Kleiner ist nicht gleich weg!
Warum können wir aber Dateien mit offensichtlich gleichem Inhalt, also
z.B. Bilder auf denen das gleiche zu sehen ist, in unterschiedlcihen
Dateiformaten abspeichern und die Bilder unterschiedlich groß werden
lassen?
Es gibt immer ein grundlegendes Dateiformat. Dieses speichert die Daten
vollkommen umkomprimiert und benötigt somit am meisten Platz auf der
Festplatte. Diese Dateitypen gibt es wirklich für jede Art von Datei:
Bitmap (.BMP) für Bilder, Wave (WAV) für Audiodatein, Text (TXT) für
Textdatein usw. Warum gibt es aber Dateiformate, die mehr Platz benötigen
als die umkomprimierten, obwohl nicht mehr Inhalt vorhanden ist (ich
denke da ganz speziell an das MS Office Dateiformat DOC)? Dies hängt
ganz einfach mit dem sichtbarnen und nicht sichtbaren Teil einer Datei
zusammen. Der sichtbare Teil ist in dem Fall der Text und der nicht sichtbare
Teil sind Formatierungen und Einstellungen, die von Word automatisch
getätigt werden, auch wenn man diese gar nicht benötigt. Diese müssen
ja auch gespeichert werden, deshalb sind die Dateien immer größer als
reine Textdateien. Warum gibt es aber solche Dateiformate überhaupt?
Es gibt durchaus noch Situationen die unkomprimierte Dateien erfordern
- so z.B. grafische mathematische Simulationen und Auswertungen (Mandelbrot-
& Juliamengen etc) und alle Musikstudios verwenden ausschließlich unkomprimierte
Sounds, also WAV-Dateien.
Warum sind diese Formate aber Platzverschwendung?
Dazu muss man sich den Aufbau genauer ansehen. Alle diese Dateiformate
lassen einen gewissen Spielraum für Abstufungen / weitere Inhalte,
die sich nur minimal von den anderen unterscheiden bzw ein breites Spektrum
anbieten. So können Bitmap-Grafiken bis zu 64 Millionen Farben pro
Pixel (Bildpunkt), Text bis zu 65.536 verschiedene Zeichen und Sounddatein
Töne
in jedem Frequenzbereich ohne Einschränkung abspeichern. Wie sieht
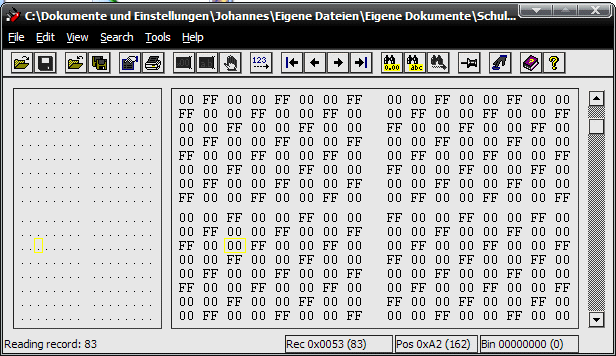
das aber nun in einer Datei aus? Schauen wir es uns an einer Bilddatei
an. Die Farbinformationen erhält man nur wenn man die Datei im Hexadezimalcode
darstellt. Anstatt Hexadezimalcode könnte man auch Binärcode
verwenden, da dieser aber unübersichtlicher ist und wesentlich mehr
Platz zur Darstellung benötigt verwende ich den Hexadezimalcode. Diesen
Code kann man sich mit dem kleinen Tool fxEdit (siehe Internet-Links) anzeigen
lassen, welches ich auch für meine Screenshots verwende.

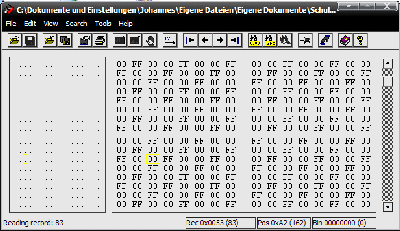
Wer eine langsame Internetverbindung hat oder der Schulserver gerade mal
ein wenig überlastet war, der wird gemerkt haben, dass das rein blaue
Bild sehr lange zum Laden benötigt hat. Immerhin ist dieses Bild mit
der geringen Auflösung von 400* 300 Pixel 300 kb groß. Schaut
man sich den Aufbau an erkennt man, dass für jedes Pixel 3 Byte verwendet
werden (diese BMP ist auf 16 mio Farben eingerichtet), obwohl immer wieder
der gleiche Inhalt da ist. Dieser 3-Byte-Code ist schon sehr alt und heißt
RGB-Code. es lassen sich alle Farben aus den 3 Farben rot, grün und blau
zusammensetzen. in diesem Beispiel sind rot und grün auf 00 gesetzt und
blau auf das Maximum von FF (meist 255 - ist das gleiche) gesetzt. Man
erhält ein reines blau.
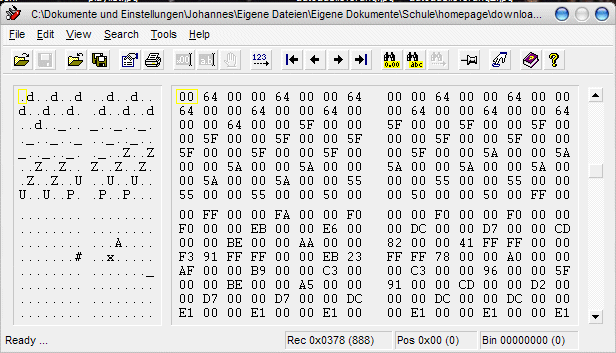
Ein weiteres Beispiel für eine Bitmap-Grafik, bei der aber die fehlende
Kompression nicht so stark ins Gewicht fällt:
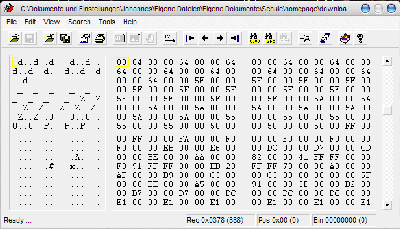
Da hier sehr viele verschiedene Farben verwendet werden sind die bestimmten
RGB-Kombinationen seltener vertreten und immerhin bis zu 75000 der 16 mio
möglichen Farben verwendet. Es lässt sich aber immer noch eine Möglichkeit
erkennen diese Datei zu komprimieren - so sieht man auf dem Screenshot
noch sehr häufig die Kombination 00.
Die älteste computertechnische Komprimierung - das RLE - die Lauflängenkodierung
(Run Length Encoding)
Dieses Verfahren wird heute nur noch sehr selten eingesetzt, maximal noch
durch Kompressionsprogramme wie WinZip oder WinRAR wenn es sich anbietet.
RLE ist denkbar einfach: Man nimmt sich eine Zeichenkette die besonders
häufig hintereinander auftaucht und kodiert diese durch 1. die Zeichenkette,
2. die Anzahl der Zeichenketten hintereinander und ein Byte woran man erkennt,
dass die Zahl zu 2. zu Ende ist.
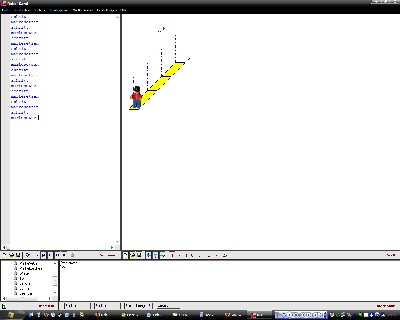
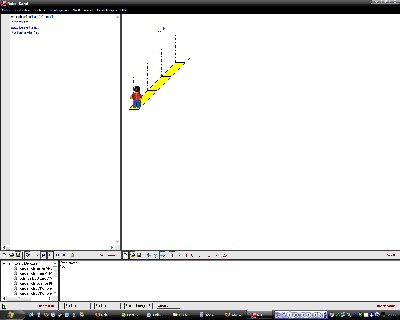
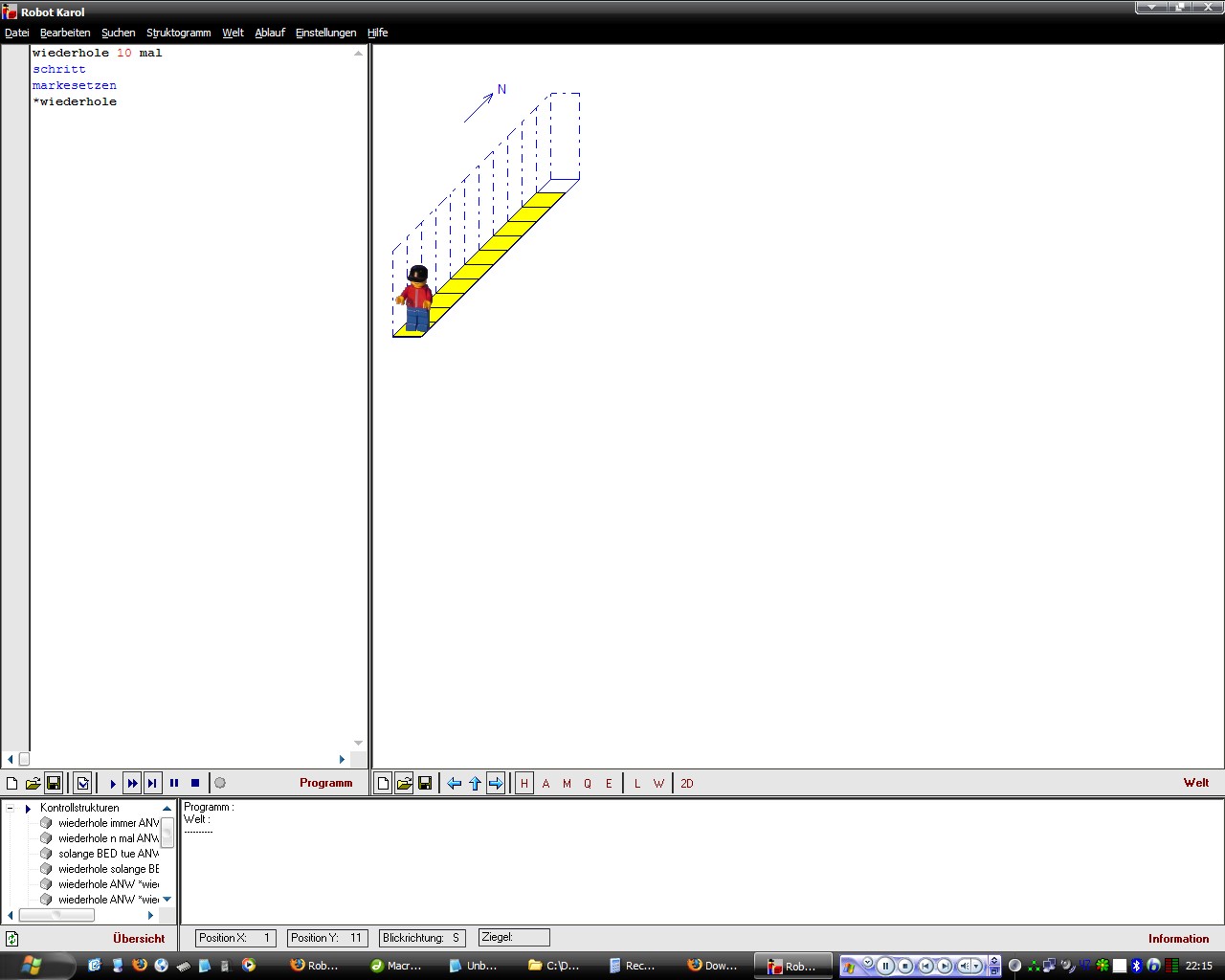
Am einfachsten kann man sich das an einem Männchen vorstellen, dass
man durch die Gegend wandern lassen soll. Robot Karol bietet eine gute
Möglichkeit
das Nachzuvollziehen. Man kann das Männchen 10 Schritte nach vorn
gehen lassen indem man ihm 10 mal hintereinander den Befehl "schritt
vorwärts"
gibt (in Screenshot 1 wird nach jedem Schritt eine Marke gesetzt um
den Schritt darzustellen) bzw. man sagt ihm gehe 10 mal hintereinander
eine schritt nach vorn (und, um es zu verdeutlichen, setze eine Marke),
wie in Screenshot 2 erkennbar ist. So funktioniert RLE.
An unserem Beispiel des blauen Bildes
würde das sehr gut funktionieren (Dateiinformationen wie Header und
Signatur bleiben natürlich wie sie sind): Die Datei besteht aus 400*300,
also 120.000 Bildpunkten - in Hexadezimal wären das 1D4C0. Definieren
wir AA als Endbyte für die Anzahl, so könnte unsere Datei wiefolgt
aufgebaut sein: 00 00 FF 01 D4 C0 AA. Dies ist schon wesentlich kürzer
als die originalen 300 Kilobyte. Ich wiederhole nocheinmal: der Dateiheader
mit Informationen zu Auflösung
und Farbtiefe des Bildes kommt natürlich noch dazu, ebenso wie die
Dateisignatur am Ende.
RLE wurde viel eingesetzt als nur monochrome Bilder möglich waren. Heute
hat diese Kompression aber weitestgehend an Bedeutung verloren, da die
Farbtiefe und Detailreichtum von Bildern eine so starke Wiederholung einfach
nicht mehr zulässt. Texte sind sowieso schwer per RLE zu komprimieren,
da selten sehr oft der gleiche Buchstabe hintereinander auftaucht.
Wörterbücher - Bäume - wovon bitte redet der hier? Begriffe
rund um die Kodierung
Kodierung & Komprimierung - wo ist da jetzt der Unterschied? Komprimierung
heißt etwas verdichten, d.h. die gleiche Menge von etwas nimmt nach der
Kompression (=Komprimierung) weniger Platz / Raum / Volumen ein. In der
Informatik realisiert man das, indem man die zu komprimierenden Daten kodiert.
Kodieren hat hier weniger etwas mit verschlüsseln zu tun, sondern eher
mit umwandeln. Nartürlich sind kodierte Daten schwerer lesbar als die originalen,
da aber die Verfahren in der Datenkompression allgemein bekannt sind zählt
diese Art der Kodierung nicht zu den Verschlüsselungen.
Für alle Kodierungen und Komprimierungen benötigt man ein Wörterbuch.
Dieses variiert für jede Kodierung. Dafür gibt es grundsätzlch 3 Möglichkeiten.
Zum einen kann es einmal bei der Kodierung erzeugt werden und mit abgespeichert
und beim Zurückübersetzen ausgewertet werden. Die andere Möglcihkeit ist
die Generierung des Wörterbuchs sowohl beim Speichern als auch beim Öffnen
der Datei. Die letzte Variante wird sehr selten verwendet, da sie nicht
Eingabewort-spezifisch sondern allgemein ist. Gemeint ist ein Standard-Wörterbuch,
dass immer verwendet wird und auf jedem System als Grundlage vorhanden
sein muss. Ein praktisches Beispiel für ein solches System ist der Morse-Code.
Wenn solche Wörtbücher übertragen werden müssen dann speichert man sie meist
nach Codes sortiert, da dann das auffinden sich erleichtert.


 Alle
Mandelbrot-Grafiken bereitgestellt von André Neubert Klassenstufe
12,
Alle
Mandelbrot-Grafiken bereitgestellt von André Neubert Klassenstufe
12,