| 6.1. Mengentheoretische Grundlagen der SQL - Codd'sches Relationenmodell |
|
|
Letztmalig dran rumgefummelt: 05.11.25 17:26:18 |
|
Das Relationenmodell der Datenbanktechnologie
nach Codd (kurz: COdd'sches Relationen Modell). Codd war das jüngste von sieben Kindern eines Lederers und einer Lehrerin. Er studierte am Exeter College der Universität Oxford Mathematik und Chemie. Im Zweiten Weltkrieg war er bei der Royal Air Force und erhielt in den USA Flugunterricht. 1948 siedelte er in diese über. Er war kurz Lehrbeauftragter für Mathematik an der University of Tennessee und arbeitete ab 1949 als mathematischer Programmierer in der New Yorker Zentrale von IBM, wo er zunächst für den Selective Sequence Electronic Calculator programmierte und dann das Multitasking-Konzept für den IBM 7030 Stretch entwickelte. Er promovierte 1965 mit einem IBM-Stipendium an der University of Michigan und wechselte 1967 an das IBM Almaden Research Center in San José. Codd schuf in den 1960er und 1970er Jahren das relationale Modell, das die Grundlage der relationalen Datenbanken ist, die bis heute einen Standard der Datenbanktechnik darstellen. Dabei war er wesentlich beteiligt an der Entwicklung des Systems R. Es ist (neben Ingres) der erste Prototyp eines relationalen Datenbankmanagementsystems und verwendete die Abfragensprache SEQUEL (Structured English Query Language), aus der die SQL-Abfragesprache hervorging. Auf System R basieren auch die späteren IBM-Produkte SQL/DS und DB2 sowie die Datenbank Oracle. Mit Raymond F. Boyce entwickelte Codd auch die Boyce-Codd-Normalform. Er formulierte auch zwölf Evaluierungsregeln als Anforderungsliste an ein Online-Analytical-Processing-System (OLAP). 1984 zog sich Codd von IBM zurück, und gründete mit Chris J. Date die Codd and Date Consulting Group, in der er bis 1999 als Berater tätig war. Für seine fortwährenden Arbeiten auf dem Gebiet der Datenbanken erhielt Codd 1981 den Turing Award, der als höchste Auszeichnung in der Informatik gilt. 1974 wurde er Fellow der British Computer Society, 1976 IBM Life Fellow. Codd war zweimal verheiratet und hatte vier Kinder. |
|||||||
|
1. Allgemeines zu Relationalen Modellen nach Codd 2. Basiskonstrukte 3. Identifer, Operatoren und Funktionen 4. Basiskonstrukte 5. SUBSELECTS 6. Statements für Metadaten 7. Logische Prädikate 8. Subqueries 9. HAVING-Klausel 10. GROUP BY |
|||||||
|
|||||||
|
|
Quellen:
|
||||||
|
|
|
||||||
|
|
Die Mengenlehre ist ein grundlegendes Teilgebiet der Mathematik, das sich mit der Untersuchung von Mengen, also von Zusammenfassungen von Objekten, beschäftigt. Die gesamte Mathematik, wie sie heute üblicherweise gelehrt wird, ist in der Sprache der Mengenlehre formuliert und baut auf den Axiomen der Mengenlehre auf. Die meisten mathematischen Objekte, die in Teilbereichen wie Algebra, Analysis, Geometrie, Stochastik oder Topologie behandelt werden, um nur einige wenige zu nennen, lassen sich als Mengen definieren. Gemessen daran ist die Mengenlehre eine recht junge Wissenschaft; erst nach der Überwindung der Grundlagenkrise der Mathematik zu Beginn des 20. Jahrhunderts konnte die Mengenlehre ihren heutigen, zentralen und grundlegenden Platz in der Mathematik einnehmen. | ||||||
|
|
Die Mengenlehre wurde von Georg Cantor in den Jahren 1874 bis 1897
begründet. Statt des Begriffs Menge benutzte er anfangs Wörter wie
„Inbegriff“ oder „Mannigfaltigkeit“; von Mengen und Mengenlehre sprach er
erst später. 1895 formulierte er folgende Mengendefinition: „Unter einer „Menge“ verstehen wir jede Zusammenfassung M von bestimmten wohlunterschiedenen Objekten m unserer Anschauung oder unseres Denkens (welche die „Elemente“ von M genannt werden) zu einem Ganzen.“ Cantor klassifizierte die Mengen, insbesondere die unendlichen, nach ihrer Mächtigkeit. Für endliche Mengen ist das die Anzahl ihrer Elemente. Er nannte zwei Mengen gleichmächtig, wenn sie sich bijektiv aufeinander abbilden lassen, das heißt, wenn es eine Eins-zu-eins-Beziehung zwischen ihren Elementen gibt. Die so definierte Gleichmächtigkeit ist eine Äquivalenzrelation und die Mächtigkeit oder Kardinalzahl einer Menge M ist nach Cantor die Äquivalenzklasse der zu M gleichmächtigen Mengen. Er beobachtete wohl als Erster, dass es verschiedene unendliche Mächtigkeiten gibt. Die Menge der natürlichen Zahlen und alle dazu gleichmächtigen Mengen heißen nach Cantor abzählbar, alle anderen unendlichen Mengen heißen überabzählbar. Wichtige Ergebnisse von Cantor Die Mengen der natürlichen, der rationalen (Cantors erstes Diagonalargument) und der algebraischen Zahlen sind abzählbar und damit gleichmächtig. Die Menge der reellen Zahlen hat größere Mächtigkeit als die der natürlichen Zahlen, ist also nichtabzählbar (Cantors zweites Diagonalargument). Die Menge aller Untermengen einer Menge M (ihre Potenzmenge) hat stets größere Mächtigkeit als M, das ist auch als Satz von Cantor bekannt. Von je zwei Mengen ist mindestens eine gleichmächtig zu einer Untermenge der anderen. Das wird mit Hilfe der von Cantor ausführlich behandelten Wohlordnung bewiesen. Es gibt überabzählbar viele Mächtigkeiten. Cantor benannte das Kontinuumproblem: Gibt es eine Mächtigkeit zwischen derjenigen der Menge der natürlichen Zahlen und derjenigen der Menge der reellen Zahlen? Er selbst versuchte es zu lösen, blieb aber erfolglos. Später stellte sich heraus, dass die Frage grundsätzlich nicht entscheidbar ist. |
| 1. Allgemeines zu Relationalen Modellen nach Codd |
|
|
|
|
|
Relationale Datenbanksysteme haben die Entwicklung der Datenbanktheorie und ihrer praktischen Umsetzung in den letzten 20 Jahren wesentlich beeinflusst. Die Ursachen dafür sind zu finden ineiner fundierten theoretischen Grundlage,
|
|
|
... das Codd'sche Relationenmodell mathematisch betrachtet |
|
|
Zur Erinnerung: Seien A und B zwei Mengen, dann ergibt sich das kartesische
Produkt oder die Produktmenge aus:
|
|
|
d.h. das kartesische Produkt ist die Menge aller geordneten Paare. Eine Relation
R über A und B wird definiert als:
|
|
|
d.h. bei einer Relation werden nicht alle möglichen geordneten Paare, sondern im
allgemeinen nur Teile davon, ausgewählt. Im obigen Fall spricht man von einer
binären Relation mit einer Menge geordneter Paare. Die Erweiterung auf n mit dem
Ergebnis einer n-stelligen Relation ergibt:
|
|
|
Eine n-stellige Relation ist somit eine Menge von geordneten n-Tupeln. Eine (CODD'sche)
Relation CR = CR(M1, M2, ..., MI) ist eine
Teilmenge des kartesischen Produktes der zugehörigen Merkmalswertemengen Vl,
V2, ..., VI:
|
|
|
Die Elemente |
|
|
mit
|
|
|
der Relation CR heißen n-Tupel (oder kurz: Tupel). Die natürliche Zahl I bezeichnet den Grad oder die Stelligkeit der Relation CR. Statt CR wird aus Gründen der Vereinfachung im weiteren R verwendet. |
|
|
... die Codd'sche Relationenalgebra |
|
|
Zur Erinnerung: In der Mathematik wird unter einer Algebra die Zusammenfassung
einer Menge O von Objekten (Trägermenge) und einer Menge von Operationen
(Operationenmenge) auf Objekten der Trägermenge verstanden. (Die Operationen
führen nicht aus O heraus ...) Die Relationenalgebra ist eine spezielle Algebra mit
|
|
|
... die Operationen der klassischen Relationenalgebra |
|
|
Es seien R, R1, R2 Relationen mit den Merkmalsmengen M, M1, M2. Dann soll gelten: |
|
|
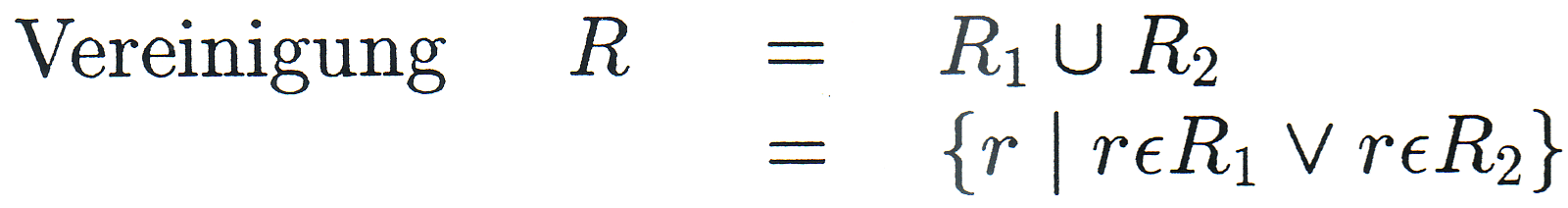 |
|
|
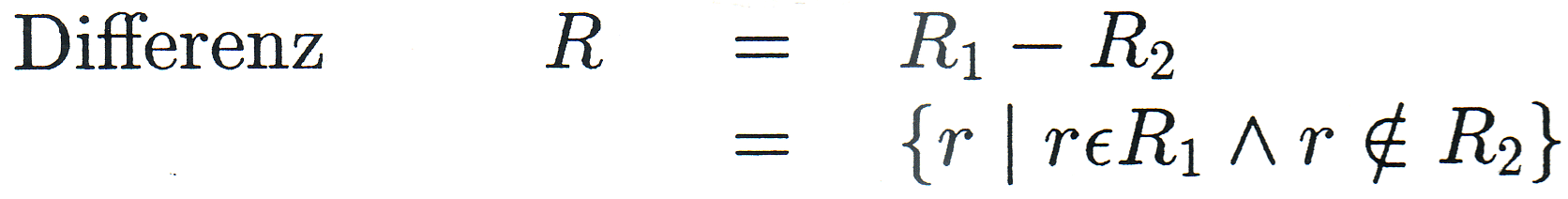 |
|
|
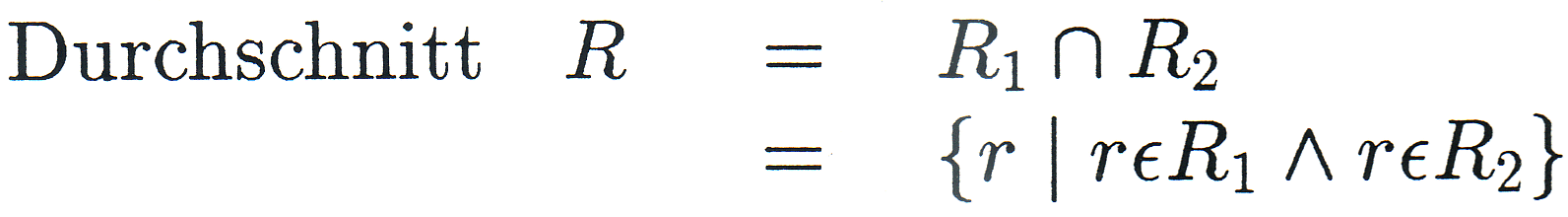 |
|
|
... die tupelauflösenden Operationen |
|
|
Es seien R, R1, R2 Relationen mit den Merkmalsmengen M, M1, M2 (... wobei die Vergleich beteiligten Merkmale nur einmal in R aufgenommen werden!). Dann soll gelten: |
|
|
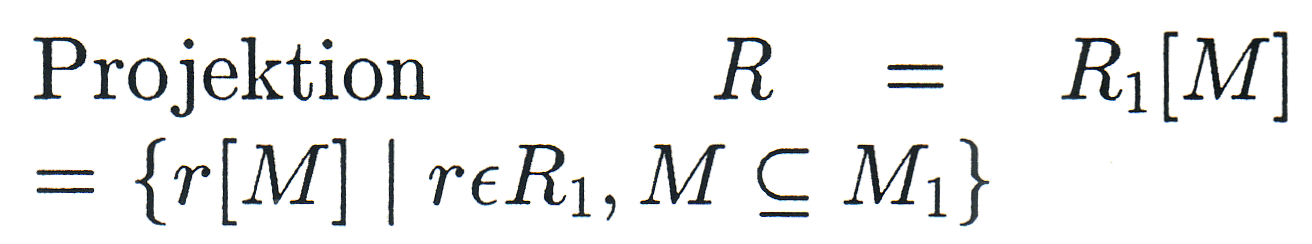 |
|
|
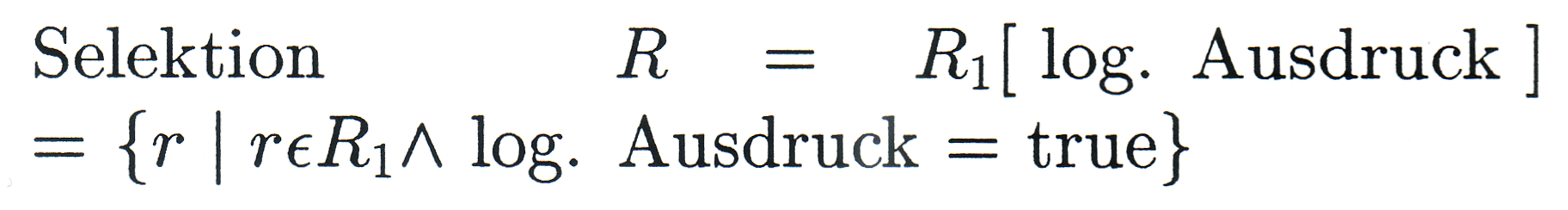 |
|
|
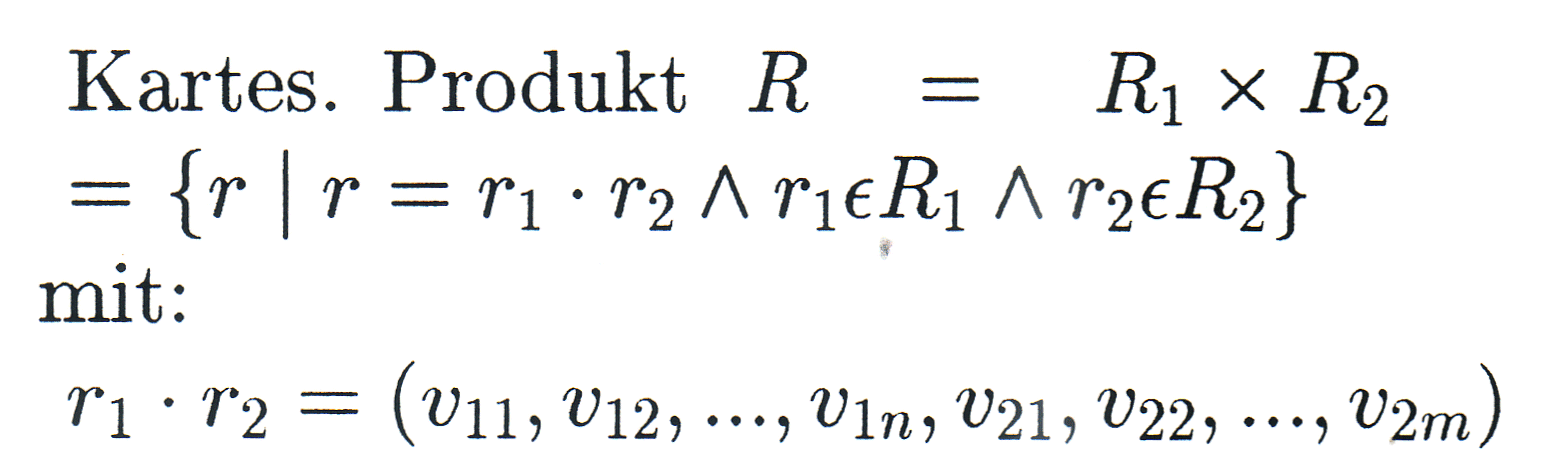 |
|
|
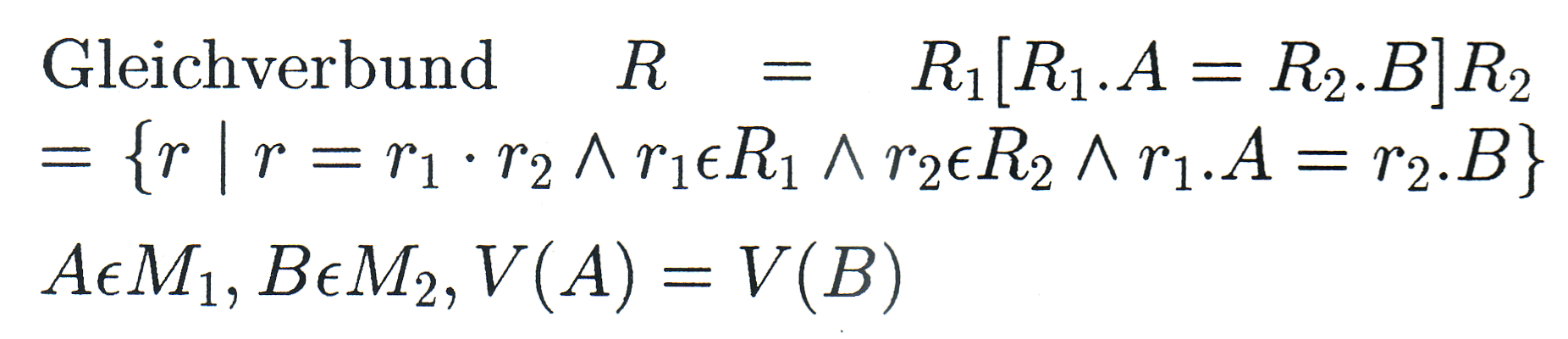 |
|
|
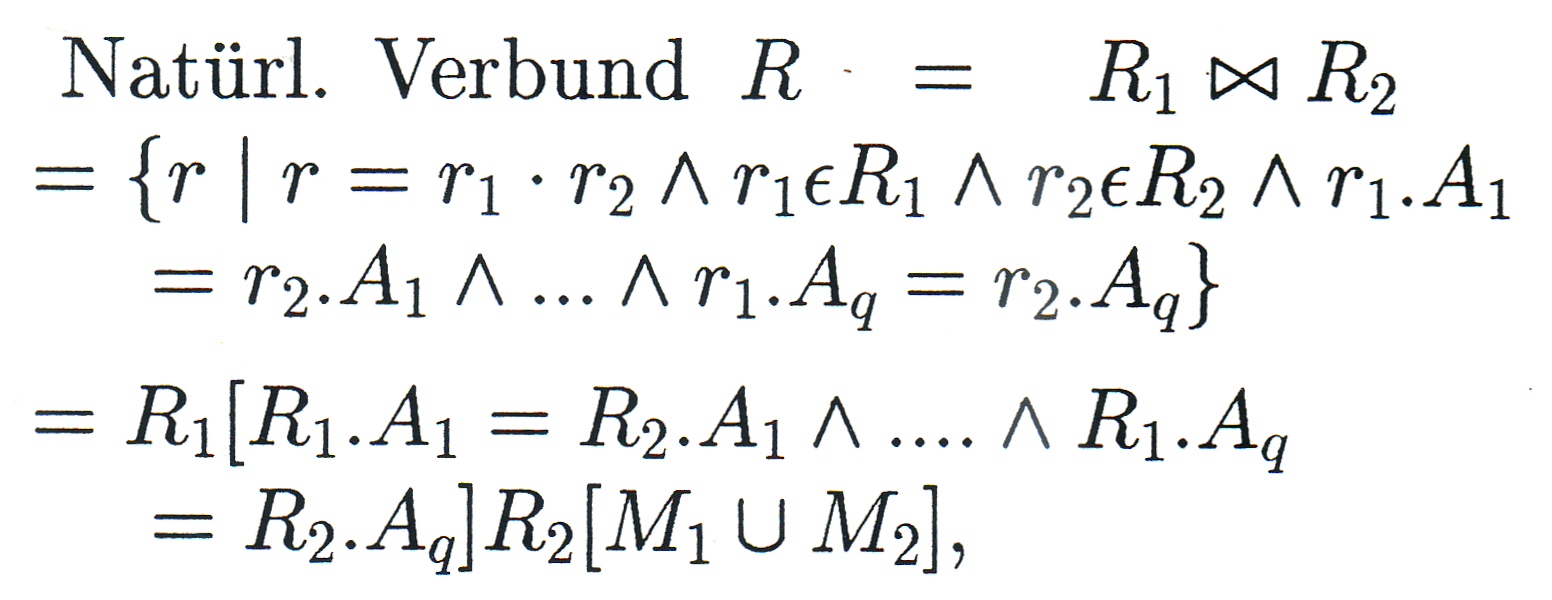 |
| 2. Basiskonstrukte der Standard SQL |
|
|
|
|
|
Im Zuge allgemeiner Informationen wird unter diesem Punkt auf weiter unten enthaltene Informationen zurückgegriffen. So gut es möglich ist, werden diese aber durch eine Linkstruktur ergänzt und dort auch auf dann konkrete Beispiele verwiesen. |
|
Domains (Wertevorräte) Entsprechend späterer SQL-Standards wird ein Statement zur Definition benutzereigener Domains eingeführt - das CREATE DOMAIN-Statement. Damit kann man weitere Datentypen auf der Grundlage der Standarddatentypen definieren und Prüfklauseln (CHECK-Clauses) sowie Standardwerte (default values) einführen, wodurch die Integrität der Datenbank unterstützt wird. |
| 3. Identifer, Operatoren und Funktionen |
|
|
|
|
|
Konsistenz garantiert Widerspruchsfreiheit. Niemals - auch nur kurzzeitig gibt es den Zustand, in welchem die Inhalte relational miteinander verknüpfte Tupel einander widersprechen. Idealerweise organisiert dies das DBMS selbst oder überwacht zumindest die konsequente Einhaltung selbiger. |
| 4. Basiskonstrukte |
|
|
|
|
|
In SOL werden Ausdrücke in den verschiedensten Zusammenhängen verwendet, z. B. in Suchbedingungen (search conditions) und in der SET-Klausel eines UPDATE-Statements. Ein Ausdruck liefert immer einen einzelnen Wert. |
| 5. Subselects |
|
|
|
|
|
Das
Konstrukt Subselect wird vor allem in SELECT-Statements, aber auch in vielen
anderen Statements (INSEKT, UPDATE, DELETE, CREATE VIEW) als Komponente
(Substruktur) verwendet. Das Subselect ist ein sehr komplexes Konstrukt; es
hat folgende Klauseln: notwendig SELECT-Klausel |
|
SELECT name, gehalt * 1.2 neues_gehalt Im Ergebnis dieser Abfrage entstehen zwei Spalten mit den Spaltenbezeichnungen NAME NEUES_GEHALT Die Spaltenwerte enthalten die Namen sowie das mit 1.2 multiplizierte Gehalt; Name und Gehalt sind Werte aus der Tabelle MITARB. Der Ausdruck gehalt * 1.2 wird in der Ergebnistabelle mit der Spaltenbezeichnung NEUES_GEHALT ausgegeben. |
| 6. Statemaents zur Metadaten-Definition |
|
|
|
|
|
Die Statements dieser Gruppe
erzeugen die Objekte der Datenbasis. Hierzu gehört auch die Erzeugung der
Datenbasis selbst. Die Metadaten beschreiben die Datenbasis in dem für die
effektive Arbeit auf der Datenbasis erforderlichen Maße. Sie sind im Data
Dictionary (DD) gespeichert. Entsprechend den allgemeinen Anforderungen bei
der Arbeit mit Daten sind Statements zum Erzeugen, Verändern und Löschen
notwendig. Die Statements zum Definieren der Datenbasis sind: CREATE SCHEMA, CREATE DATABANK, CREATE IDENT, CREATE INDEX, CREATE SYNONYM, CREATE TABLE, CREATE VIEW, CREATE DOMAIN Statements zur Änderung der Datenbasis sind: ALTER DATABANK, ALTER IDENTS, ALTER TABLE. Statements zum Löschen von Objekten sind die DROP-Statements entsprechend den CREATE-Statements. Weiterhin gibt es noch das nützliche COMMENT-Statement, das den Datenbankobjekten Informationen zuordnet. |
|
zur Hauptseite |
© Samuel-von-Pufendorf-Gymnasium Flöha | © Frank Rost am 24. November 2009 |
|
... dieser Text wurde nach den Regeln irgendeiner Rechtschreibreform verfasst - ich hab' irgendwann einmal beschlossen, an diesem Zirkus nicht mehr teilzunehmen ;-) „Dieses Land braucht eine Steuerreform, dieses Land braucht eine Rentenreform - wir schreiben Schiffahrt mit drei „f“!“ Diddi Hallervorden, dt. Komiker und Kabarettist |



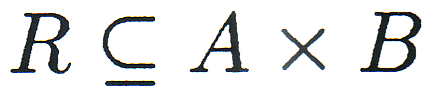{kind=link}