 |
Eine Datenbasis zukunftstrõchtig so zu
modellieren, dass sie auch Worst-Case-Bedingungen standhõlt und aktuell
unter verschiedensten Plattformen gehandhabt werden kann sowie nach oben
offen f³r k³nftiger Erfordernisse ist, bedeutet ein extrem schwieriges
Unterfangen anzugehen (eigentlich ist es unm÷glich - der
Datenbankentwickler m³sste wissen, was in Zukunft f³r Forderungen
gestellt werden).
Zur Abschreckung werden Datenbasen dargestellt, wie sie landlõufig
- und nat³rlich falsch entwickelt werden. Dies wird gekoppelt mit den
entsprechenden Tipps zum korrekten entwickeln von Datenbasen.
Die folgenden Zeilen sowie zugeh÷rige Links beachtet, f³hren automatisch
zu relationalen Datenbasen in mindestens dritter Normalform.
|
 |
|
Datenbestand
Pilze
 Entity-Type Pilze
Entity-Type Pilze |
Normalisierung mit Kinderschuhen ist
angewandt worden - Schl³ssel gibt es ... Entity-Types zum
Obejekt-Management ...
selbst ein Relationship-Modell ist an Bord ... |
|
|
... und das unten stehende ergibt sich, wenn man die Mehrheit der deutschen
Bev÷lkerung auf Datenbanken loslõsst (dabei sind Schl³ssel schon fast
zwangslõufig) - eine weise Entscheidung von Microsoft, kein
Datenbanksystem standardmõ▀ig in Office an den unbedarften Nutzer zu
verkaufen ;-)
|
|
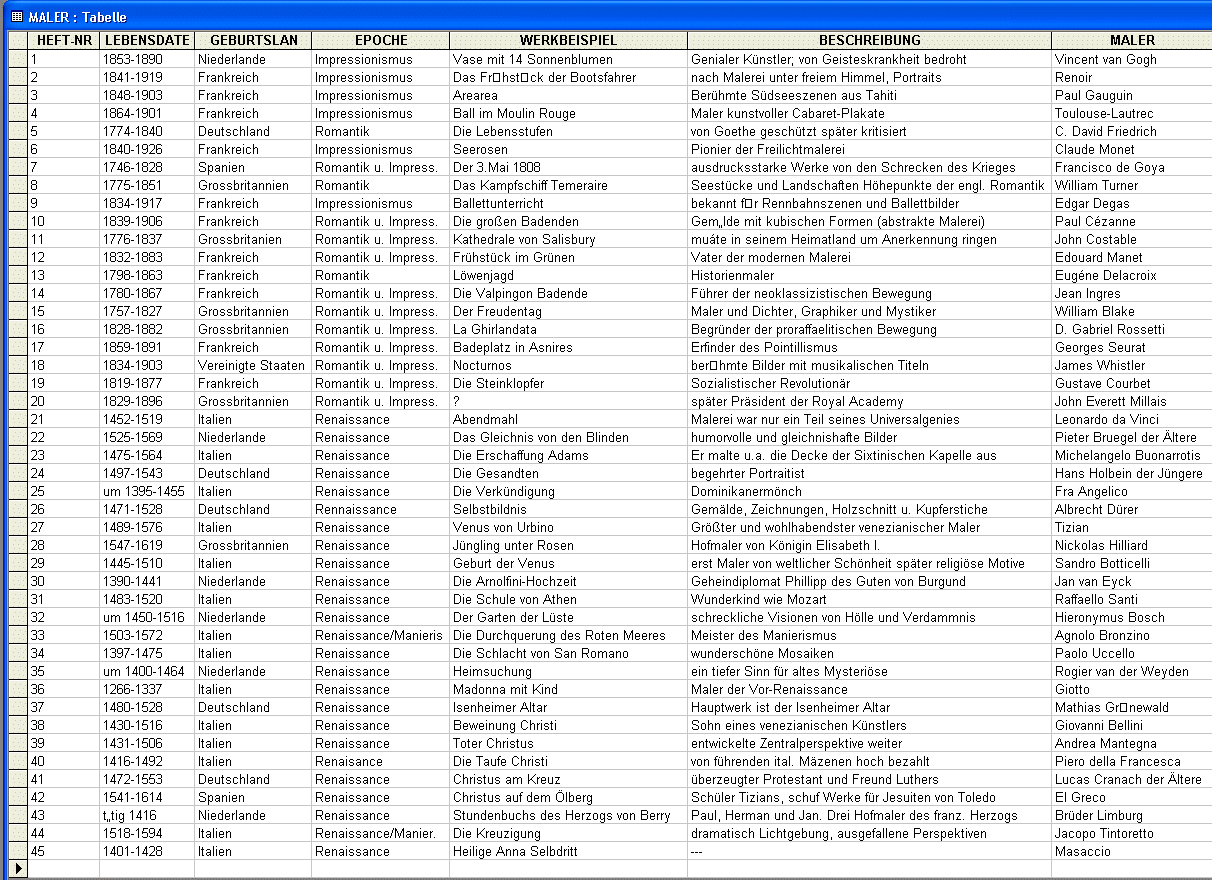
| Entity-Type "Lebenswerke von Malern"
|
Entity-Type
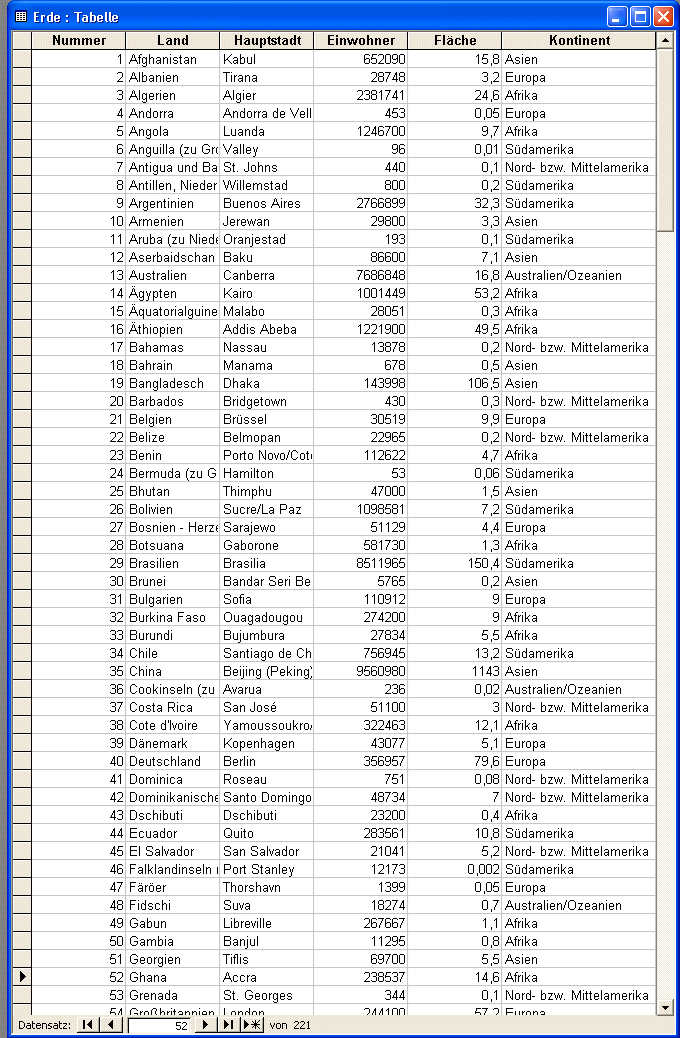
"Lõnder der Erde"
|
Entity-Type
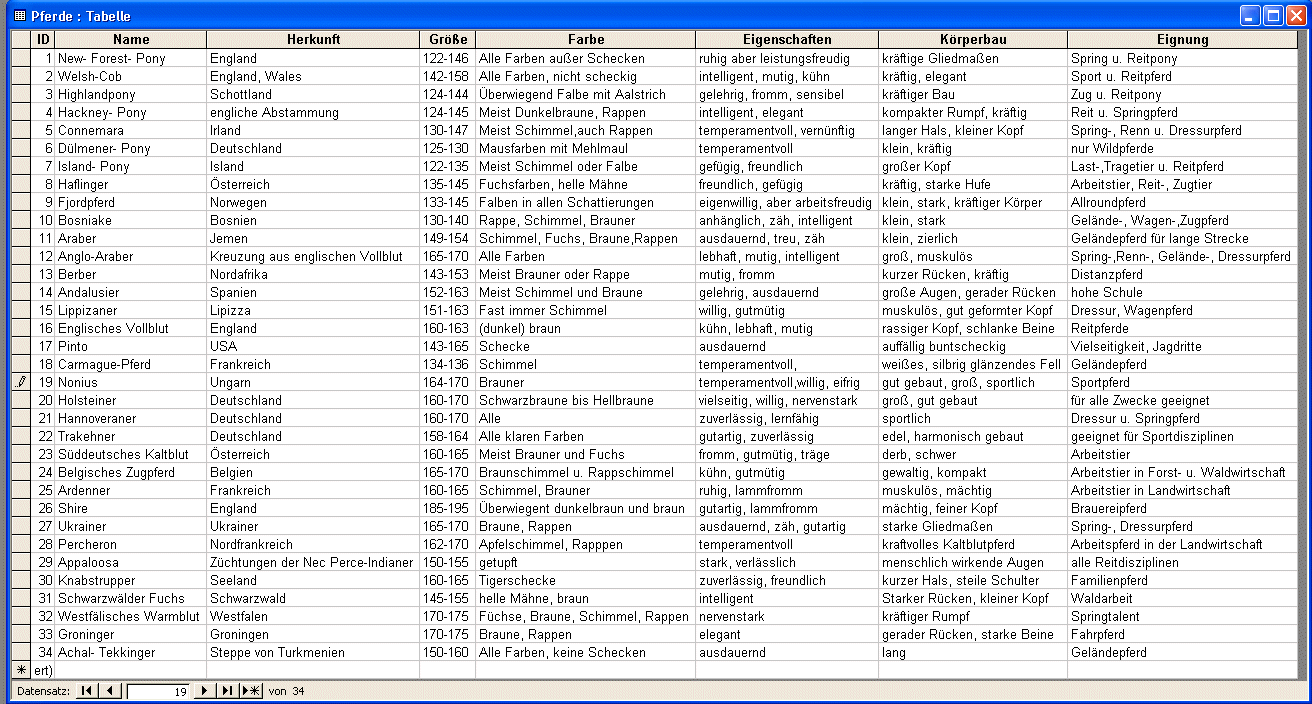
"Pferde"
|
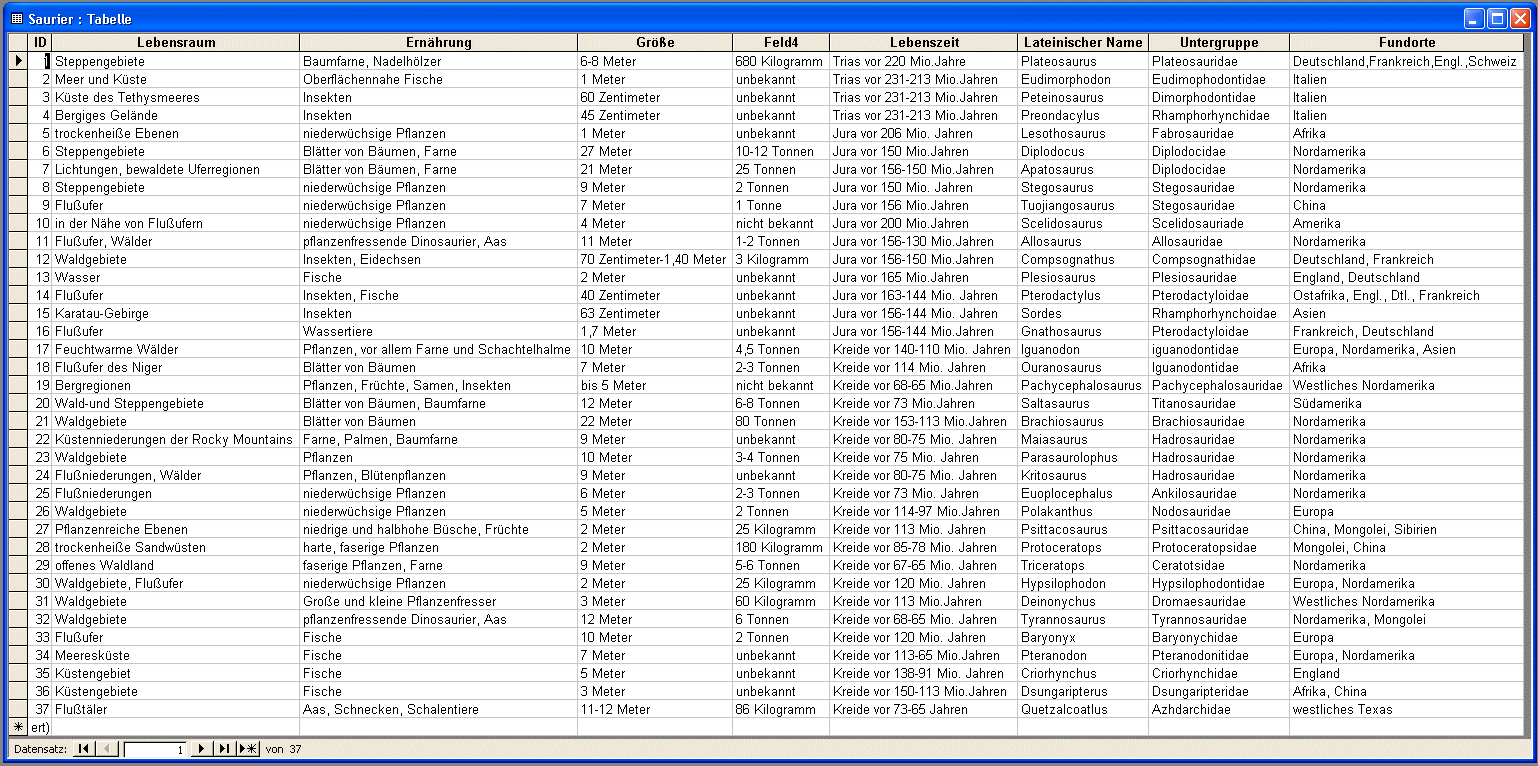
Entity-Type
"Saurier"
|
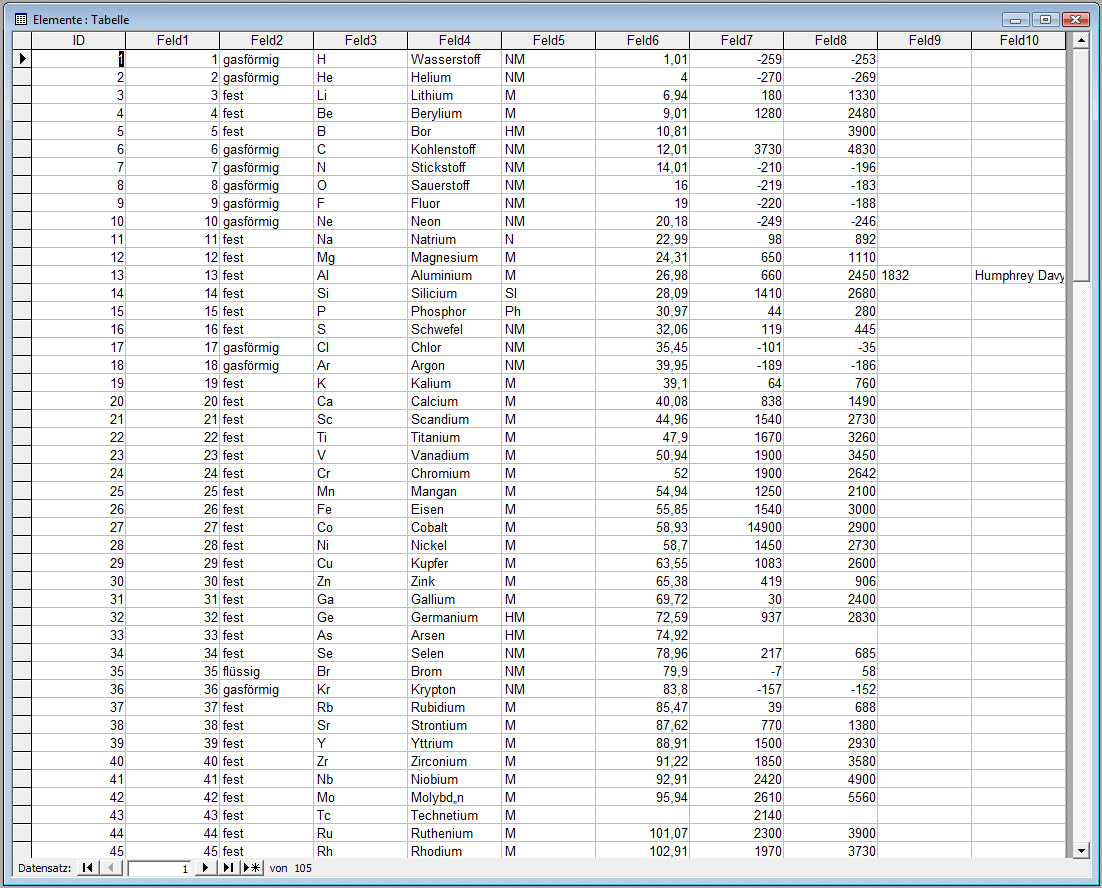
Entity-Type
"Elemente"
|
|
Datenbestand
Maler |
Datenbestand
Erde |
Datenbestand
Pferde |
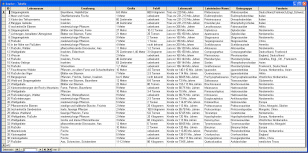
Datenbestand
Saurier
|
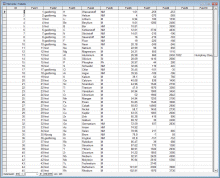
Datenbestand
Elemente
|
- Entitytyp-Bezeichung klein geschrieben
- falsche Domainbenutzung f³r die Malepochen
- Umlaute in den Attributbezeichnern
- Verwendung von Abk³rzungen in den Attributwerten
- nichtatomare Datenhaltung
- Verletzung des Domainbereichs
- falsche und noch dazu uneinheitliche Datenhaltung in den
NULLWERTEN
- L÷sungsansõtze aktuell:
verwendet NULL's im ACCESS 2.0-Format
verwendet
Redundanzen im ACCESS 2.0-Format |
- diese Datenbasis schneidet noch vergleichsweise gut ab - Zahlen sind schon Zahlen, aber die Kontinentzuordnung geht voll
ins MINUS
- Entitytyp-Bezeichung klein geschrieben
- falsche Attributbezeichner (Tabellenkopfnamen)
- falsche Domainbenutzung f³r die Kontinente (Domain ist der
definierte eindeutige Wertevorrat f³r die Attributwerte)
- Umlaute in den Attributbezeichnern
- Verwendung von Abk³rzungen in den Attributwerten
|
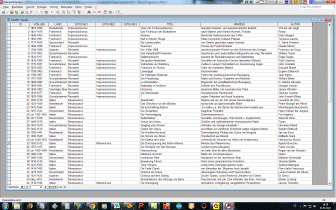
- das Grauen bekommt ein Gesicht - hier ist so ziemlich alles
falsch gemacht worden, was immer man falsch machen kann
- Entitytyp-Bezeichung klein geschrieben und lõnger als 10
Zeichen - Umlaute und Sonderzeichen sind selbstverstõndlich
enthalten
- falsche Attributbezeichner (Tabellenkopfnamen)
- Verwendung von Bereichsangaben
- verschiedene Ma▀einheiten
- nichtatomare Datenhaltung
|
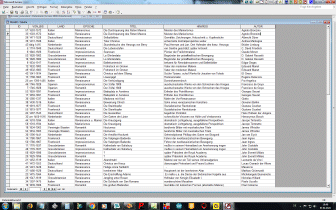
- das Grauen ist vollstõndig und alle Fehler sind gemacht - wer
jemals eine derart organisierte umfangreiche Datenbasis zur
scharfen Informationsrecherche in die Hõnde bekommt - dann "Gute
Nacht! ;-)
- ... dumm ist leider: Du bekommst sie, und zwar genau so
geartet - zu toppen ist das schlecht ;-)
- ... wer alle Fehler finden will, vergleicht einfach mit den
zehn Geboten sowie Hinweisen unten
- Entitytyp-Bezeichung klein geschrieben und lõnger als 10
Zeichen - Umlaute und Sonderzeichen sind immer noch enthalten
- nichtatomare Datenhaltung
- falsche Attributbezeichner (Tabellenkopfnamen) - lang, Umlaute
und Sonderzeichen (Igitt!!!)
- falsche Domainbenutzung f³r die Ernõhrung
- Umlaute in den Attributbezeichnern
- Verwendung von Abk³rzungen in den Attributwerten (Mio.)
- verschiedene Ma▀angaben beim Gewicht (kg und Tonnen gemischt)
|
- wir bekommen ein "... Go flight!" - nicht die beste L÷sung -
jedoch grundsõtzlich m÷glich
- das liegt aber hier in der Natur der Dinge
|
|
|
|
|
|
|
|

L÷sungsideen einer Sch³lergruppe um F. Pfefferkorn im Mai 2021 |

L÷sungsideen von L. Prinz im Mai 2021 |
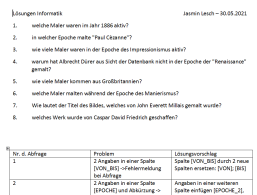
L÷sungsideen einer Sch³lergruppe um
Julia Lesch im Mai 2021 |

... und so sieht das derzeit J. Schrader |

... L÷sungsansatz von Nicolas Kunze |
|
|
Die zehn Gebote der Datenbanktechnik
- Du sollst
als erstes richtige Datenformate wõhlen und das Dokument speichern!
- Du sollst
die Datenhaltung immer eindeutig, aktuell und korrekt f³hren!
- Du sollst
zum Datenzellenwechsel nicht die ENTER-Taste benutzen, wohl aber die
Tabulator-Taste.
- Du sollst
nicht mehr als eine Information in jede Datenzelle eintragen, es sei
denn, es gilt eine zulõssige Ausnahme!
- Du sollst
nicht gleiche Merkmale mit verschiedenen Merkmalswerten beschreiben!
- Du sollst
keinen beliebigen Eintrag in unbekannte Datenfelder setzen, sondern
sie frei lassen!
- Du sollst
nicht verwenden in Datenbanken Abk³rzungen!
- Du sollst
wissen, dass die Anordnung der Datensõtze und der Datenfelder f³r
die Datenbank unerheblich ist!
- Du sollst
in Datenbanken nicht formatieren, es sei denn, es handelt sich um
einen Standard (DM oder %)!
- Du sollst
nicht benutzen den Datentyp Zahl, wenn in das Datenfeld keine Zahlen
eingetragen werden (Telefonnummer, Postleitzahlen)!
|
|
|
Eine klare, eindeutige und einheitliche
(homogene) Welt, ohne Ausnahmen w³rde einfache Datenbasen zulassen - die
Welt ist aber gerade nicht klar, eindeutig und ohne Ausnahmen - im
Gegenteil, wenn wir nur die Steuergesetzgebung hernehmen, sehen wir das
Chaos - und auch dieses soll (bzw. muss) datentechnisch auch noch korrekt
abgebildet werden.
- lernen Sie m÷glichst schnell, den "Worst-Case"
zu planen und gehen Sie nicht vom "Best-Case" aus, denn es kommt meist
schlimmer, als Sie denken ;-)
- gehen Sie nicht von sich aus, sondern
fragen Sie sich: was wird der DAU mit meiner Datenorganisation machen?
- der DAU wird jede auch noch so kleine
L³cke in Deinem "sicheren" Datenkonzept sehen und nutzen - Dir selbst
ist dieses durch Fachkenntnis selbstverstõndlich verwehrt - Du wirst
selbst bei Planung des DAU-Falles diese L³cke nicht erkennen (Merke: So
dumm, wie sich manche anstellen, kann man nicht denken)
|
|
Hinweise zum Umgang mit Datenbasen:
- Datenbanken
dienen dem schnellen Informationszugriff und nicht dem Erfassen von
Informationen!!!
- Datenbanken beruhen auf
absoluter Exaktheit - darum: sei erfolgreich, indem auch Du exakt bist
- lern' dies so schnell wie m÷glich exakt zu definieren, Ausnahamen zu
erkennen und aufzuf³hren - Aktuelles, Bewiesenes, Homaogenes und
Eindeutiges sind die Trumpf-Karten der Datentechnik - plane den
Worst-Case
- lerne prõzise
mathematische Definitionen schõtzen - Datenbanken nutzen eben diese
- Datenbanken sind als
Informationssammlungen nicht neu - sie werden nur seit neuerer Zeit
(seit etwa 40 Jahren) auf Computern eingesetzt
- Datenbanken liefern bei Abfragen
die Genauigkeit, die bei der Dateneingabe, Aktualisierung und
Fehlerbereinigung aufgewandt worden ist (fehlerhafte Datenbanken
liefern falsche Ergebnisse!)
- alle
Objekte mit gleichen Eigenschaften m³ssen auch durch gleiche
Merkmalswerte beschrieben werden also Volkswagen und nicht VW
miteinander mischen!!! Klõre die eindeutige Schreibweise aller
konkreten Datenmerkmale f³r gleiche Informationen - also entweder
f³r die Herkunft der Pferde "England" oder "englische
Abstammung", aber keinesfalls diese Eintrõge beide in einem
Diskurs verwenden! Siehe dazu auch das F³nfte Gebot der
Datenbanktechnik.
- Die Informationen einer Datenbasis
werden in Attribut- oder Datenfeldern gespeichert! Attributfelder bestehen aus Feldnamen und -inhalt!
Datenfelder besitzen einen
Datentyp, welcher f³r die korrekte Datenverwaltung von fundamentaler
Bedeutung ist!
- Anordnung der Merkmale und der
Datensõtze ist f³r die Datenbank unerheblich!
- Verwende in Datenbanken niemals
Abk³rzungen - durch diese entstehen Interpretationsm÷glichkeiten und
verschiedene Schreibweisen von Informationen (Beispiel: der
Datenbankentwickler notiert "Heirich-Heine-Stra▀e" - Sie
suchen nach "Heinrich-Heine-Str." - Sie finden was? -
Richtig! Nix - und dies, obwohl eine sachliche ▄bereinstimmung
vorliegt!)
- verwenden Sie f³r
Ma▀angaben einheitliche Umrechnungsfaktoren - entweder alles in mm
oder alles in km
- verwenden Sie die f³r Ihre Daten
relevanten Datentypen (Datum vom Typ Datum, Postleitzahlen vom Typ
Text (denn sie sind Text!))
- professionelle Datenbanken fordern
ein minimales Schl³ssel-Konzept, welches von Works nicht unterst³tzt
wird
- Schl³ssel sind Datenfelder, die ein eindeutiges
Unterscheidungskriterium schaffen, welches sich damit nicht
wiederholen darf
- Namensfelder sind dazu nicht gut geeignet, da sich
Nachnamen schnell wiederholen k÷nnen
- g³nstig ist, jedem Datensatz
eine eindeutige äSchl³sselnummerō zu vergeben
- atomare Datenhaltung - tragen Sie in jedes Datenfeld genau
eine Information ein (wobei sich wenige sinnvolle Ausnahmen in der
Datenhaltung durchgesetzt haben, z. B. Stra▀e und Hausnummer
gemeinsam zu erfassen, denn diese beiden Informationen stehen in einem
jedermann bekanntem Zusammenhang) - dies muss jedoch bereits bei der
Strukturplanung der Datenbank ber³cksichtigt werden
Dateneintrõge wie ä1876 -1934ō f³r Lebensdaten sind also falsch,
genau wie ä2 kmō und äRomantik, Impressionismus, Renaissanceō
- Auswege:
- diese Datenfelder sind zu
trennen oder die Ma▀einheiten im Datenfeldnamen unterzubringen,
etwa: äEntfernung in kmō, äEpoche_1ō, äEpoche_2ō,
äEpoche_3ō (dies ist zwar nicht die eleganteste, aber eine
richtige L÷sung)
- es ist ebenso m÷glich, die Datenfelder (Attribute) mit den
einzelnen m÷glichen Beschreibungsmerkmalen (der Fachmann spricht
hier von Attributwerten der Domain) zu benennen (zu bezeichnen)
und in der Folge mit den Kriterien (nat³rlich auch dem
entsprechenden Datentyp) "WAHR" - "FALSCH" zu
arbeiten
- ebenso ist es m÷glich, die einzelnen Objekte mehrfach
aufzuf³hren und ihre mehrfach auftretenden Attributwerte einzeln
zu erfassen (das f³hrt jedoch zu extrem hoher Redundanz und
Inkonsistenz in der Datenpflege)
- dagegen ist der Eintrag äRose
Marieō als Vorname richtig, ebenso wie ä─quatorial-Guyanaō, da
dies ja zusammengesetzte Namen und damit eine Information sind
- Datenfelder, f³r die augenblicklich
keine Information existiert, bleiben frei - man spricht von NULLWERTEN
(die aber nicht die Interpretation = 0 erlauben, denn 0 ist eine
konkrete Information. Dagegen bedeutet ein NULLWERT äunbekanntō!)
- NULLWERTE verhalten sich in der
Datenverwaltung immer kritisch - deshalb sind sie m÷glichst zu
vermeiden
- Sie erhalten v÷llig falsche
Auswertungen der Daten, wenn Sie in NULLWERTE Informationen, wie z. B.
äunbekanntō, einen Bindestrich oder äleerō eintragen -
Datenbanken gehen mit NULLWERTEN richtig um - Sie verfremden also mit
solchen Eintrõgen die Informationen und die Abfragestrategien Ihrer
Datenbasis
- Reihenfolgen in der Anordnung der
Datenfelder und der Datensõtze sind v÷llig beliebig und haben f³r
die Auswertung der Datenbank keinerlei Bedeutung. Eine Datenbank muss
nur vollstõndig und aktuell sein!
- definieren Sie genau einzuhaltende
Beschreibungsmerkmale f³r Ihre Objekte - der Fachmann spricht von
einer Domain (das ist sozusagen der Wertevorrat ihres Objektmerkmals)
- einmal VW und ein anderes mal Volkswagen in Ihre Datenbasis
einzutragen, ist t÷dlich
- ganz schlimm gestalten sich solche
Eintrõge wie: "Um 1432" statt exakt "1432" z.B.
f³r das Geburtsjahr von C. Columbus - wir wissen es nõmlich nicht
exakt) - dann lieber einen MULLWERT und Besonderheiten unter
Bemerkungen zur Auswertung abfangen
|
|
Vermeiden
Sie:
-
falsche
Daten in den Datenfeldern (Tippfehler, falsche Erfassungen (z. B. falsch
abgeschrieben))
-
Dateninkonsistenz
(widerspr³chliche Daten,
bedingt durch Korrekturen oder einfach ▄bertragungsfehler)
-
falsche Schl³sselkonzepte
-
Abk³rzungen
in Datenfeldinhalten (Abk³rzungen ausschlie▀en!)
-
falsche
Datentypen - Zahlen m³ssen Zahlen bleiben (Ma▀einheiten geh÷ren nicht in
den Datenbestand oder m³ssen vom System selbst generiert werden)
-
NULLWERTE in
Datenfeldern sind bez³glich der Datenbankauswertung immer kritisch - schon
die Struktur (Datenfelder und Datentypen) muss so aufgebaut sein,
dass m÷glichst
keine Leerfelder vorhanden sind
-
nicht zu
wissen, wie sich Leerfelder eines Datenbankmanagementsystems bei
statistischer Auswertung verhalten
-
veraltete
Daten
-
ENTER-Tasten
statt TAB-Stop's
-
Leerzeichen
in Datenfeldern
besonders am Anfang
-
Apostroph
statt Akcent (Rene' statt Renķ)
-
mehrere
Information pro Datenfeld
(nicht atomare
Informationsdarstellung)
-
Redundanzen
(Wiederholungen) in den Datensõtzen
-
falsche
Datentypen und -relationen - diese zu korrigieren ist im Extremfall ohne
Datenverlust unm÷glich
-
f³r eine
bestimmte Anwendung sollte man sich f³r ein Datenbanksystem entscheiden -
im Nachhinein zu wechseln kann schwierig werden
(WORKS
z. B. verwendet kein Datentypenmodell - beim Konvertieren in dBASE gehen
Daten verloren) - Anmerkung: WORKS 4.0 setzt mit Datentypen an und kennt aus
Kompatibilitõtsgr³nden immer noch den Datentyp äSTANDARDō
|
|
beachte dazu auch
Datensichheit und Datenintegriõt |
|
In diesem Augenblick betreten wir den Bereich
eines Diskurses, der, wenn er richtig organisiert ist, theoretisch alle
Objekte dieser Welt einschlie▀lich nicht mehr vorhandener, zu einander in
Beziehung setzen k÷nnte. Das will und braucht aber keiner, also bilden wir
einen "Realitõtsausschnitt", ³ber den wir wirklich in unserem Zusammenhang
Auskunft ben÷tigen, im Diskurs ab. Das macht die Datenstruktur mit all
ihren Ausnahmeforderungen immer noch kompliziert genug. |
|
nutzen Sie Erkenntnisse aus der Beschreibung der 1 :1-Beziehung |
| |
|
| |
|
|
Richtige Modellierung von Realitõtsausschnitten
Eine m÷glichst prõzise Modellierung von Daten stellt eine wichtige
Voraussetzung f³r die Erstellung einer Datenbank dar. Die Analyse des
Realitõtsausschnittes (Diskursbereich) mit der Herausl÷sung wichtiger Objekte
(Entitõten) und ihrer Beziehungen zueinander bilden den ersten Schritt. Solche
Objekte k÷nnen Personen, Sachen, Begriffe, Ereignisse sein. Die Beziehungen sind
Verbindungen zwischen ihnen, die im betrachteten Diskursbereich wichtig sind.
Eine Person z. B. kann je nach betrachtetem Realitõtsausschnitt ein Mitarbeiter
einer Firma, ein Kunde, ein Patient usw. sein. Die Merkmale, die zur
Charakterisierung einer solchen Person herangezogen werden, k÷nnen deshalb sehr
unterschiedlich sein.
Um die Grundbegriffe der Modellierung am Beispiel zu erlõutern, werden als
Realitõtsausschnitt die Mitarbeiter einer Firma betrachtet, die an Projekten
arbeiten. Ein Mitarbeiter (Entitõt) arbeitet an (Beziehung) einem Projekt
(Entitõt). Ein Mitarbeiter (Entitõt) ist Angestellter (Beziehung) der Firma
(Entitõt).
Bild 1.5 Entitõts-Beziehungs-Diagramm
Hinter der Entitõt Mitarbeiter verbirgt sich eine (Entitõts-)Menge von
Mitarbeitern (Krause, Sonntag, M³ller usw.), die durch gleiche Merkmale
ausgezeichnet sind. Nach dem Erkennen wichtiger Entitõten und ihrer Beziehungen
zueinander besteht der nõchste Schritt darin, Entitõten und Beziehungen durch
das Auffinden ihrer charakteristischen Merkmale nõher zu bestimmen.
Diese Begriffsbildungen sind bereits Gegenstand der Datenmodelle, die im
folgenden Abschnitt nõher betrachtet werden. ' 1.4.4 Datenmodelle
Datenmodelle stellen einen Begriffsapparat zur Verf³gung, der es erlaubt, von
den konkreten Objekten und Sachverhalten des Diskursbereiches zu abstrahieren
und mit den Elementen ein wirklichkeitstreues Modell zu konstruieren.
|
|
| Schritte zur Datenerfassung f³r m : n Beziehungen |
|
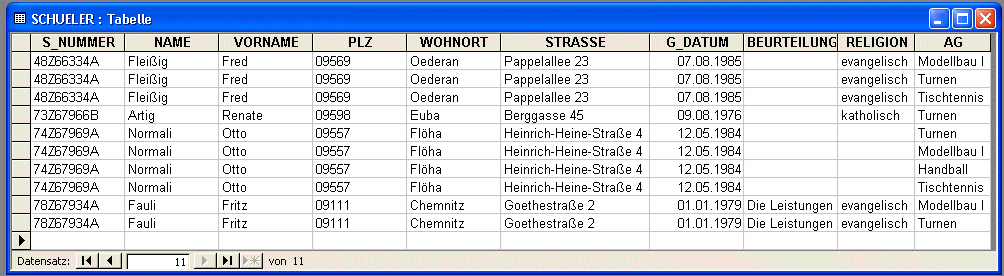
Entity
SCHULER |
Download
Datei |
Vorteile |
Nachteile |
|

Datenbestand
SCHUELER nicht atomar |
|
- die Daten wurden widerspruchsfrei erfasst
- ein Schl³sselkonzept ist ³ber die Sch³lernummer vorhanden
- jedes Objekt ist einmal aufgef³hrt und eindeutig zu identifizieren
|
- die Datenstruktur ist nicht atomar - im AG-Attribut sind mehrere Informationseintrõge
vorgenommen worden
- diese Darstellung ist absolut ungeeignet, da hier nichtatomare
Eintrõge als Attributwerte zugelassen wurden
|
|

Datenbestand
SCHUELER atomar |
|
- die Daten wurden widerspruchsfrei erfasst
- die Datenstruktur ist atomar - jeder m÷glichen AG wurde ein
Datenfeld zugeordnet und darin die konkrete AG eingetragen
- jedes Objekt ist einmal aufgef³hrt und eindeutig zu identifizieren
- ein Schl³sselkonzept ist ³ber die Sch³lernummer vorhanden
|
- alle Attribute, welche beim jeweiligen Objekt nicht zutreffen
bleiben Leerfelder (NULLWERTE)
- kommt eine weitere AG hinzu, muss die gesamte Struktur erweitert
werden (noch mehr NULLWERTE)
|
|

Datenbestand
SCHUELER atomar |
|
- dies scheint unter momentanem Betrachtungszeitpunkt gar noch die
beste L÷sung - noch ist die Datenbasis nicht relational aufgel÷st
- die Daten wurden widerspruchsfrei erfasst
- die Datenstruktur ist atomar - jeder m÷glichen AG wurde ein
Datenfeld zugeordnet und darin die konkrete AG eingetragen
- jedes Objekt ist einmal aufgef³hrt und eindeutig zu identifizieren
- ein Schl³sselkonzept ist ³ber die Sch³lernummer vorhanden
|
|
|
Datenbestand
SCHUELER atomar |
|
- die Daten wurden widerspruchsfrei erfasst
- die Datenstruktur ist atomar - jeder m÷glichen AG wurde ein
Datenfeld zugeordnet und darin die konkrete AG eingetragen
|
- ein Schl³sselkonzept ist ³ber die Sch³lernummer nicht vorhanden -
die Daten jedes einzelnen Sch³lers m³ssen mehrfach aufgef³hrt
werden
- redundante Daten sorgen f³r Inkonsistenzen
- schon bei der Erfassung (schnell ist man in der Spalte
verrutscht)
- bei der Datenpflege (wenn der Sch³ler beispielsweise umzieht,
muss ³berall fehlerfrei die Adresse geõndert werden)
- jede Menge vollkommen ³berfl³ssige Arbeit bei entsprechend
vielen Daten
- unn÷tig gro▀e Datenmengen mit absolut identischen
Informationen
- lassen Sie nur bei einem AG-Leiter den Namen õndern (so was soll
ja vorkommen)
|
|









{kind=link}
{kind=link}
{kind=link}
{kind=link}