionen, zu denen einheitliche Auffassung zu erzielen war. 1989 wurde eine Weiterentwicklung des SQL86-Standards unter dem Namen SQL89 veröffentlicht, die als wichtigste Erweiterung umfassendere Daten- und Referenzintegritätsdeklarationen beinhaltete. Die danach noch vorhandenen Unzulänglichkeiten sollen mit SQL2 und SQL3 beseitigt werden. 1990 wurde erwartet, dass der Standard SQL2 im Jahre 1992 publiziert werden könnte. Der Standard SQL3 sollte nicht vor 1995 veröffentlichungsreif sein. Bis heute können diese Termine kaum als erfüllbar angesehen werden Der SQL2-Standard ist heute, auch nur teilweise, bei wenigen DBMS implementiert. Vorabausgaben von SQL2 sind unter den Bezeichnungen Entry SQL2 und Intermediate SQL2 bekannt geworden. Der volle Standard heißt z. Z. Full SQL2. Interessant sind die benötigten Druckseiten der Standards bzw. deren Entwürfe: SQL86 umfasst etwa 100 Seiten, SQL89 etwa 115 Seiten; für SQL2 und SQL3 werden bis zu 700 Seiten erwartet. Diese Explosion, die nicht nur auf den Seitenumfang bezogen ist, dürfte Anlass dafür sein, über das Machbare, Implementierbare und vom Nutzer Anwendbare nachzudenken. Durch die Parallelentwicklung des Sprachstandards durch ANSI (USA) und ISO (Europa) ergeben sich geringfügige Unterschiede, die jedoch nicht grundsätzlicher Natur und für die praktische Arbeit ohne Bedeutung sind. Im übrigen sind die meisten heute kommerziell vertriebenen DBMS Entwicklungen aus den USA, für die der ANSI-Standard Grundlage ist. Zusammenfassend können die Erweiterungen und geplanten Erweiterungen wie folgt zusammengefasst werden: |
|
|
Standard SQL86 formulierte die grundsätzlichen Forderungen an die Datendefinition und Datenmanipulation. |
|
|
Standard SQL89 forderte als wesentliche Funktionen die Unterstützung der Integrität: - Sicherheit/Zugriffsschutz GRANT-Statements View-Einrichtung - Integrität NOT NULL PRIMARY KEY CHECK FOREIGN KEY UNIAUE REFERENCE - Recovery/Concurrency Transaktionen-Management COMMIT WORK ROLLBACK WORK 3. In späteren Standards (z. B. SQL2) wird erwartet, daß folgende Eigenschaften und Funktionen festgeschrieben werden: - Wirtssprachen für ESQL und die Modulsprache COBOL, FORTRAN, PASCAL, PL/1 und neu: ADA und C 1 Die Erläuterung erfolgt teilweise in den Heften 1 und 2 dieser Reihe; im Zusammenhang mit SQL wird auf die folgenden Abschnitte dieses Heftes verwiesen. |
| Datenhaltung - Datenpflege: | Gesamtheit der Maßnahmen, um einen Datenbestand aktuell zu halten | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| Entitytyp | Entitytyp (Tabellenname): Eine Entität stellt einen Themenkreis dar, welcher Elemente mit gleichen Merkmalen umfasst. Bsp. Personen, Kurse, Ersatzteile etc. | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| Entitymenge | (Datensätze): Die Entitätsmenge beinhaltet alle zu den Merkmalen einer Entität gehörenden Werte. Sie entspricht allen gespeicherten Datensätzen einer Tabelle. | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tupel: | ein Datensatz bzw. eine einzelne Zeile in der Tabelle; enthält alle auf ein Objekt bezogenen Feldwerte bzw. Merkmalsausprägungen | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| Attribut: |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||
| Attributwert: | (Wert, Datum): Dies ist ein Datenwert, welcher das zugehörige Attribut eines Tupels beschreibt. Bsp: Attribut = Name; Attributwert = Müller. Vielfach wird anstatt des Wortes „Wert“ der Begriff „Datum“ verwendet. Datum und Wert sind Synonyme, haben aber mit dem Kalenderdatum nichts zu tun. | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| Domäne: | Menge der verschiedenen Feldwerte eines Attributs (praktisch der Wertevorrat für das Feld) | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| Schlüsselfeld: | dient der eindeutigen Identifikation eines Tupels in einer Relation und der Herstellung von Beziehungen zwischen verschiedenen Relationen | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| Konsistenz: | ist die Widerspruchsfreiheit der Datenhaltung | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| NULLWERTE: | Wenn ein Attribut eines Tupels
einen Nullwert enthält, so bedeutet dies, dass dieses Attribut keinen
Attributwert besitzt und somit keine Information beinhaltet. Der Nullwert
darf nicht mit der Zahl Null verwechselt werden. Die Zahl Null stellt eine
Information dar, der Nullwert jedoch nicht. Die vollständige Spezifikation in der klassischen Programmierung verlangt eine „abgeschlossene Welt“ (Closed World Assumption). Das stellt die Voraussetzung für das Aristotelische Zweiwertigkeitsprinzip (wahr oder falsch) dar und gestattet die Verwendung der Boolschen Logik. In der Datenbankpraxis wird jedoch (mindestens) ein dritter Zustand benötigt: Ich weiß nicht. Er wird als NULL-Wert (NULL value) bezeichnet und darf nicht mit dem Neutralen Element „0“ der Addition in der Arithmetik verwechselt werden: NULL ist ein Status, kein Wert Die NULL-Werte erlauben, die abgeschlossene Welt zu „öffnen“ (Open Wold Assumption), bzw. durch Prädikate, wie sonstige, keine Angaben, unbekannt, noch nicht bekannt, kann der Wertebereich eines Attributes so erweitert werden, dass nun wieder mit einer abgeschlossenen Welt gearbeitet werden kann. Die Verwendung von NULL-Werten macht eine mehrwertige Logik (J. LUKASIEWICS) erforderlich. Die klassischen Wahrheitstafeln für AND, OR und NOT erhalten dann folgendes Aussehen (wobei der NULL-Wert durch „?“ repräsentiert wird):
AND-Logik mit NULL-Werten
OR-Logik mit NULL-Werten
NOT-Logik mit NULL-Werten Die Auswirkung der NULL-Werte sei am Beispiel der Berechnung des durchschnittlichen Monatseinkommen (AVG (averange)) illustriert:
Bruttoverdiensttabelle mit NULL-Werten - das Durchschnittsgehalt ermittelt sich Summe : 4 und nicht Summe : 5 |
| 3. Realationale Datenbanken |
|
|
|
|
|
Eine Relation ist eine Beziehung nicht nur in Datenbankgefügen, sondern auch als philosophische Kategoerie. Es werden zu einem Zeitpunkt immer genau zwei Objektgruppen zueinander in Beziehung gesetzt. Objektgruppen sind hier zwei Mengen von Elementen der uns umgebenden Welt mit gemeinsamen (nicht notwendigerweise gleichen) Eigenschaften, also zum Beispiel SCHUELER, AUTO, FILM, MASCHINE, GEMUESE, BUCH usw. | |
| Relation | eine Tabelle, in der in
zweidimensionaler Anordnung die Datenelemente erfasst sind, wobei:
|
|
| relationale Datenbank | eine aus verschiedenen Relationen (Bestands- und ggf. Beziehungsrelationen) aufgebaute Datenbank | |
| Integrität | beschreibt die Unversehrtheit der Datenhaltung nach Maßnahmen der Datenpflege | |
| Konsistenz | Widerspruchsfreiheit | |
| Anomalie | "Ungereimtheit", welche sich erst durch die Nutzung der Datenbasis eingeschlichen haben ... | |
| Index: | ist der aktuelle Verweis auf Datensätze (auch Tupel oder Entities genannt) - es sind nicht die Tupel selbst! | |
| Schlüssel | schafft Übergangsmöglichkeiten zwischen den Entitytyps eines Diskurses | |
| 4. Datenbankorganisation |
|
|
|
|
|
||
| Hierarchische Datenbanken: | Beim hierarchischen Modell werden die Daten in einer streng hierachischen Ordnung angelegt (Baumstruktur). Das hierarchische Modell wird aus einer Hierarchie von Entitätstypen (Datensätzen) aufgebaut, die mit einem Vaterentitätstyp auf einer höheren Ebene und einen oder mehreren abhängigen Entitätstypen (Datensätzen) auf einer niedrigeren Ebene verbunden ist. Zwischen einer Vaterentität kann es direkte Beziehungen zu verschiedenen Sohnentitäten geben. | |
| Netzwerkmodell von Datenbanken: | eine aus verschiedenen Relationen (Bestands- und ggf. Beziehungsrelationen) aufgebaute Datenbank | |
| Objektorientierte Datenbanken | Menge der verschiedenen Feldwerte eines Attributs (praktisch der Wertevorrat für das Feld) | |
| 5. Erweiterter Begriffskatalog der Datenbanktechnik |
|
|
|
|
|
||
| 3GL | Third Generation Language | |
| 4GL | Fourth Generation Language | |
| BLOB | Binary Large Objects | |
| C | Programmiersprache C | |
| CASE | Computer Aided Software Engeneering | |
| DBMS | Data Bank Management System | |
| DDL | Data Desription Language | |
| DML | Data Manipulation Language | |
| ESQL | Embedded SQL | |
| FTP | File Trannsfer Protocol | |
| LAN | Local Area Network | |
| MMD | Multimedia Datenbank | |
| QL | Query Language | |
| RID | Record Identifier | |
| SQL | Structured Qury Language Query Language | |
| 6. Verwandte Themen |
|
|
|
|
|
Da schon einmal feststeht, dass Datenbanken das Non plus Ultra der Informatik sind, und dies sowohl von der theoretischen als auch praktischen Seite gilt, gibt's nun hier die Verwandtschaften und somit auch das Basiswissen zu Datenbanken auf Abiturniveau schlechthin. | |||||||||||||||
|
||||||||||||||||
|
||||||||||||||||
|
||||||||||||||||
|
zur Hauptseite |
© Samuel-von-Pufendorf-Gymnasium Flöha | © Frank Rost im November 1995 |
|
... dieser Text wurde nach den Regeln irgendeiner Rechtschreibreform verfasst - ich hab' irgendwann einmal beschlossen, an diesem Zirkus (das haben wir schon den Salat - und von dem weiß ich!) nicht mehr teilzunehemn ;-) „Dieses Land braucht eine Steuerreform, dieses Land braucht eine Rentenreform - wir schreiben Schiffahrt mit drei „f“!“ Diddi Hallervorden, dt. Komiker und Kabarettist |
|
Diese Seite wurde ohne Zusatz irgendwelcher Konversationsstoffe erstellt ;-) |
![]()


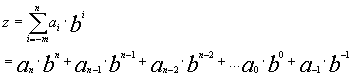





{kind=link}