| 6.2. Standard-SQL |
|
|
Letztmalig dran rumgefummelt: 09.01.19 07:23:54 |
|
SQL - Structured Querry Language ist die am häufigsten angewandte Systemabfragesprache für Datenbestände (SQL - "intergalactic data speak"), die - von IBM entwickelt - für eine Reihe von Applikationen zur Verfügung gestellt wird, welche mit Datenbeständen relationaler Art in Verbindung gebracht werden können. Dabei kann durch Verknüpfungen in mehreren Dateien nach bestimmten Kriterien gesucht bzw. diese herausgefiltert werden. Ihr großer Vorteil ist die sehr stark an die natürliche Sprache Englisch angenäherte Form der Kommandos für alle typischen Aufgaben der Arbeit mit Datenbanken wie:
|
|||||||
|
0. SQL - Vorbemerkungen 1. SQL - die Standarddatenbanksprache - historischer Abriss 2. Basiskonstrukte 3. Identifer, Operatoren und Funktionen 4. Basiskonstrukte 5. SUBSELECTS 6. Statements für Metadaten 7. Logische Prädikate 8. Subqueries 9. HAVING-Klausel 10. GROUP BY |
|||||||
Quick-Index:
|
|||||||
|
|||||||
|
|
Quellen:
|
||||||
|
|
Das speziell von
Microsoft für seine Produkte entwickelte Paket heißt
"Microsoft Query" und kennt zumindest die
Standards von SQL, welche es noch erweitert.
Neben diesen Komponenten gehören zum SQL Instrumente zur Systemverwaltung und zur Beschleunigung der Befehlsbearbeitung "Performanz-Optimierung” (nur für Datenbank-Administrator). Die Datenbanksprache SQL gewinnt zur Zeit wachsende Bedeutung. Als Ursachen hierfür sind folgende Tatsachen zu sehen:
|
| 0. Allgemeine SQL-Statemaents |
|
|
|
|
|
Personenbezogene Daten sind Einzelangaben über persönliche oder sachliche Verhältnisse einer bestimmten oder bestimmbaren natürlichen Person (Betroffener). Mit der Verfügbarkeit gewinnt man extrem viel Einfluss über eine Person - entsprechnd groß ist ihre Schutzbedürftigkeit. Dies zu erkennen hat übrigens eine ganze Weile gedauert und ist in ihrer Tragweite auch heute noch nicht jedem bewusst. | ||||||||||||||||
|
Grundlage der relationalen Datenbanken-SQL ist die Tabelle mit ihren x-y (Zeilen-, Spaltenbeziehungen) - Allgemeine SQL-Statements
|
|||||||||||||||||
|
SELECT
DISTINCT ausgabefelder,(mathematische
ausdrücke, bezeichner] |
|||||||||||||||||
|
Grafische Darstellung der Selektion aus einem Datenbestand |
|||||||||||||||||
|
Grafische Darstellung der Projektion aus einem Datenbestand |
|||||||||||||||||
|
Grafische Darstellung des Joins aus mehreren verknüpften Datenbeständen |
| 1. SQL - Die Standarddatenbanksprache - historischer Abriss |
|
|
|
|
|
Daten (lateinisch Data) - ursprünglich geschichtliche Zeitangaben; heute allgemeine Bezeichnung für die Zahlenwerte der Merkmalsgrößen von physikalisch- technischen Objekten (Kenn-Daten), Ereignissen, Prozessen und Abläufen (z. B. Betriebs-Daten bei techn. Vorgängen und Geräten, Bahn-Daten der Bewegungen von Raumflugkörpern). In der Datenverarbeitung versteht man unter Daten anfallende Informationen, die sich in einer maschinell verarbeitbaren Form darstellen lassen. |
|
|
Verschiedene DBMS realisieren bereits Funktionen erwarteter späterer
SQL-Standards, d. h. solcher nach SQL89. Andererseits fehlen auch in einigen
namhaften DBMS noch Funktionen, die von SQL89 vorgeschrieben sind. Entsprechend den aktuellen Erfordernissen der Praxis gibt es SQL in folgenden Formen:
Hier wird SQL in der interaktiven Form behandelt. Dabei werden die Statements
im Dialog zwischen Anwender (in der Regel ein Endbenutzer bzw. ein
Anwendungsprogrammierer) und Rechner eingegeben und ausgeführt. BatchSQL
gestattet es, Folgen von SQL-Statements und Steuerstatements zu einem Batch-File
zusammenzufassen, zu speichern und im Bedarfsfalle zur erneuten Ausführung,
durchaus auch nach Modifikation, aufzurufen, geändert zu speichern usw. Diese
Möglichkeiten sind heute in der Regel nur in älteren Versionen von
Datenbankbetriebssystemen mit eigener Datenbanksprache vorhanden (MIMER mit der
Sprache QL; INGRES mit der Sprache QUEL). Dafür gibt es die vom Standard
geforderte Modulsprache, die jedoch kaum implementiert ist und andererseits auch
die Brücke zu ESQL schlägt. ESEL, das die Einbettung von SQL-Statements in
Programme, die in einer Wirtssprache geschrieben sind, gestattet. Dort wird auch
die spezielle Form des Dynamic-SQL (Dyn SQL) behandelt. Geschlossene Systeme als
sogenannte Sprachen der vierten Generation (4GL) werden schließlich gesondert
dargestellt. Name des Statements, Bedeutung, Syntax, Beschreibung, Beschränkungen, Hinweise, Beispiele. |
|
|
Historische Entwicklung und
gegenwärtiger Stand des Standards Eine sehr gute
Darstellung der historischen Entwicklung und weiterer Vorhaben der
Standardisierung von SQL findet man in einem Buch von Date [7]1 und in einem
Beitrag von Shaw [24], der ein führendes Mitglied der
Standardisierungsgruppe der ANSI ist. Auch in [8] ist ein interessanter
Abriss der Entwicklung enthalten. Grundsätzlich kann festgestellt werden,
dass die optimistischen Termine aus den Jahren 1989/1990 für die folgenden
Jahre nicht durchweg eingehalten werden konnten, was in der Schwierigkeit
der Problematik zu suchen ist. U. a. sind folgende Fragen zu beantworten:
Was ist von dem theoretisch Fundierten für die Praxis allgemein relevant?
Was lässt sich von den aktuellen Forderungen heute effektiv oder überhaupt
implementieren? Und alle Fragen müssen bei unterschiedlicher Interessenlage
konkurrierender Entwicklerfirmen einheitlich beantwortet werden!
gegenübergestellt werden. Erstaunlich ist, dass zur damaligen Zeit wichtige Forderungen des Standards bezüglich der Integritätssicherung nicht erfüllt wurden. Hier ein kurzer Überblick: CREATE TABLE: Spalte NOT NULL bei allen genannten DBMS möglich; INDEX UNIQUE mit Ausnahme von INGRES möglich Damit war die Möglichkeit gegeben, einen Primärschlüssel wenigstens
indirekt nutzergesteuert zu erzeugen. Bei keinem der genannten DBMS war es
jedoch möglich, eine Spalte als PRIMARY KEY bzw. FOREIGN KEY2 direkt zu
definieren. (Das DBMS MIMER in der Version 5.1 erfüllte dagegen diese
Funktionen bereits 1988!) Den UNION-Operator (sowie auch die Operatoren
INTERSECT und MINUS) zur Verbindung von mehreren Select-Abfragen in einem
einzigen Statement gab es nur bei ORACLE. |
|
|
1989 wurde eine Weiterentwicklung des SQL86-Standards
unter dem Namen SQL89 veröffentlicht, die als wichtigste Erweiterung
umfassendere Daten- und Referenzintegritätsdeklarationen beinhaltete. Die
danach noch vorhandenen Unzulänglichkeiten sollen mit SQL2 und SQL3
beseitigt werden. 1990 wurde erwartet, dass der Standard SQL2 im Jahre 1992
publiziert werden könnte. Der Standard SQL3 sollte nicht vor 1995
veröffentlichungsreif sein. Heute ( Stand 1994) können diese Termine kaum
als erfüllbar angesehen werden Der SQL2-Standard ist heute, auch nur teilweise, bei wenigen DBMS implementiert. Vorabausgaben von SQL2 sind unter den Bezeichnungen Entry SQL2 und IntermediateSQL2 bekannt geworden. Der volle Standard heißt z. Z. Full SQL2. Interessant sind die benötigten Druckseiten der Standards bzw. deren Entwürfe: SQL86 umfasst etwa 100 Seiten, SQL89 etwa 115 Seiten; für SQL2 und SQL3 mehr als 700 Seiten. Diese Explosion, die nicht nur auf den Seitenumfang bezogen ist, dürfte Anlass dafür sein, über das Machbare, Implementierbare und vom Nutzer Anwendbare nachzudenken. Durch die Parallelentwicklung des Sprachstandards durch ANSI (USA) und ISO (Europa) ergeben sich geringfügige Unterschiede, die jedoch nicht grundsätzlicher Natur und für die praktische Arbeit ohne Bedeutung sind. Im übrigen sind die meisten heute kommerziell vertriebenen DBMS Entwicklungen aus den USA, für die der ANSI-Standard Grundlage ist. Zusammenfassend können die Erweiterungen und geplanten Erweiterungen wie folgt zusammengefasst werden:
Sicherheit/Zugriffsschutz
Integrität
Recovery/Concurrency Transaktionen-Management
Wirtssprachen für ESQL und die Modulsprache COBOL, FORTRAN, PASCAL, PL/1 und neu: ADA und C Domains CREATE / DROP DOMAIN Datentypen
Schemadefinition
mengentheoretische Operatoren INTERSECT und EXCEPT (Durchschnitt und Differenz) - Scroll Cursor neue skalare Funktionen für arithmetische, Zeit- und Kettenoperanden (z. B. SUBSTR, LENGTH) Transaktionen SET TRANSACTION (Setzen des Modus der Transaktionensteuerung) temporäre Tabellen (auch Views) dynamisches SQL Die meisten dieser SQL2-Forderungen sind bereits 1988 im DBMS MIMER realisiert worden. Andererseits erfüllen auch andere DBMS einige Forderungen von SQL2. Ein vollständiger Überblick über die verschiedenen Implementationen und die Erfüllung der verschiedenen SQL-Standards ist aufgrund der Dynamik in der Entwicklung von Datenbankbetriebssystemen de facto nicht zu erarbeiten. |
|
|
Vereinbarungen über die Metasprache
Zur syntaktischen Beschreibung einer Programmiersprache benötigt man eine
Metasprache, d. h. eine Sprache zur Beschreibung der eigentlichen Sprache,
hier SQL. Wir verwenden für die Beschreibung von SQL fast ausschließlich
Syntaxgraphen. |
| Schlüsselwörter (z. B. CREATE) werden
in Großbuchstaben, die anderen Angaben in Kleinbuchstaben geschrieben;
Variable für Schlüsselwörter (z. B. KEYWORD_ 1)
werden durch kursive Großbuchstaben, die anderen Variablen durch kursive
Kleinbuchstaben dargestellt. Hier die Basiskonstrukte der Metasprache:
|
|
|
|
Dies ist ein einzelnes Schlüsselwort in der syntaktischen Beschreibung, z. B. CREATE. Das Schlüsselwort muss von jedem anderen Schlüsselwort oder Parameter durch mindestens ein Leerzeichen oder einen Tabulatorstop getrennt sein. |
|
|
Dies bedeutet ein Schlüsselwort, gefolgt von einer Kette, die durch mindestens ein Leerzeichen voneinander getrennt sind |
|
|
Verzweigte Linien zeigen alternative Konstruktionen an. Bei einem Durchgang kann nur einer der hier beiden Wege verfolgt werden. Entweder wird option _1 oder option _2 ausgeführt. Dieses Diagramm kann beliebig um weitere options ergänzt werden. |
|
|
Dies repräsentiert eine Liste von Parametern, d.h. die Schleife wird beliebig oft durchlaufen. Wenn mehr als ein Parameter auftritt, sind diese durch Komma zu trennen. Wenn ein Komma oder ein anderes Trennzeichen in einer Liste spezifiziert ist, müssen zwischen den Elementen der Liste Leerzeichen nicht auftreten. |
|
|
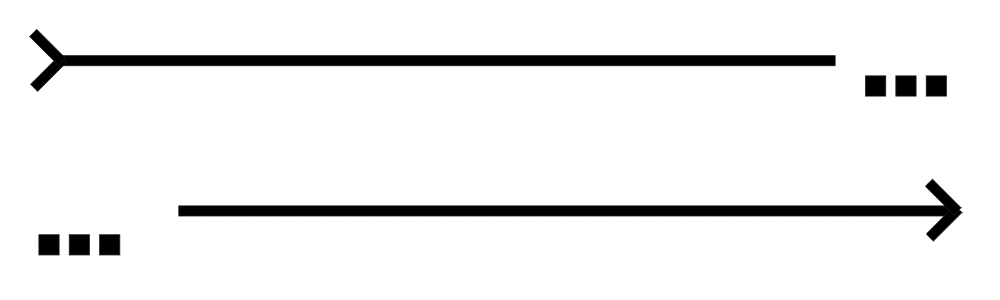
Drei Punkte am Anfang einer Zeile im Diagramm zeigen an, dass die Zeile eine Fortsetzung der vorhergehenden Zeile ist. |
|
|
Drei Punkte am Ende einer Zeile im Diagramm zeigen an, dass die Zeile eine Fortsetzung auf der folgenden Zeile hat. |
|
|
Pfeilspitzen am Anfang und Ende einer syntaktischen Konstruktion, die über beliebig viele Zeilen notiert sein kann, zeigen an, dass das Konstrukt eine Komponente einer umfassenderen Konstruktion ist und allein nicht verwendet werden kann. Die Pfeilspitzen sind nicht Teil der Statementsyntax. |
|
|
Linien ohne Pfeilspitzen oder ohne Punkte am Anfang oder Ende eines Diagramms, das über beliebig viele Zeilen notiert sein kann, zeigen an, dass das Statement dort beginnt oder endet. Fortsetzungszeilen sind durch drei Punkte gekennzeichnet. |
|
|
Erläuterungen
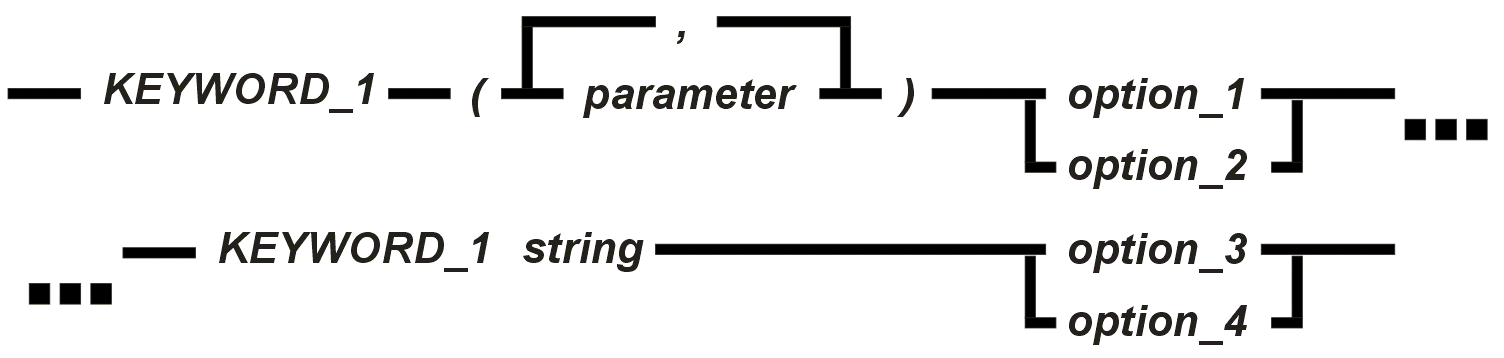
Erläuterung: Das Konstrukt stellt ein vollständiges Statement dar. Hinter KEYWORD_1 müssen ein oder mehrere parameter stehen, die in runde Klammern einzuschließen und durch Kommas zu trennen sind. Es folgt danach option_1 oder option_2, danach das KEYWORD_2, gefolgt von einem string (Trennzeichen mindestens ein Leerzeichen). Schließlich ist das Statement beendet oder es folgt option_3 oder option_4. |
| 2. Basiskonstrukte der Standard SQL |
|
|
|
| 3. Identifer, Operatoren und Funktionen |
|
|
|
|
|
Konsistenz garantiert Widerspruchsfreiheit. Niemals - auch nur kurzzeitig gibt es den Zustand, in welchem die Inhalte relational miteinander verknüpfte Tupel einander widersprechen. Idealerweise organisiert dies das DBMS selbst oder überwacht zumindest die konsequente Einhaltung selbiger. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Identifier sind Bezeichner (Namen) für die verschiedenen Objekte eines DBMS.
Im allgemeinen gilt, dass Identifier, die das Betriebssystem des Rechners
erkennen muss, an dessen Konventionen gebunden sind und meistens 8 Zeichen
lang sein können, während Identifier, die das DBMS erkennen muss, größere
Längen gestatten, z. B. 18 Zeichen bei den meisten DBMS, aber bei MS-ACCESS
bis zu 64 Zeichen. Identifier müssen i. allg. mit einem Buchstaben beginnen
und können danach Buchstaben oder Ziffern sowie das Unterstreichunszeichen
('_') enthalten. Dabei spielt es keine Rolle, ob Buchstaben am Rechner als
Groß- oder Kleinbuchstaben getippt werden, weil die meisten DBMS eine
automatische Konvertierung in Großbuchstaben vornehmen, manche (unter einem
UNIX-System) konvertieren auch in Kleinbuchstaben. Nicht konvertiert werden
jedoch Zeichenketten in Anführungszeichen. Das Passwort, in der Regel
maximal 8 Zeichen und minimal 4 Zeichen lang, muss jedoch so getippt werden,
wie es definiert ist und kann alle Zeichen in beliebiger Mischung enthalten;
es ist bei der Spezifikation in Hochkommas einzuschließen. Das Passwort
dient der geheimen Identifikation des Nutzers und wird zusammen mit dem
Nutzernamen verwendet, um Zutritt zum Datenbanksystem zu bekommen, falls
dieser unter diesen Identifikationsmerkmalen im System bekannt ist. Die
Tafel unten enthält die Angaben zu den in den SQL-Standards verwendeten
Identifier (es werden die englischen Typnamen beibehalten). Tafel Identifier-Übersicht
Für Identifier findet man auch den deutschen Begriff "Bezeichner" Anmerkung: In der Tabelle sind die Identifier mit einem Stern (") gekennzeichnet, die z. Z. nicht in allen hier betrachteten DBMS implementiert sind oder wo die Funktion auf andere Weise gegeben ist. In dem unter Windows laufenden DBMS MS-ACCESS gelten wesentlich erweiterte Längen, i. allg. bis zu 64 beliebige Zeichen, einschl. Leerzeichen. Leerzeichen sind normalerweise Trennzeichen. Um trotzdem Bezeichner, etwa der Form für einen Tabellennamen Tabelle der Studenten verwenden zu können, sind dann Bezeichner in Anführungszeichen zu setzen: "Tabelle der Studenten". |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Operatoren: Zur Arbeit mit einem DBMS sind folgende Operatoren erforderlich und, entsprechend dem Standard, mindestens in nachfolgend genannten Formen vorhanden.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
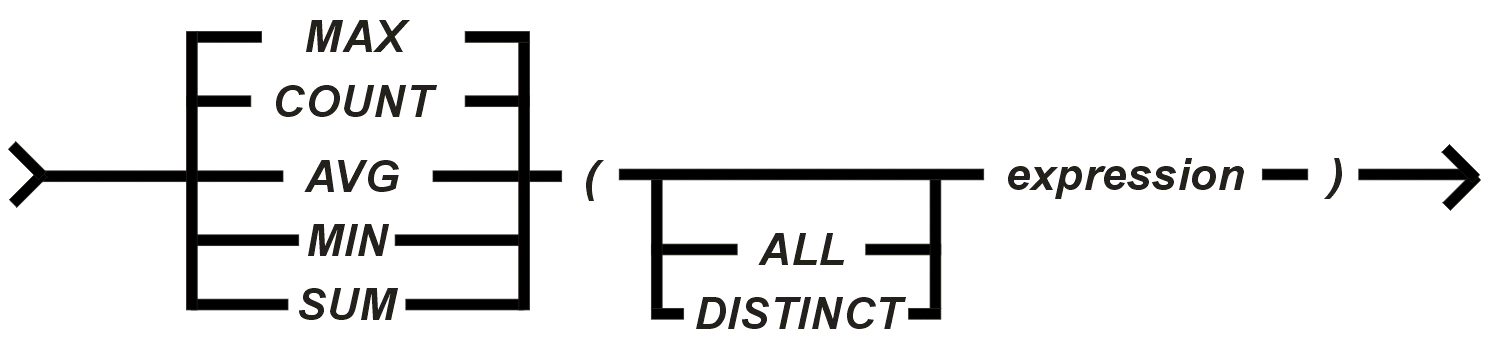
| Funktionen Vom Standard gefordert sind Set-Funktionen (Aggregat-Funktionen - auf Mengen angewendete und aggregierende Funktionen); teilweise gibt es weitere Funktionen dieser Art. Diese neueren Funktionen beziehen sich auf die Arbeit mit den Datentypen DATE, TIME bzw. DATETIME, auf die Steuerung der Konvertierung zwischen Datentypen, auf die Arbeit mit Zeichenketten, auf die Arbeit mit mathematischen Funktionen usw. Diese Erweiterungen gegenüber dem Standard sind im wesentlichen vom konkreten DBMS und den dort angebotenen Datentypen abhängig. Set-Funktionen (Aggregat-Funktionen) Das volle Verständnis dieser Funktionen wird später erreicht, nachdem
deren Anwendungen in anderen Konstrukten gezeigt worden ist. Manche DBMS unterstützen weitere Set-Funktionen, z.B. gewichtete Durchschnitte und gewichtete Summen, die sich auf jeweils zwei Spalten beziehen. Hier die allgemeine Syntax der Set-Funktionen:
Erläuterung:
Für die Set-Funktionen MAX und
MIN ist das Schlüsselwort
DISTINCT irrelevant und sollte bzw. muss vermieden werden. Sonstige Funktionen Insbesondere für die Datentypen TIME,
DATE und DATETIME, aber
auch für den Datentyp Zeichenkette gibt es, in den DBMS unterschiedlich
implementiert, eine Anzahl weiterer Funktionen. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4. Basiskonstrukte |
|
|
|
|
|
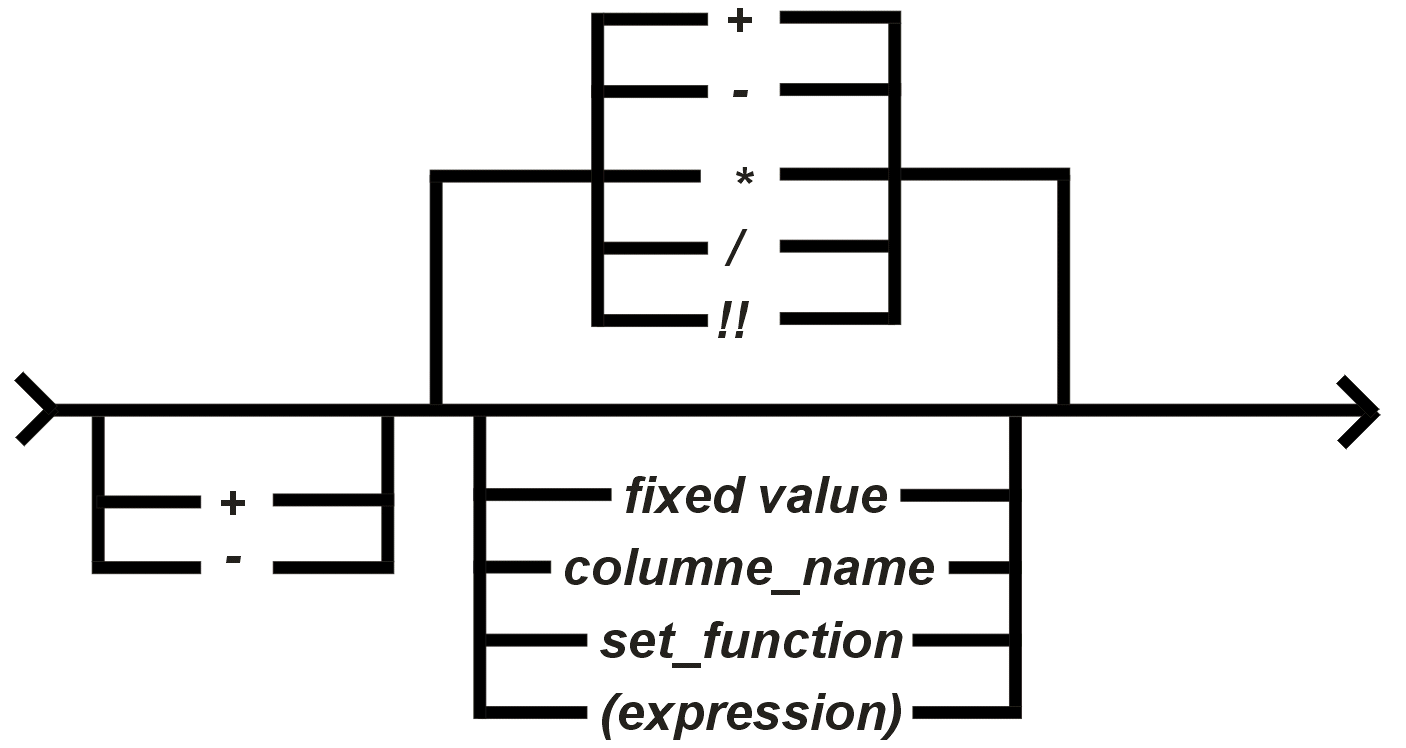
In SOL werden Ausdrücke in den verschiedensten Zusammenhängen verwendet, z. B. in Suchbedingungen (search conditions) und in der SET-Klausel eines UPDATE-Statements. Ein Ausdruck liefert immer einen einzelnen Wert. |
|
Erläuterung: fixed_value (Festwert, Konstante),
column_name (Spaltenname),
set
function (Mengenfunktion) und (expression) (rekursiv verwendet, d. h.
Funktion in Funktion eingesetzt) sind die Operanden des Ausdruckes. Beispiel: ... mitarb_gehalt * 1.2 .. |
|
|
Das Basisprädikat Wir erinnern
daran, dass der Begriff Prädikat im mathematisch-logischen Sinne zu
verstehen ist.Prädikate sind bedingte Ausdrücke, die die Werte
TRUE (wahr), FALSE
(falsch) oder NULL (unbekannt) annehmen können.
Beachte: NULL ist der unbestimmte Wert, nicht die numerische Null! Ein
unbestimmter Wert zu einem bestimmten Wert addiert, ist natürlich wieder ein
unbestimmter Wert. Prädikate werden zur Bildung von Suchbedingungen in
WHERE-, HAVING- und
CHECK-Klauseln verwendet.
Beispiele:
name = 'Schulze' name, gehalt sind hier Spaltennamen; differenz ist ein numerischer Ausdruck; die Ergebnisse sind hier entweder wahr oder falsch! |
|
| Quantifizierte Prädikate Ein quantifiziertes Prädikat verwendet die Operatoren ALL, ANY oder SOME und vergleicht einen Ausdruck mit einer Wertemenge, die durch das spezifizierte Subselect erzeugt wird, d.h. es wird dann verwendet, wenn nicht nur auf einen einzigen Wert der Ergebnismenge, sondern auf alle (ALL) oder einige (ANY, alternativ SOME) von mehr als einem Wert verglichen werden muss.
Im Zusammenhang mit einem quantifizierten Prädikat muss das Subselect entweder eine leere Menge oder eine Menge von einzelnen Werten zurückgeben. Das Ergebnis ist wahr, wenn das Subselect eine leere Menge liefert oder
wenn der Vergleich für jeden Wert, der vom Subselect zurückgegeben wird,
wahr ist. Das ANY-Prädikat oder SOME-Prädikat: Die Schlüsselwörter ANY und
SOME sind äquivalent (synonym). |
|
| Die Prädikate IN, LIKE, BETWEEN, NULL, EXISTS Diese Prädikate gestatten in vielen Fällen eine wesentlich komprimiertere Schreibweise; sie sind teilweise unverzichtbar zur Formulierung bestimmter Abfragebedingungen. Dieses Prädikat testet Ergebnisse, ob ein Wert (einer kontinuierlichen, zusammenhängenden Menge) innerhalb eines Bereiches von Werten, die Grenzen eingeschlossen, liegt oder nicht.
Das BETWEEN-Prädikat ist eine verkürzte Schreibweise für die direkte Angabe mit Basisprädikaten:
Das Ergebnis des BETWEEN-Prädikates ist unbestimmt, wenn die äquivalenten Basisprädikate ein unbestimmtes Ergebnis liefern. Beispiel: gehalt BETWEEN 1500.00 AND 2300.00 Dieses Prädikat testet, ob ein Wert in einer Menge diskreter Werte enthalten ist oder nicht.
Wenn die Menge der Werte auf der rechten Seite des Vergleichs als eine explizite Liste gegeben ist, kann das IN-Prädikat immer durch eine Menge von Basisprädikaten ausgedrückt werden, die durch die logischen Operatoren AND oder OR verbunden sind:
Wenn die Menge der Werte durch ein Subselect zurückgeben wird, ist ein IN-Prädikat äquivalent zu einem quantifizierten Prädikat:
<> ist hier verwendet worden als Schreibweise für ungleich. Beispiel:
Ausgewählt werden die Wohnorte mit den Namen Leipzig, Dresden oder Chemnitz. Das LIKE-Prädikat vergleicht den Wert eines Zeichenkettenausdruckes mit einem Zeichenkettenmuster (als fixed_value - Konstante), das i. allg. sogenannte Joker-Symbole oder Wildeards (als Platzhalter) enthält.
Der Ausdruck auf der linken Seite des LIKE-Operators muss ein Kettenausdruck sein. Der Festwert auf der rechten Seite ist eine Kettenkonstante oder eine Hostvariable (ESQL) oder das Schlüsselwort USER. Es können folgende Jokersymbole verwendet werden:
Beispiele:
Das NULL-Prädikat vergleicht den Wert einer Spalte mit dem NULL-Indikator; es bietet in einem dem Standard entsprechenden DBMS die einzige Möglichkeit, auf unbestimmte Werte zu testen.
Wenn das Prädikat 'expression
IS NULL'
spezifiziert ist, dann ist das Ergebnis wahr, wenn irgendein Operand des
Ausdruckes NULL ist. Das Ergebnis ist falsch, wenn kein Operand im Ausdruck
NULL ist. Das Ergebnis des
NULL-Prädikates ist niemals unbekannt. Beispiel:
Das EXISTS-Prädikat prüft, ob die Menge von Werten, die durch ein Subselect zurückgegeben wird, leer ist oder nicht.
Das Ergebnis ist wahr, wenn das Subselect
nicht die leere Menge zurückgibt. Sonst ist das Ergebnis falsch. Eine Menge
von ausschließlich NULL-Werten ist nicht leer. Deshalb ist das Ergebnis
niemals unbekannt. Beispiel: EXISTS (SELECT* FROM mitarb WHERE kinder > 5) - das Ergebnis ist falsch, weil kein Mitarbeiter in der Tabelle MITARB mehr als 5 Kinder hat. Für die Auswahl ist nur die
WHERE-Klausel
relevant. Die Spalten sind irrelevant.
|
|
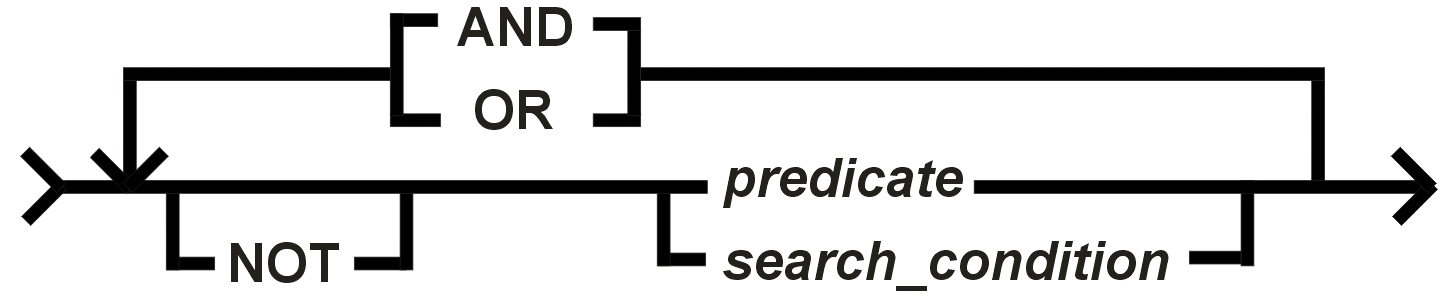
| Suchbedingungen
Suchbedingungen (search_conditions) werden in
WHERE- und HAVING-Klauseln von
SELECT-Statements und Subselects verwendet, um die Zeilen in Tabellen Views
bzw. Gruppen zu selektieren, sowie in CHECK-Klauseln, um zulässige Werte zu
definieren.
Erläuterung: predicate steht für irgendeines der eben behandelten Prädikate. (search condition) steht für die rekursive Verwendung, d. h., es können beliebig komplexe Suchbedingungen schrittweise aufgebaut werden. Sind Konstruktionen mit mehreren AND, OR oder NOT zu bilden, so kann man die Auswertung mittels runder Klammern steuern. Das entspricht im Prinzip der Arbeit mit Klammern in arithmetischen Ausdrücken. Hier werden Bedingungen in runden Klammern zuerst ausgewertet, auf gleicher Klammerebene wird NOT vor AND und AND vor OR angewendet. Beispiel für die Bedingung in einer WHERE-Klausel: Es sollen diejenigen Zeilen aus der Tabelle MITARB ausgewählt werden, für die der Mitarbeiter mehr als 2 und weniger als 5 Kinder hat, in der Abteilung KON1 arbeitet, verheiratet ist und das Gehalt zwischen 2000 und 3000 (einschließlich) liegt oder der Mitarbeiter eine Postleitzahl hat, die mit 0 beginnt. Lösung: WHERE kinder > 2 AND kinder < 5 AND abtnr =
'KON1' AND famst = 'V' WHERE- und HAVING-Klauseln suchen die Menge von Werten, für die die Suchbedingung wahr ist. In CHECK-Klauseln von DOMAIN-Statements definieren Suchbedingungen die Menge von Werten, für die die Bedingung nicht als falsch berechnet wird, also entweder wahr oder unbekannt ist. |
| 5. Subselects |
|
|
|
|
|
Das
Konstrukt Subselect wird vor allem in SELECT-Statements, aber auch in vielen
anderen Statements (INSEKT, UPDATE, DELETE, CREATE VIEW) als Komponente
(Substruktur) verwendet. Das Subselect ist ein sehr komplexes Konstrukt; es
hat folgende Klauseln: notwendig SELECT-Klausel |
||||||||||||||||||||||||||||||||||||||||||
|
Die SELECT-Klausel Mit der SELECT-Klausel des Subselects wird spezifiziert, welche Werte selektiert werden sollen; es wird die relationale Operation Projektion ausgeführt. Werte werden durch Angabe der Spaltennamen oder durch Ausdrücke spezifiziert, wie im Diagramm zu sehen ist.
Erläuterung: Die
SELECT-Klausel ist sehr komplex und formal schwer beschreibbar und
durchschaubar. Es folgen deshalb zu jeder Alternative Beispiele, die sich
auf die Beispieldatenbank FEDB beziehen. SELECT table reference.* table_reference (Tabellenbezugnahme) ist in diesem Falle der Name einer Tabelle oder View. Es werden alle Spalten der durch table_reference angesprochenen Tabelle oder View ausgewählt, und zwar in der Reihenfolge ihrer Definition in CREATE TABLE- oder CREATE VIEW-Statements. Meistens wird diese Form kombiniert verwendet, wenn mehrere Tabellen/Views angesprochen werden. SELECT table reference.column name, ... Wie vorgenannt, jedoch werden nur die Spalten (über die Spaltennamen) ausgewählt, die in der Liste der SELECT-Klausel enthalten sind. Beispiel: SELECT mitarb.*, ... Im Beispiel
werden aus der Tabelle MITARB alle Spalten in der Reihenfolge der
Tabellendefinition zurückgegeben. Wird anstelle des Tabellennamens (MITARB)
die Form correlation name (zu übersetzen
etwa mit "verbundener Name") verwendet, so muss dieser in der
FROM-Klausel definiert werden (d. h. an den
Tabellennamen gebunden werden, s. u.). SELECT ....expression,
... Beispiel: SELECT name, gehalt * 1.2 neues_gehalt Im Ergebnis dieser Abfrage entstehen zwei Spalten mit den Spaltenbezeichnungen NAME NEUES_GEHALT Die Spaltenwerte enthalten die Namen sowie das mit 1.2 multiplizierte Gehalt; Name und Gehalt sind Werte aus der Tabelle MITARB. Der Ausdruck gehalt * 1.2 wird in der Ergebnistabelle mit der Spaltenbezeichnung NEUES_GEHALT ausgegeben. |
|||||||||||||||||||||||||||||||||||||||||||
|
Die Schlüsselwörter ALL und
DISTINCT Wird ALL spezifiziert
oder ist kein Schlüsselwort angegeben, werden die gewünschten Spaltenwerte
aus allen Zeilen zurückgegeben, d. h., Duplikat-Zeilen werden aus dem
Ergebnis eines Subselect nicht eliminiert. Wenn DISTINCT
spezifiziert ist, werden Duplikat-Zeilen eliminiert; Mehrfachwerte werden
nur einmal berücksichtigt.
Beispiele: SELECT distinct abtnr liefert, bezogen auf die Tabelle MITARB, die Übersicht über alle in der Tabelle vorkommenden Abteilungsnummern, wobei jede ABTNR nur einmal in der Ergebnistabelle vorkommt: KON1, KON2, KON3, FE1, FE2, RZ SELECT abtnr liefert, bezogen auf die Tabelle MITARB so viele Zeilen mit ABTNR, wie Zeilen selektiert werden - in der Regel ein unerwünschtes Ergebnis. |
|||||||||||||||||||||||||||||||||||||||||||
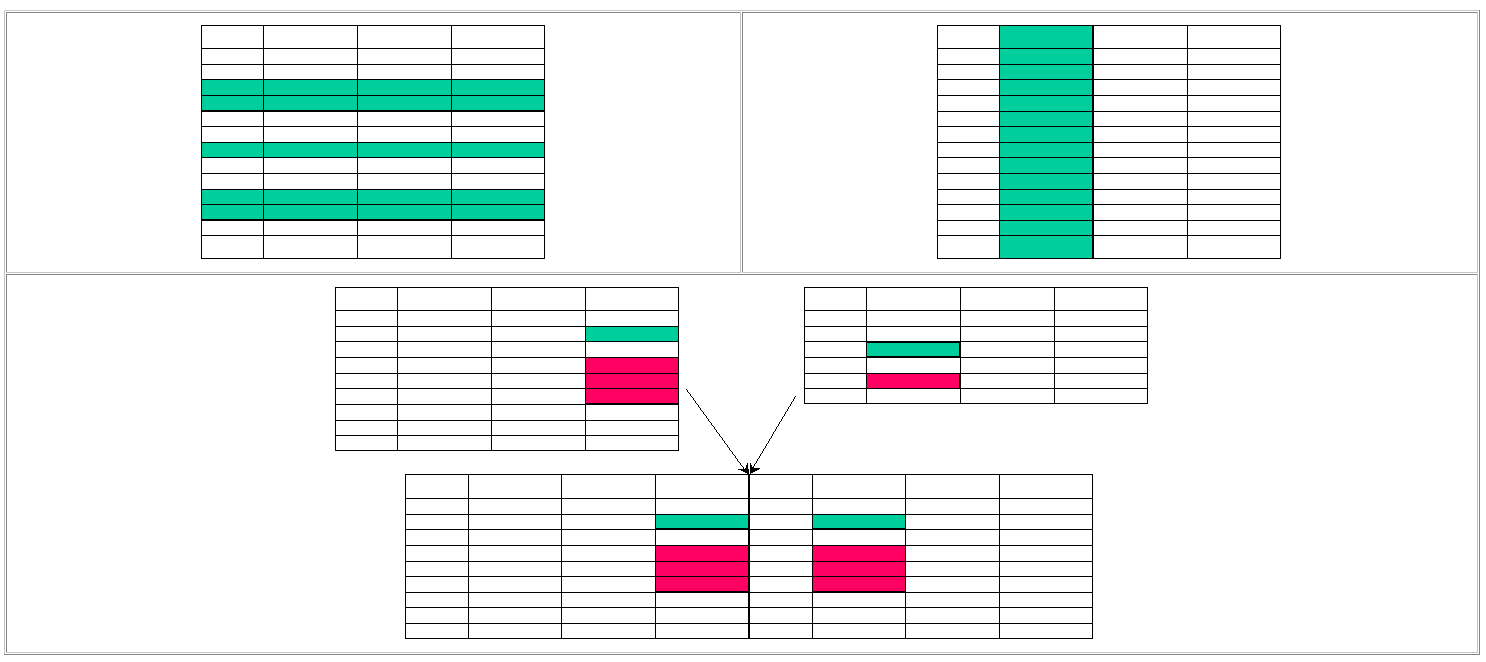
|
Die FROM-Klausel Die FROM-Klausel definiert eine Zwischenergebnismenge (Diese ist für den Nutzer nicht sichtbar (transparent); sie existiert im Rechner nur für Zwecke der weiteren Berechnung) für das Subselect. Sie kann correlation-names für die Tabellenbezugnahmen spezifizieren, die in der Ergebnismenge verwendet werden. D. h., einer Tabelle oder View wird ein (kürzerer) weiterer Name zugeordnet.
Erläuterung: Alle Basistabellen und Views, die in der SELECT-Klausel angesprochen werden, müssen in der FROM-Klausel notiert werden. Adressiert die table_reference eine View, deren Definition eine GROUP BY-Klausel enthält, darf keine weitere Tabelle oder View spezifiziert werden. Das Schlüsselwort AS ist in vielen DBMS nicht möglich. Es wird in den Beispielen weggelassen. Dies sind alternative Namen für table_references,
die nur in dem Statement bekannt sind, wo sie definiert wurden. Werden
mehrere correlation names erforderlich, so ist für die be¬treffende
table_reference die Konstruktion entsprechend oft zu spezifizieren.
Vergleiche das folgende Beispiel 1. Um die Schreibweise abzukürzen (dies ist wahlweise zu verwenden und dient der "Bequemlichkeit"). Beispiel: SELECT mp.mnr, mp.pnr, m.mnr FROM mitpro mp, mitarb m ... Erläuterung: Mit MP wird die Tabelle MITPRO, mit M die Tabelle MITARB angesprochen. Bei komplizierten Abfragen gibt dies ersichtlich wesentliche Einsparungen an einzugebendem Text, und die Gefahr der fehlerhaften Eingabe (bei langen Namen) ist wesentlich verringert. Die obige verkürzte Form ist identisch mit SELECT mitpro.mnr, mitpro.pnr, mitarb.mnr FROM mitpro, mitarb .. In beiden Schreibweisen ist die noch nicht erklärte WHERE-Klausel weggelassen worden, die in der Regel erforderlich ist, weil zwei Tabellen angesprochen werden. 2. Um eine Tabelle auf sich selbst beziehen zu können (dann logisch zwingend erforderlich). Beispiel: Hierzu wählen wir eine andere Datenbasis aus dem Bereich Konstruktion mit den Tabellen STLIST (Stückliste) und PBEZ (Produktbezeichnung). Struktur der Tabelle STLIST3
Struktur der Tabelle PRODUKT
Gesucht sind die Produktnummern (PNRO) und Namen (PBEZ) aller oberen Produkte und die Produktnummern (PNRU) und Namen (PBEZ) der in das obere Produkt eingehenden unteren Produkte sowie die direkt eingehenden Stücke (ANZD)! Sind aus Gründen der Logik mehrere correlation_names erforderlich, so können sie wie in folgendem Beispiel vereinbart werden. Im Beispiel wird gleichzeitig die verkürzte Schreibweise verwendet. Lösung: SELECT s.pnro, p.pbez, s.pnru, pl.pbez,
s.anzd Die Verwendung der WHERE-Klausel wird im folgenden Abschnitt erklärt. Lesen Sie zunächst dort nach, und kehren Sie dann zu diesem Beispiel zurück. 3. Bei der Verwendung genesteter Subselects (auch logisch zwingend erforderlich)'. Beispiel: SELECT name FROM mitarb m Im Beispiel wird der Tabelle MITARB ein (logisch notwendiger) weiterer Name zugeordnet, der in der Subselect-Konstruktion nach EXISTS verwendet wird. MNR im Subselect ist die Mitarbeiternummer in der Tabelle MITPRO (eine besondere Qualifizierung dieser Spalte mit MITPRO ist lt. Definition nicht erforderlich). M.MNR ist die Mitarbeiternummer in der Tabelle MITARB, angesprochen über den zugeordneten Namen M. In der WHERE-Klausel des Subselects werden die Mitarbeiternummern beider Tabellen (MITARB und MITPRO) auf Gleichheit verglichen. |
|||||||||||||||||||||||||||||||||||||||||||
|
Die WHERE-Klausel Durch die WHERE-Klausel wird eine Untermenge Zeilen aus der Zwischenergebnismenge ausgewählt; es wird die relationale Operation Selektion (Restriktion) ausgeführt. Die Auswahl erfolgt auf der Basis von Spaltenwerten in Form einer Suchbedingung für diese Werte. Ist eine WHERE-Klausel nicht spezifiziert, werden alle Zeilen der Zwischenergebnismenge ausgewählt. In der WHERE-Klausel wird auch die relationale Operation Join realisiert. Wie wir sehen werden, können in einer WHERE-Klausel gleichzeitig Bedingungen für eine oder mehrere Selektionen und einen oder mehrere Joins formuliert werden.
Auch genestete Subselects sind komplizierte Formen von Abfragen, die Sie
beim ersten Durchgehen des Stoffes übergehen können. Die richtige
Spezifizierung genesteter Subselects ist vom Anfänger nicht zu erwarten.
Sie sollten aber wissen, dass Sie in SQL viel kompliziertere Abfragen
formulieren können, wozu oftmals Notwendigkeit besteht. Beispiel: Suche alle Zeilen, für die die ABTNR gleich RZ und das Gehalt kleiner oder gleich 2500 ist! ... WHERE abtnr = 'RZ' AND gehalt <= 2500 ... Die WHERE-Klausel hat, wie einleitend oben gesagt, zwei Funktionen:
|
|||||||||||||||||||||||||||||||||||||||||||
|
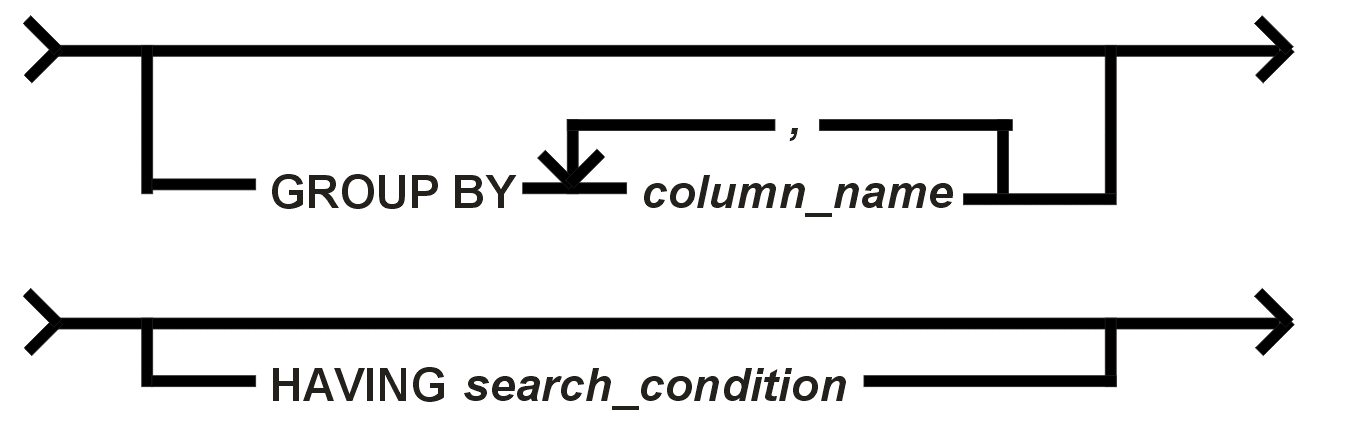
Die GROUP BY-Klausel und die
HAVING-Klausel Die GROUP BY-Klausel bestimmt die Gruppierung der Ergebnistabelle, um in der spezifizierten SELECT-Klausel Set-Funktionen anwenden zu können. Die HAVING-Klausel beschränkt die Zeilenauswahl in Gruppen in gleicher Weise wie die WHERE-Klausel in Tabellen oder Views. Beide Teiloperationen eines Subselects (Select-Statements) sind für den Anwender transparent, d. h. nicht zu sehen. Sie erzeugen rechnerintern die für die Gesamtbearbeitung erforderlichen Zwischenergebnisse. Überprüfen Sie auf jeden Fall die Operationen dieser Klauseln an selbst gewählten Beispielen! Die Operation des Gruppierens ist dem Lernenden wahrscheinlich aus konventionellen kaufmännischen Anwendungen (z. B. auf der Basis der Programmiersprachen PL/1 oder COBOL) bekannt.
Es handelt sich hier um eine Suchbedingung mit der Operation
AND auf der Tabelle MITARB
Die auszuwählenden Zeilen beziehen sich auf solche, deren Mitarbeiter in der
Abteilung RZ arbeiten und die weniger oder gleich
2500 DM verdienen. - Warum steht
RZ in Hochkommas 2500
jedoch nicht? Beispiele: Beispiel 1 Für die Tabelle MITARB sind die Maximal-, Minimal- und Durchschnittsgehälter für alle Mitarbeiter zu bestimmen! Für die Ergebnistabelle sind die alternativen Namen Maximalgehalt, Minimalgehalt und Durchschnittsgehalt zu verwenden! SELECT MAX(gehalt) Maximalgehalt; MIN(gehalt) Minimalgehalt, AVG (gehalt)
Durchschnittsgehalt Ergebnis:
Hätte man
keine alternativen Namen spezifiziert, so würden die Spaltenbezeichnungen
der Ergebnistabelle, abhängend vom konkret verwendeten DBMS, z. B.
MAX( ),
MIN( ), AVG( ) lauten. Beispiel 2 Zu bestimmen ist für jede Abteilung das Maximalgehalt, Minimalgehalt und Durchschnittsgehalt. Das Ergebnis ist nach ABTNR aufsteigend zu sortieren! Es sind alternative Namen zu verwenden!
SELECT abtnr Abteilungsnummer, MAX(gehalt)
Maximalgehalt, MIN(gehalt) Minimalgehalt, AVG(gehalt) Durchschnittsgehalt
FROM mitarb
Das Ergebnis besteht aus so vielen Zeilen, wie es verschiedene Abteilungsnummern gibt - die Ergebnistabelle enthält für jede Gruppe eine Zeile mit den angegebenen, durch Set-Funktionen berechneten Werten. Die Spaltenüberschriften entsprechen den spezifizierten Zeichenketten nach den Spaltennamen bzw. Ausdrücken. Gegen die letzte Zeile - hier: 6 row(s) retrieved - haben Sie bitte keinen Einwand; dies ist im DBMS so implementiert, und dies sind meistens US-amerikanische Entwicklungen. Mit diesen englischen Begriffen müssen Sie sich noch Jahre abfinden. Im übrigen gewöhnt man sich schnell an die englisch-basierte Fachsprache der EDV. |
| 6. Statemaents zur Metadaten-Definition |
|
|
|
|
|
Die Statements dieser Gruppe
erzeugen die Objekte der Datenbasis. Hierzu gehört auch die Erzeugung der
Datenbasis selbst. Die Metadaten beschreiben die Datenbasis in dem für die
effektive Arbeit auf der Datenbasis erforderlichen Maße. Sie sind im Data
Dictionary (DD) gespeichert. Entsprechend den allgemeinen Anforderungen bei
der Arbeit mit Daten sind Statements zum Erzeugen, Verändern und Löschen
notwendig. Die Statements zum Definieren der Datenbasis sind: CREATE SCHEMA, CREATE DATABANK, CREATE IDENT, CREATE INDEX, CREATE SYNONYM, CREATE TABLE, CREATE VIEW, CREATE DOMAIN Statements zur Änderung der Datenbasis sind: ALTER DATABANK, ALTER IDENTS, ALTER TABLE. Statements zum Löschen von Objekten sind die DROP-Statements entsprechend den CREATE-Statements. Weiterhin gibt es noch das nützliche COMMENT-Statement, das den Datenbankobjekten Informationen zuordnet. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Das Data Dictionary (DD) eines modernen DBMS ist eines seiner zentralen Steuereinrich-tungen. Das DD enthält alle Informationen über die Daten und seine Nutzer (Metadaten). In der Form des heute üblichen aktiven DD dient es nicht nur zur Information des Nutzers, sondern vielmehr der unmittelbaren Steuerung der Arbeit mit dem DBMS. Das DD besteht aus einer Anzahl vordefinierter (System-) Tabellen, d. h. es verwendet die Möglichkeiten das relationalen DBMS zur eigenen Steuerung. Beispiel:
Bestrebungen zur Standardisierung von DD waren bisher wenig erfolgreich,
bedingt hauptsächlich durch die Unterschiede in den Architekturen der DBMS und
der zum Standard zusätzlich implementierten Funktionen und Statements. Die
Tabellen des Data Dictionary sind bei den meisten DBMS normale Tabellen. Beispiel (Data Dictionary von MIMER): Das DD von MIMER enthält 26 Systemtabellen, z. B. die folgenden (Tafeln 1 bis 4). (Analysieren Sie diese Tafeln nach ihren Inhalten und versuchen Sie, deren Inhalte in einem Trockentest zu nutzen!): Tafel 1 COLUMN-View
Tafel 2 DOMAINS-View
Tafel 3 Systemtabelle IDENT_PRIVS-View
Tafel 4 Systemtabelle INDEXES-View
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
CREATE-Statements
Vom Standard wird ein Statement CREATE SCHEMA gefordert. Bei der
Schemadefinition sind die Datenbank, ihr "Eigentümer" und die in ihr enthaltenen
Tabellen und Views festzulegen. Dieses Statement wird z. Z. konsequent in keinem
der bekannten DBMS realisiert. In INFORMIX gibt es jedoch ein Schema-Menü zur
Erzeugung der Datenbank und der Tabel¬len. In anderen DBMS wird diese Funktion
anders gelöst.
Man erkennt, dass ein Schema aus einer CREATE SCHEMA-Klausel, einer AUTHORIZATION-Klausel und beliebig vielen (auch Null) CREATE TABLE-Definitionen und/oder beliebig vielen View-Definitionen und /oder beliebig vielen Grant-Operationen besteht. Die AUTHORIZATION-Klausel identifiziert den Eigentümer jeder Basistabelle und/oder View, die in diesem Schema definiert ist. Erzeugt ein Nutzer-, Programm- oder Gruppenident; in ISQL und ESQL gleich verwendete. Syntax:
Beschreibung: Ein neues Ident wird erzeugt. Ist das Ident ein Nutzer oder ein Programm, wird auch das Password vergeben. Beschränkungen: CREATE IDENT erfordert das Ident-Privileg für das vergebende Ident. Hinweise:
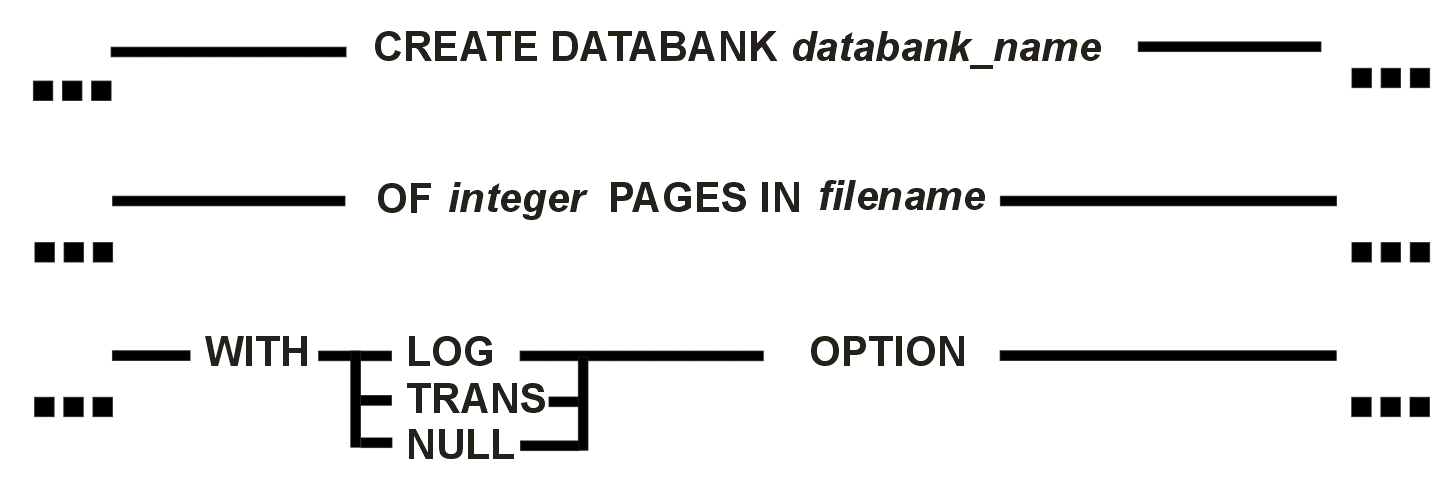
Beispiele: CREATE IDENT fe_sub dba AS USER IDENTIFIED BY 'sub*dba@'; CREATE IDENT fe db AS GROUP; Erzeugt eine neue Datenbank; wird in ISQL und ESQL mit gleicher Syntax verwendet. Teils in den DBMS auch als CREATE DATABANK verfügbar; evtl. syntaktisch anders gelöst - implementationsabhängig. Die Manuals der konkreten Systeme sind zu beachten!
Beschreibung: Das Statement erzeugt eine neue Datenbank, die zur Aufnahme von Tabellen und Indextabellen vorbereitet ist; die Systemtabellen des Data Dictionary werden erzeugt. Das Statement in der obigen Syntax existiert z. B. in MIMER V5 und hat einen Teil der Funktionen des CREATE SCHEMA-Statements des SQL-Standards. Dieses Statement stellt u. a. die Verbindung mit dem Betriebssystem des Rechners her und ist deshalb an externe und weitere firmeneigene Bedingungen gebunden. Der Standard wird in der Regel nicht voll zugrunde gelegt.
Beschränkungen: Das CREATE DATABANK-Statement erfordert DATABANK-Privileg,. Hinweise:
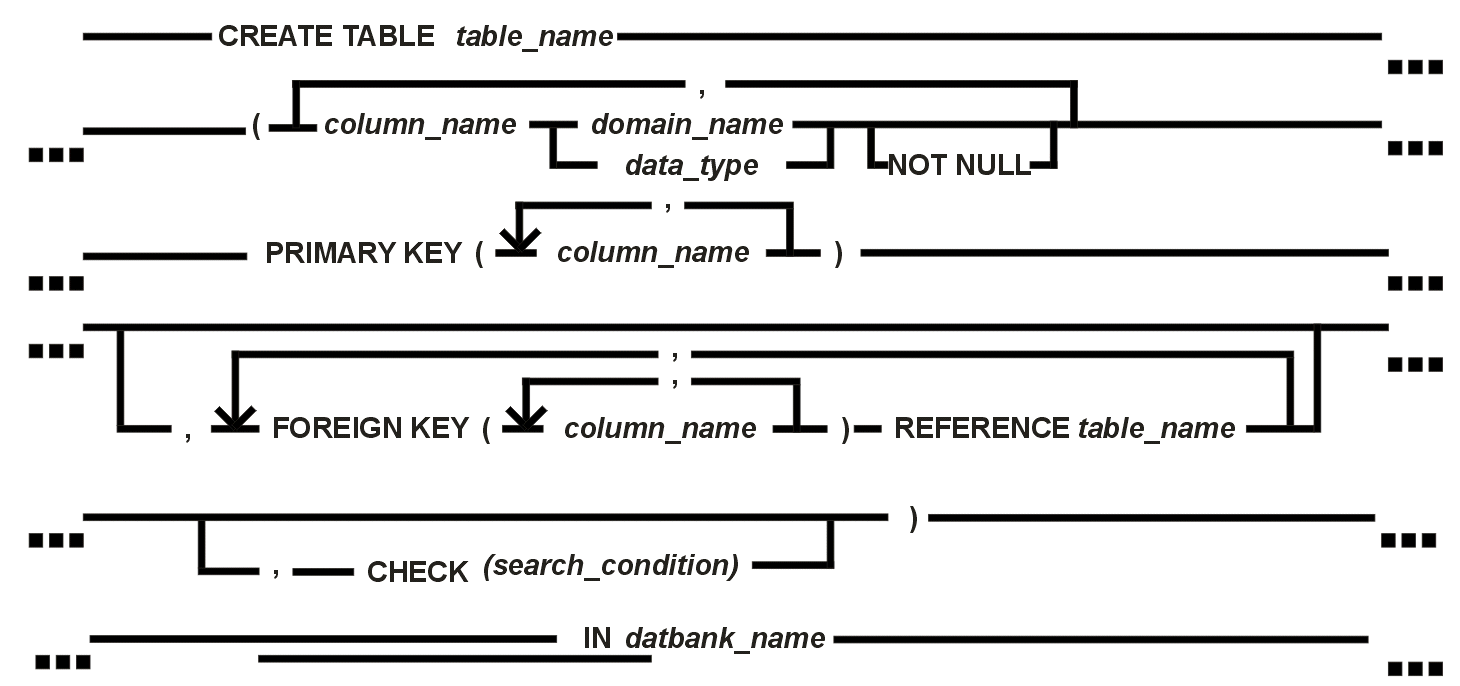
Beispiel: CREATE DATABANK fedb OF 100 PAGES IN 'FEDB.DBF' Zu lesen ist dieses Statement wie folgt: Erzeuge eine Datenbank FEDB mit 100 Seiten (rechnerabhängige Seitengröße beachten), gespeichert im File FEDB.DBF; es wird keine Transaktionensteuerung verwendet, und die Arbeit auf der Datenbank wird nicht protokolliert. CREATE TABLE erzeugt eine neue Tabelle; in ISQL und ESQL gleich verwendet. Evtl. sehen Sie sich zuerst das Beispiel am Ende dieses Abschnitts an. Syntax:
Beschreibung: Es wird eine neue Tabelle in derjenigen Datenbank erzeugt, die in der
IN-Klausel spezifiziert ist. Die Tabelle weist lediglich die definierte Struktur
auf und ist solange leer, bis Daten eingegeben werden. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
zur Hauptseite |
© Samuel-von-Pufendorf-Gymnasium Flöha | © Frank Rost am 30. März 2009 |
|
... dieser Text wurde nach den Regeln irgendeiner Rechtschreibreform verfasst - ich hab' irgendwann einmal beschlossen, an diesem Zirkus nicht mehr teilzunehmen ;-) „Dieses Land braucht eine Steuerreform, dieses Land braucht eine Rentenreform - wir schreiben Schiffahrt mit drei „f“!“ Diddi Hallervorden, dt. Komiker und Kabarettist |







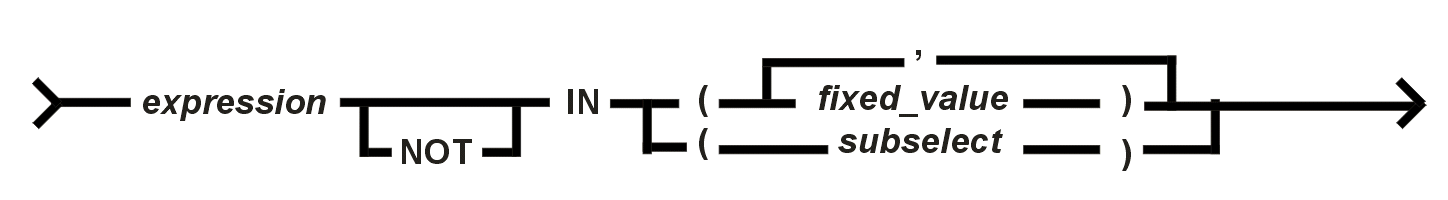
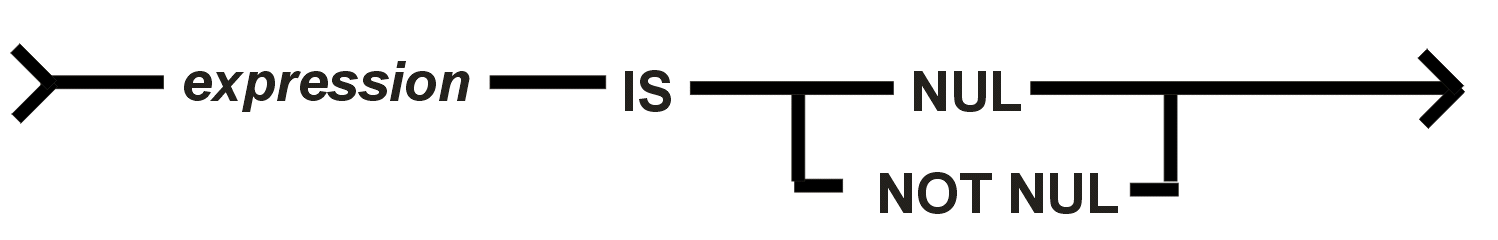



{kind=link}