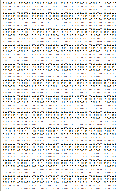| Kryptoanalyse mit dem Geocacher-Team haensel+gretel - Teil I - von CÄSAR bis Playfair - einfache Verfahren |
|
|
Letztmalig dran rumgefummelt: 19.12.16 07:52:20 |
|
Kurz paar Worte vorweg zu unserem
kleinen Seminar. So was hab ich letztes Jahr schon mal mit paar
Cacherkollegen gemacht und das hat ganz gut funktioniert. Allerdings waren
das nur vier Leute, die natürlich etwas einfacher unter einen Hut zu
bekommen sind als unsere jetzige Truppe mit elf Leuten. Aber wir werden das
schon hinbekommen. Da ich keine Ahnung habe, auf welchem Kenntnisstand ihr
seid und wie viel Zeit ihr für diese Aktion erübrigen könnt, schlage ich
vor, dass ich einfach mal bei Adam und Eva, also ganz am Anfang mit den
Basics beginne - auch auf die Gefahr hin, dass sich manche vielleicht
langweilen werden. Ich teile den Stoff in einzelne Mails auf und schicke
jeweils ein Häppchen ungefähr einmal pro Woche rum. Falls jemand nicht
genügend Zeit dafür hat, einfach die Bremse rein hauen, dann machen wir
etwas langsamer. Kann auch sein, dass es bei mir mal zeitlich hakt, weil ich
beruflich doch ziemlich eingespannt bin. Wir können auch mal eine Weile
aussetzen. A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Z Y X W V U T S R Q P O N M L K J I H G F E D C B A
Noch
gschwind zum geplanten Inhalt. Wir werden mit wenigen Ausnahmen nur die
klassischen Verfahren besprechen. Dabei wird es nur um die gängigsten
Varianten gehen, Spezialfälle und exotischere Verfahren können wir später
besprechen, falls Interesse daran besteht. Neuere und insbesondere
asymmetrische Verfahren werden keine Rolle spielen (die sind beim Cachen
normal auch unwichtig). Zunächst wird es um die Substitutionsverfahren gehen
- zunächst die monoalphabetische Substitution. Vermutlich kennen das die
meisten bereits (z.B. ROT13, Caesar), aber für alle Fälle gehen wir das
trotzdem kurz durch. Dann folgt die polyalphabetische Substitution (z.B. von
Vigenčre haben die meisten wahrscheinlich zumindest schon mal was gehört).
Anschließend kommt dann die Transposition dran (z.B. Spaltentransposition,
Palisade, Sägezahn). Schließlich streifen wir kurz die beim Cachen
wichtigsten Codes (z.B. ASCII, CCITT2, Kenny-Code). Wenn es euch dann immer
noch nicht zu viel geworden ist, können wir uns speziellen Systemen wie den
bipartiten Substitutionsverfahren (z.B. Polybios oder Playfair), den
kombinierten Verfahren (z.B. ADFGVX oder Sorge-Chiffre), den Spezialfällen
wie Rastersystemen (z.B. Fleißner) oder auch der Steganographie zuwenden.
Gelegentlich, wenn auch selten, begegnet man diesen Dingen beim Cachen.
Werden wir ja sehen. Hört sich jetzt wahrscheinlich auch erst mal wilder an,
als es eigentlich ist. |
|||||||
|
1. Basic BASICS 2. Monoalphabetische Substitution 3. CRYPTOOL 4. Systematik bei der Kryptoanalyse einer monoalphabetischen Substitution 5.Systematik bei der Kryptoanalyse einer polyalphabetischen Substitution 6. Dechiffrierprojekt Vigenčre-Code Informatik-Kurs 2006/07 7. Web-Links zum Thema Vigenčre und Polyalphabetischer Chiffre 8. Aufgaben zum Thema Kasiski-Test 9. Verwandte Themen |
|||||||
|
|||||||
| Quellen: | |||||||
|
| 1. Basic BASICS - also die Grundlagen der Grundlagen |
|
|
|
|
Also jetzt aber los. Die Kryptologie gliedert sich in die Kryptographie (also das Verschlüsseln) und die Kryptoanalyse (also das Brechen von Krypttexten, was nichts anderes bedeutet als ein Entziffern, ohne dass man zunächst den Schlüssel hat). Uns interessiert hier natürlich vornehmlich die Kryptoanalyse. |
|
|
Das Brechen eines Krypttextes besteht immer aus vier Schritten: 1. verwendete Sprache identifizieren 2. verwendetes Verfahren identifizieren 3. Schlüssel ermitteln 4. Krypttext entziffern Dabei kann man die Schritte nicht immer streng nacheinander abarbeiten. Häufig muss man hin- und zurückspringen, vor allem am Schluss zwischen Schritt 3 und 4. Die ersten beiden Schritte aber müssen immer am Anfang stehen. Ohne das Verfahren zumindest grob zu kennen (Schritt 2), bleibt die Sache ein reines Glücksspiel. Den ersten Punkt können wir in der Regel überspringen und einfach von deutschen Texten ausgehen. Beim Identifizieren des verwendeten Verfahrens wird es schon wesentlich schwieriger - das ist meist der Hauptknackpunkt. Darauf werden wir später noch ausführlicher zu sprechen kommen müssen. Es gibt eine unübersehbare Vielfalt von Verschlüsselungsverfahren. Ganz grob unterscheidet man die klassischen Verfahren von den modernen. Die klassischen kann man im Prinzip mit Papier und Bleistift durchführen, die modernen basieren auf der digitalen Datenverarbeitung und erfordern Computerunterstützung. Dennoch ist der Computer natürlich auch bei den klassischen Verfahren eine große Hilfe und erspart einem viel mühevolle Handarbeit. Wir werden uns hier nahezu ausschließlich mit den klassischen Verfahren beschäftigen. Ganz grundsätzlich kann man bei diesen Verfahren neben diversen Sonderformen zwei Grundtypen unterscheiden:
An dieser Stelle nur eine ganz kurze Erklärung, später mehr dazu: Bei der
Substitution werden die Klarzeichen durch Kryptzeichen ersetzt. Die Zeichen
behalten also ihren Platz in der Zeichenkette, werden aber zu anderen
Zeichen. Bei der Transposition verändert man die Position der Zeichen in der
Zeichenkette, die Zeichen an sich bleiben aber unverändert erhalten. Sie
sind eben nur anders angeordnet. |
| 2. Monoalphabetische Substitution |
|
|
|
|
|
Zunächst beschäftigen wir uns
mit der Substitution. Bei der Substitution ersetzt man wie gesehen die
Klarzeichen durch andere Zeichen. Ich sage hier bewusst "Zeichen" und nicht
"Buchstaben", weil man prinzipiell natürlich jedes nur erdenkliche Zeichen
verwenden kann (z.B. Freimaurer-Code, Morsezeichen, Blindenschrift,
beliebige Symbole) - am üblichsten sind aber freilich Buchstaben. Nehmen wir
uns zunächst die monoalphabetische Substitution vor. Was das genau bedeutet, besprechen wir später. |
|||
|
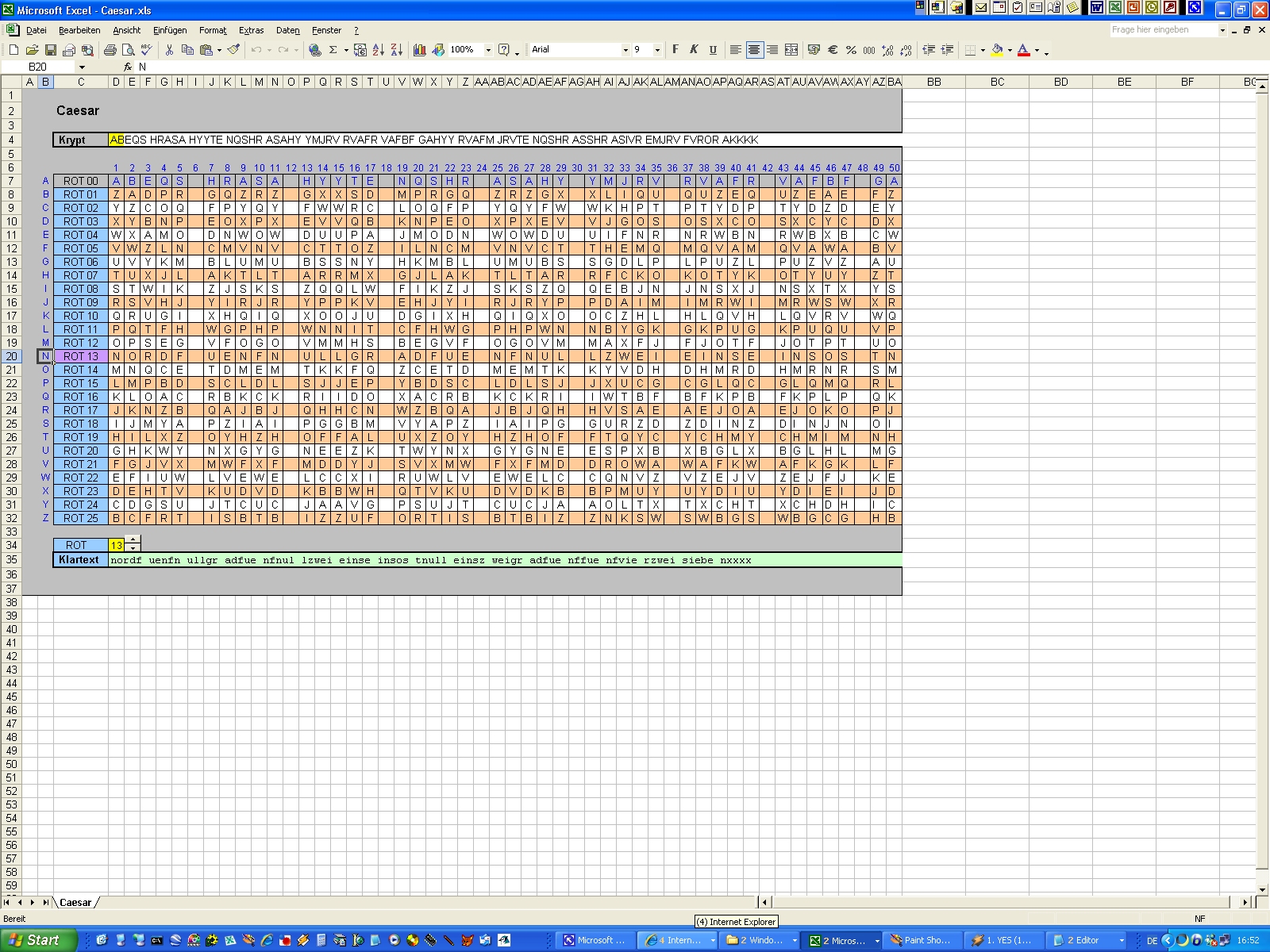
Klassischer CAESAR Der Klassiker der
Substitution und gleichzeitig das einfachste aller Substitutionsverfahren
ist der Caesar-Code. Das ist die wohl jedem Cacher wohlbekannte
ROT-Geschichte. Das antike Caesar-Verfahren im engeren Sinne ist ROT3
(Verschiebung um drei Zeichen, aus "A"
wird also "D" etc.). Für die Hints
beim Cachen ist dagegen wie bekannt ROT13 üblich (Verschiebung um 13
Zeichen, aus "A" wird also "N"
etc.).
Alles ganz einfach. Wobei die Mathematik hierbei für unsere Zwecke nicht
ganz so wichtig ist. Wer damit also auf Kriegsfuß steht, überliest es
einfach. Eine kleine Sache fehlt aber noch: Wenn man bei der Rechnung das
Alphabet verlässt, steigt man vorne (bzw. hinten) wieder ein. Soll "Y" beim
Verschlüsseln um vier Stellen nach rechts verschoben werden, landet man
natürlich hinter dem "Z". Man springt nach dem "Z" einfach wieder zum "A".
Bei einer Verschiebung um vier Stellen wird aus "Y" also "C". Man denkt sich
das Alphabet praktisch als ringförmige, endlose Zeichenkette. Mathematisch
gesprochen führt man eine Modulo-Rechnung durch. A B C D E F G H I J K L M
Hieraus ergeben sich nun diverse Schlussfolgerungen: Beispiel:
Im Hintergrund befinden sich mitunter Hilfszellen oder Matrixformeln. Passt also etwas auf, wo ihr hinklickt. Will man auf Nummer sicher gehen,
lässt man alles außer den gelben Feldern in Ruhe. |
||||
|
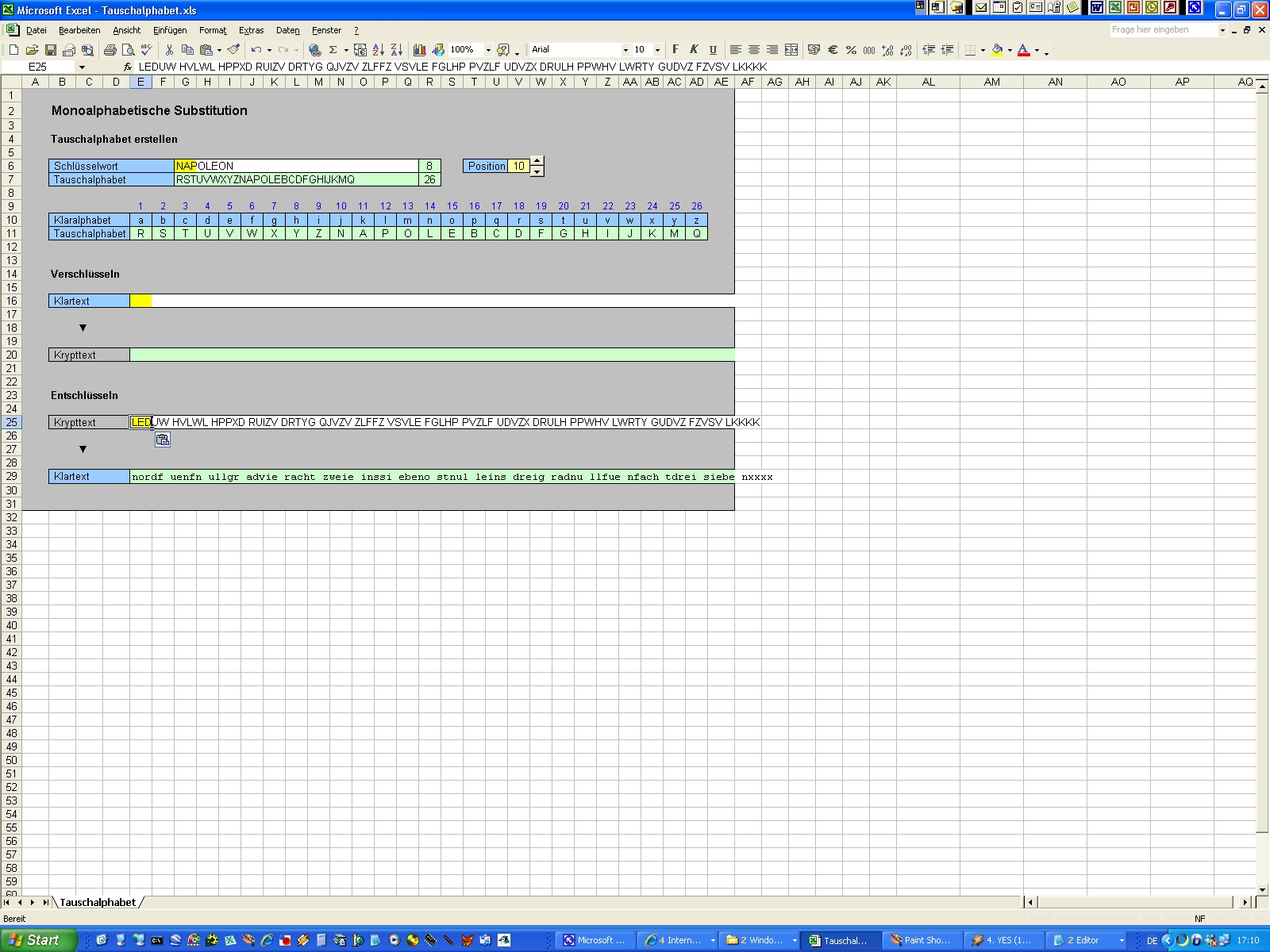
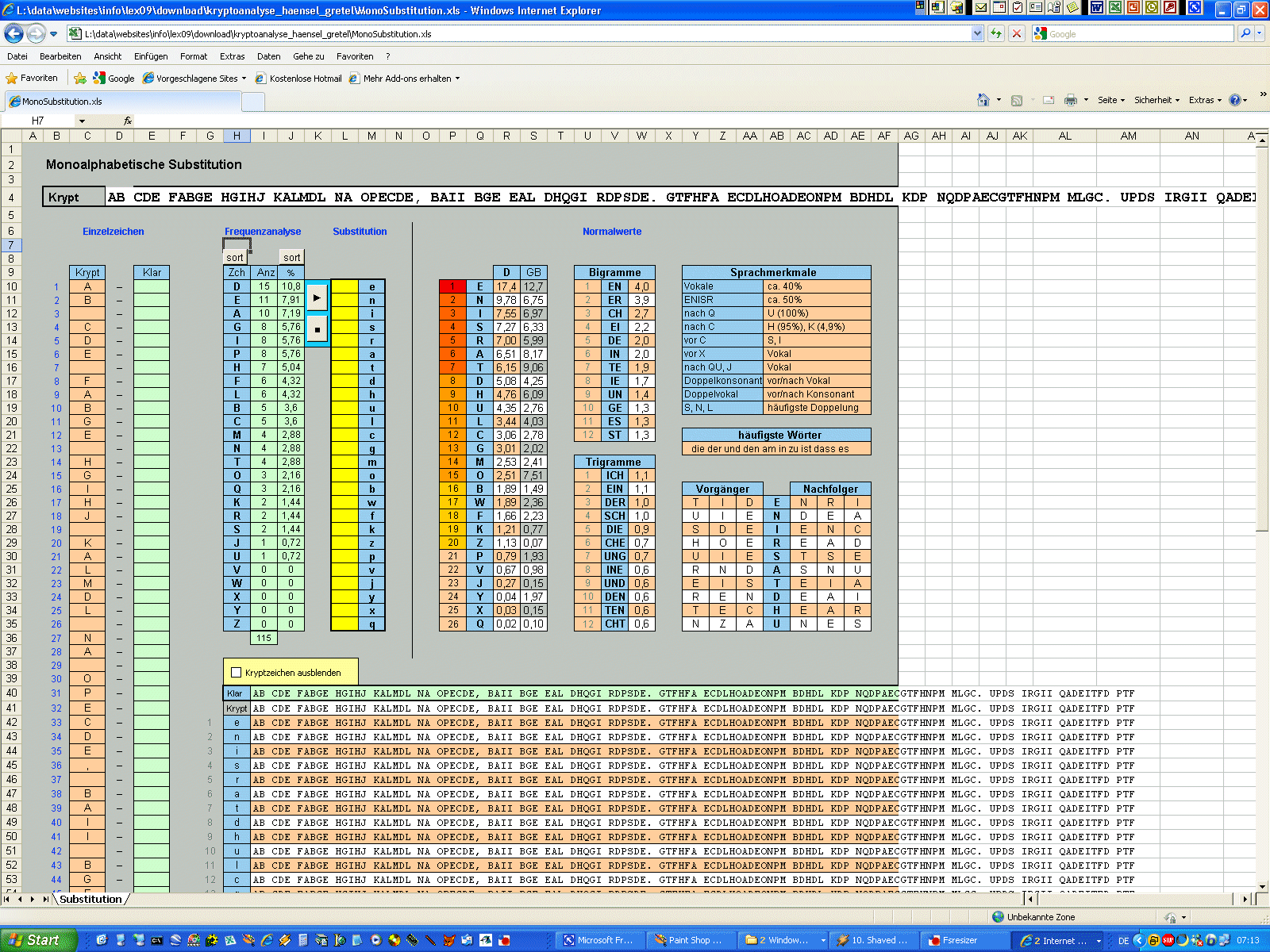
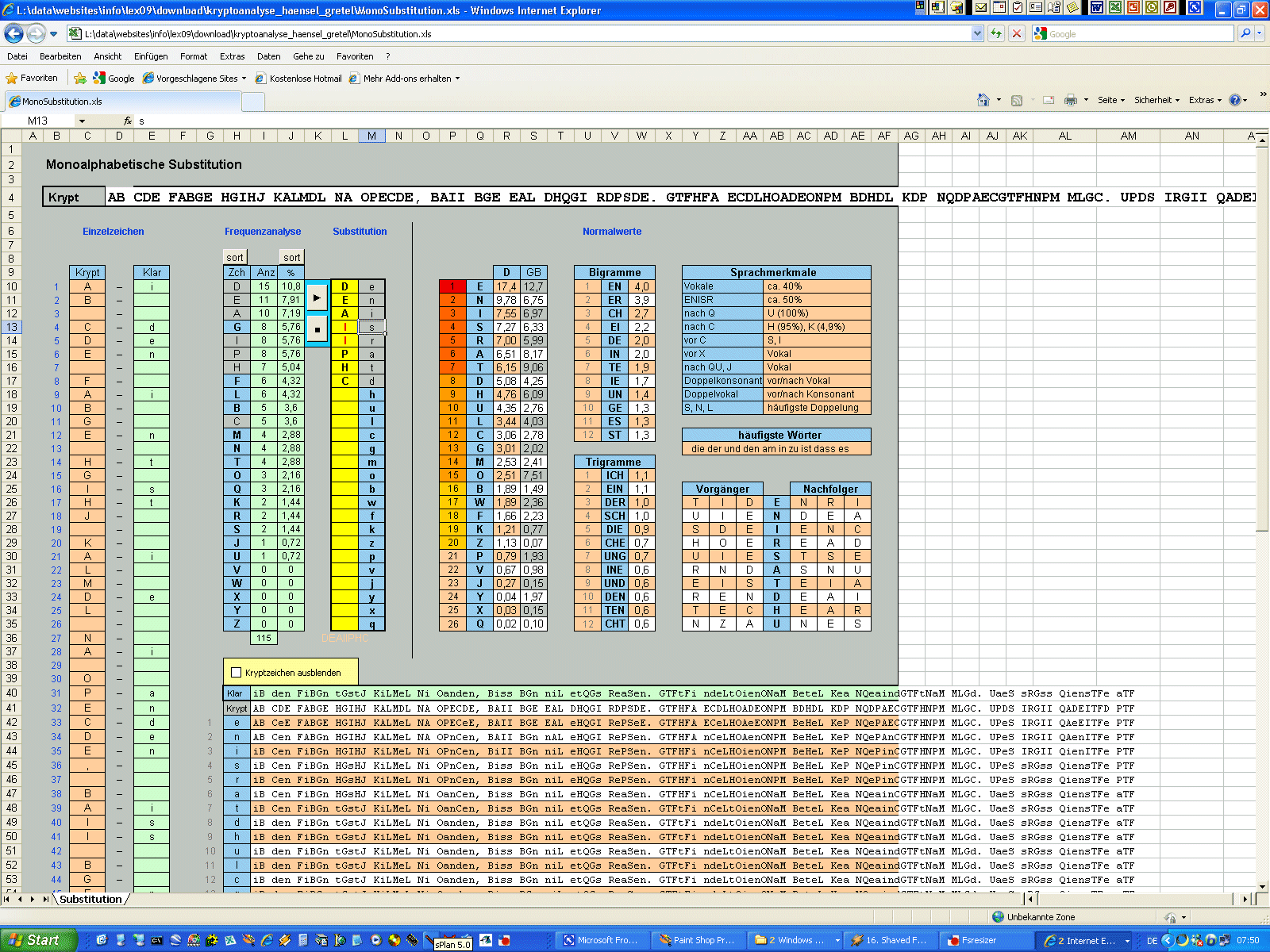
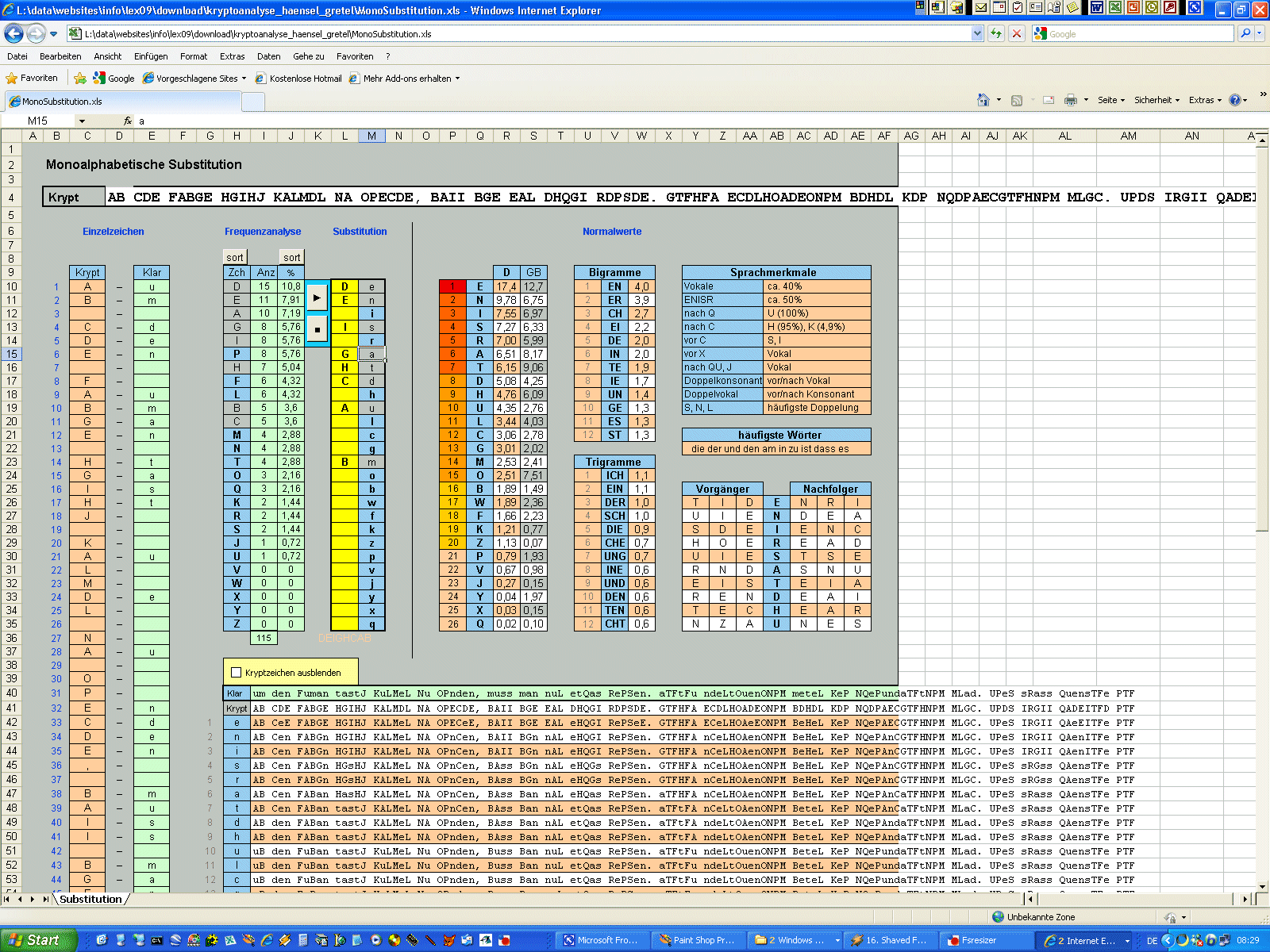
allgemeine monoalphabetische Substitution Die nächste Stufe der Substitution nach dem Caesar ist die allgemeine monoalphabetische Substitution, die allerdings bereits seit den Sumerern bekannt ist. Hierbei verschiebt man nicht jedes Zeichen um den gleichen, festen Betrag, sondern ordnet jedem Buchstaben frei ein Ersatzzeichen zu. Beispielsweise kann man für "a" den Ersatz "K" wählen, für "b" nimmt man "W", für "c" setzt man "F" etc. Auf diese Weise erstellt man also ein ungeordnetes Tauschalphabet. Wichtig ist dabei nur, dass jedes Klarzeichen ein anderes Kryptzeichen erhält, sonst ist eine Entschlüsselung nicht eindeutig möglich. Es gilt also wie beim Caesar, dass der Zeichenvorrat von Klartext und Krypttext genau gleich groß ist. Für unser eben genanntes Beispiel sieht der Anfang der Ersetzungstabelle also so aus: p a b c ... Das ist schon mal um einiges sicherer als ein Caesar, aber es gibt
dennoch ein paar Probleme damit. Erstens kann man sich nicht mehr so gut
merken, wie man den Krypttext zurück in einen Klartext bringt, denn man muss
ja 26 Zuordnungen kennen. Wohl kaum einer kann sich zuverlässig ein völlig
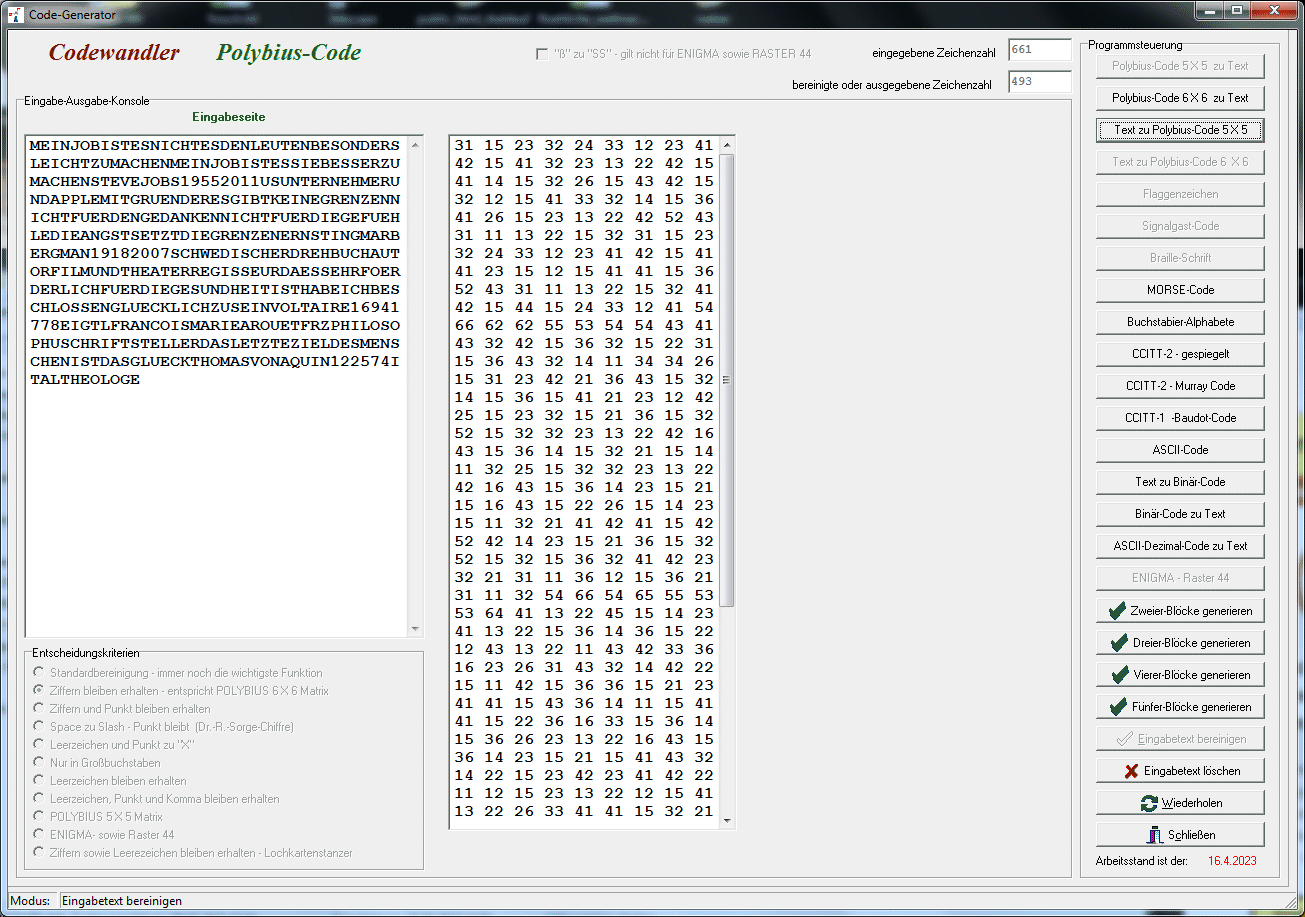
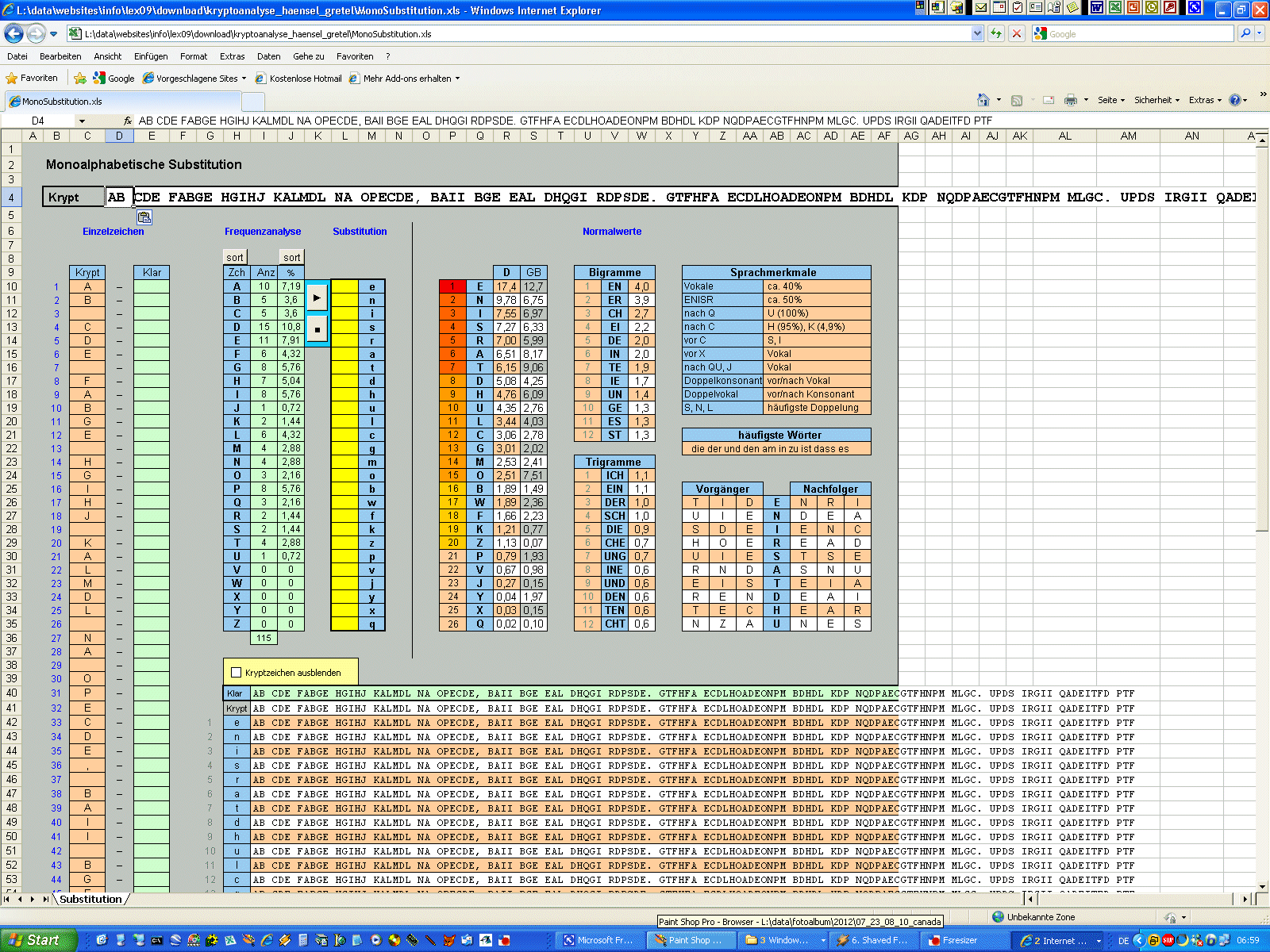
chaotisches Alphabet merken. "a" wird also durch "S" ersetzt, "b" durch "O", "c" durch "N" etc. Im Anhang findet ihr ein kleines Tool, das ein Tauschalphabet erstellt
und damit auch gleich ver- und entschlüsselt. Zusätzlich erlaubt es, das
Schlüsselwort beliebig im Tauschalphabet zu positionieren. Manchmal ist das
notwendig. Wir werden noch ein solches Beispiel kennenlernen. |
||||
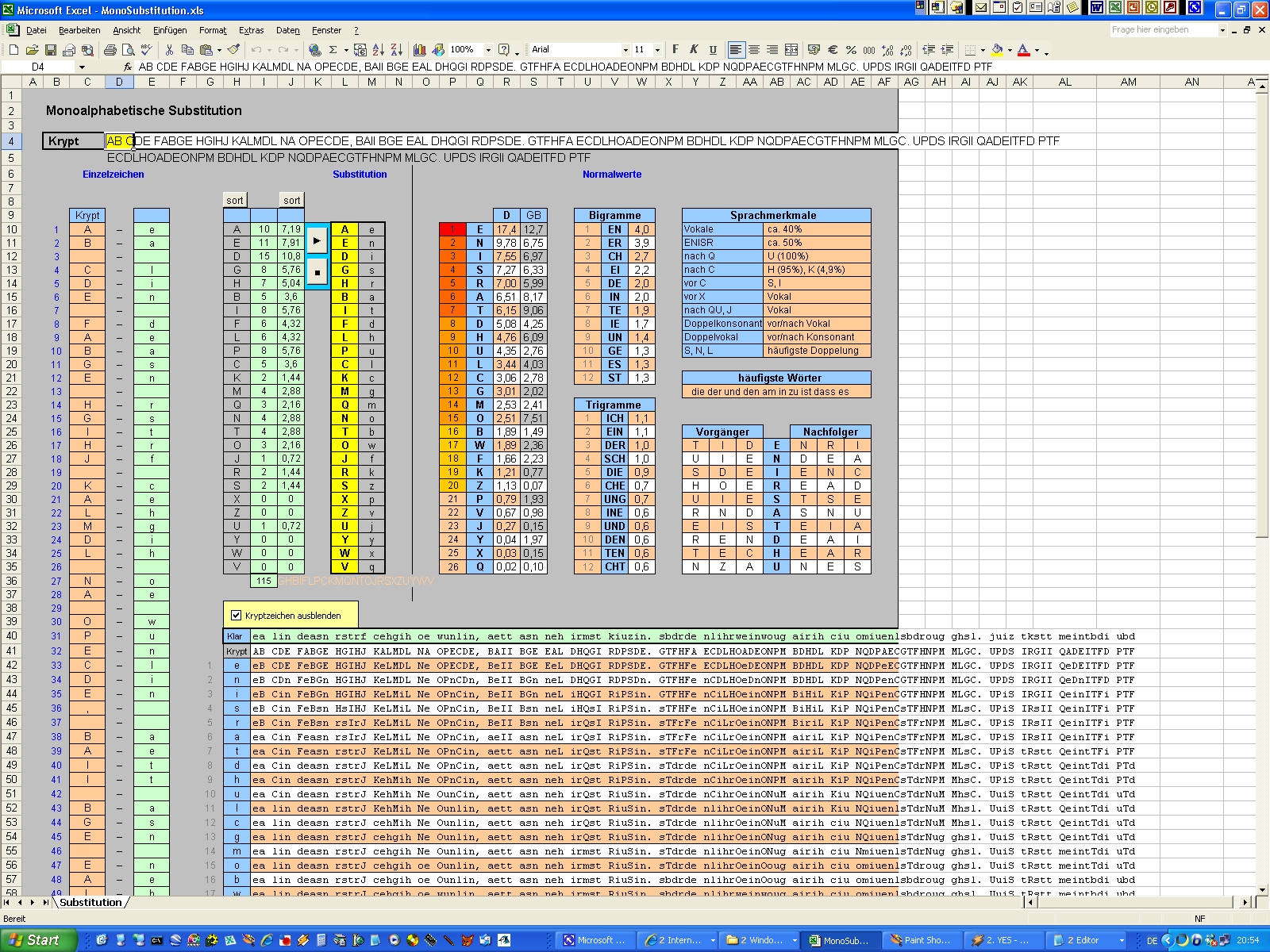
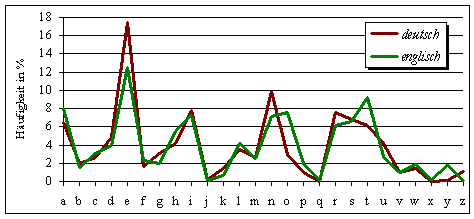
Normalverteilung
Die Normalverteilung,
also die "normale" Häufigkeit der einzelnen Buchstaben, ist bei der
Kryptoanalyse ein ganz zentrales, allerdings auch etwas heikles Thema. In
der Kryptoanalyse nennt man das Auszählen der Häufigkeiten der Zeichen eines
Textes übrigens auch "Frequenzanalyse". |
| 3. CRYPTOOL |
|
|
|
|
|
An dieser Stelle
ein kleiner Exkurs, bei dem ich euch mit einem Werkzeug bekannt machen
möchte, das wir künftig immer wieder brauchen werden. Es handelt sich um das
CrypTool, das vielleicht einige schon kennen. Dieses wirklich starke
Programm gibt es zum Runterladen
http://www.cryptool.org/ct1download/SetupCrypTool_1_4_30_de.exe
oder auch als Online-Version (http://www.cryptool-online.org/).
Es ist das beste mir bekannte, frei erhältliche Werkzeug zur Kryptologie. Das Problem mit dem CrypTool ist allerdings, dass es zwar eine schöne Vielfalt von Verfahren beherrscht, und das in beide Richtungen - man kann jeweils Ver- und Entschlüsseln. Auch paar ganz nette Analysefunktionen stellt es bereit. Doch zum Brechen von Chiffren und Codes ist es nur sehr bedingt geeignet. Für die klassischen Verfahren gibt einige nützliche Funktionen, doch die Auswahl bleibt letztlich doch übersichtlich. Es gibt auch kaum die Möglichkeit, Parameter zu variieren oder hinter den Kulissen herumzuschrauben. Für die Transposition schließlich gibt es nur eine reine Entschlüsselungsroutine, die einem aber rein gar nichts nützt, wenn man den Schlüssel nicht hat. |
|
Daher setze ich das CrypTool nur selten ein, sondern bevorzuge
Excel-Lösungen. Das hat den Vorteil, dass alles sehr leicht und schnell zu
modifizieren ist. Denn grade beim Cachen trifft man sehr häufig nicht auf
die typischen klassischen Verfahren, sondern auf Dinge, die sich die Owner
selbst haben einfallen lassen. Mitunter findet man auch im Prinzip
klassische Verfahren, die die Owner aber - ob nun aufgrund von Unkenntnis,
Missverständnissen oder bewusst - nicht ganz korrekt einsetzen. Da ist dann
auch eine unkonventionelle Herangehensweise gefragt. Oft muss man eher mal
etwas herumprobieren und basteln und rumspielen. Und das erfordert es, die
Tools hierhin und dorthin zu modifizieren oder ein Teilergebnis von einem in
ein anderes Modul zu übertragen. Dabei ist die Excel-Lösung natürlich
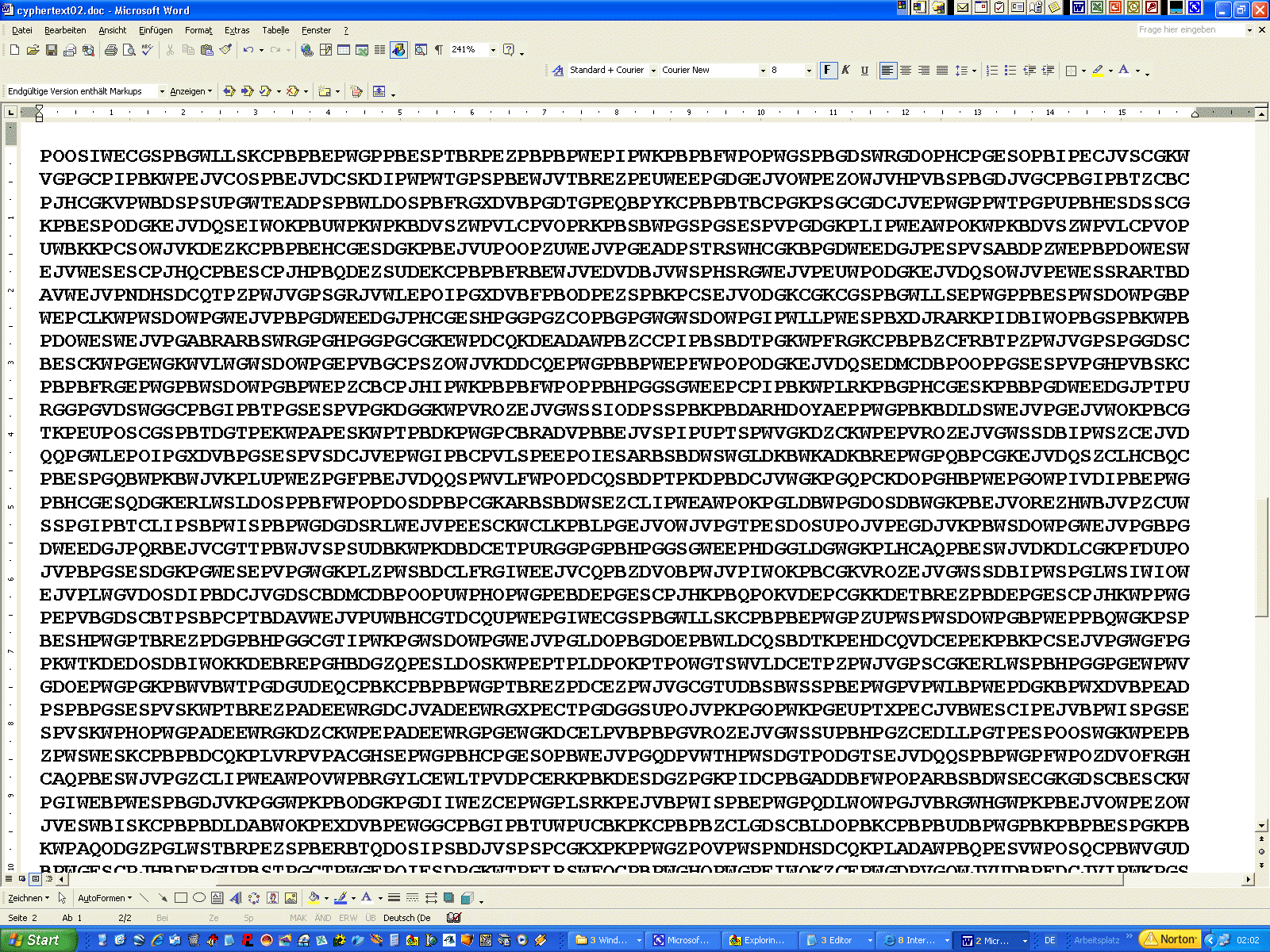
flexibler als ein fixes Programm. Für den Rahmen, in dem wir uns mit unserem kleinen Seminar bewegen, eignet sich aber das CrypTool ohne größere Einschränkungen. Also ladet euch am besten mal das Programm runter und schaut euch darin etwas um. Die Version, auf die ich mich beziehen werde, ist die derzeit aktuelle, oben verlinkte Version 4.30. Das Häufigkeitsgebirge heißt im CrypTool übrigens "ASCII-Histogramm" und ist zu finden unter Analyse/ Werkzeuge zur Analyse/ Histogramm - und ihr werdet zugeben müssen, dass unsere Grafik viel schöner ist ;-), die Zeichenzählung befindet sich unter Analyse/ Werkzeuge zur Analyse/ N-Gramm. Einen einfachen Caesar als Übungsmaterial gibt es hier auch unter dem Menüpunkt "Kryptoanalyse" (http://www.cryptoolonline.org/index.php?option=com_content&view=article&id=55&Itemid=53&lang=de). Den soll man zwar per Frequenzanalyse lösen, aber mit unserem Caesar-Tool sind wir natürlich schneller: CSORK LOXNS OFOBC MRVEO CCOVE XQOBP YVQBO SMRQO UXKMU DOCPY VQDXE XOSXD OHDEO LOBMB IZDYY VEWQO XEOQO XNJOS MROXP EOBOS XOUBI ZDYKX KVICO JEVSO POBXN KCZBY QBKWW MBIZD YYVSC DOSXP BOSOC OVOKB XSXQZ BYQBK WWPEO BGSXN YGCWS DNOWU BIZDY QBKZR SCMRO FOBPK RBOXK XQOGO XNODE XNKXK VICSO BDGOB NOXUY OXXOX NSOCO CYPDG KBOGS BNGOV DGOSD OSXQO CODJD NKLOS EXDOB CDEOD JDCSO OSXOW YNOBX OVORB OKXCM REVOX EXNRY MRCMR EVOXC YGSON SOCOX CSLSV SCSOB EXQFY XPSBW OXKXQ ORYOB SQOX So viel für den Moment - nächstes Mal knacken wir dann einen monoalphabetisch
verschlüsselten Krypttext.
|
| 4. Systematik bei der Kryptoanalyse einer monoalphabetischen Substitution |
|
|
|
|
|
Wie angekündigt brechen wir
heute eine monoalphabetische Substitution. Dazu kommt ein kleines,
praktisches Werkzeug mit, das uns die Sache etwas komfortabler gestalten
wird. Doch macht euch keine Illusionen: Krypttext vorne rein, Klartext
hinten raus geht auch damit nicht. Es wird schon ein Stück Arbeit, bis wir
den Klartext vor uns haben. Drum wird das diesmal auch eine etwas längere
Abhandlung, weil ich das Praxisbeispiel am Stück durchziehen will. Das lässt
sich nicht sinnvoll teilen. Nehmen wir uns zur Demonstration mal einen konkreten Fall vor, nämlich "Die Wiederkehr des Human Tasty Burgers" (www.coord.info/GC263FG). Der ist zwar inzwischen archiviert, aber ist ja wurscht. |
||||||||||||||||||||||||||||||
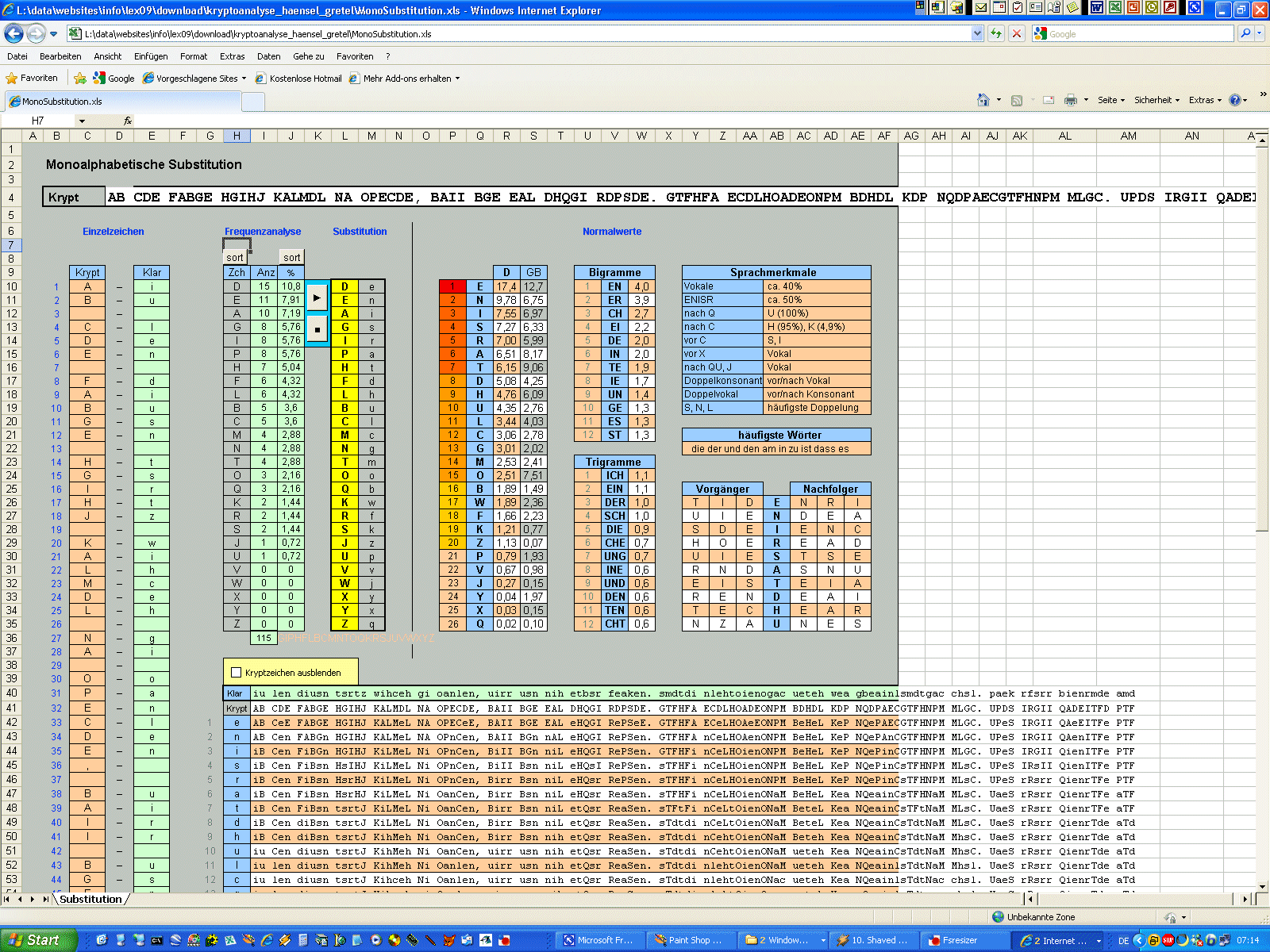
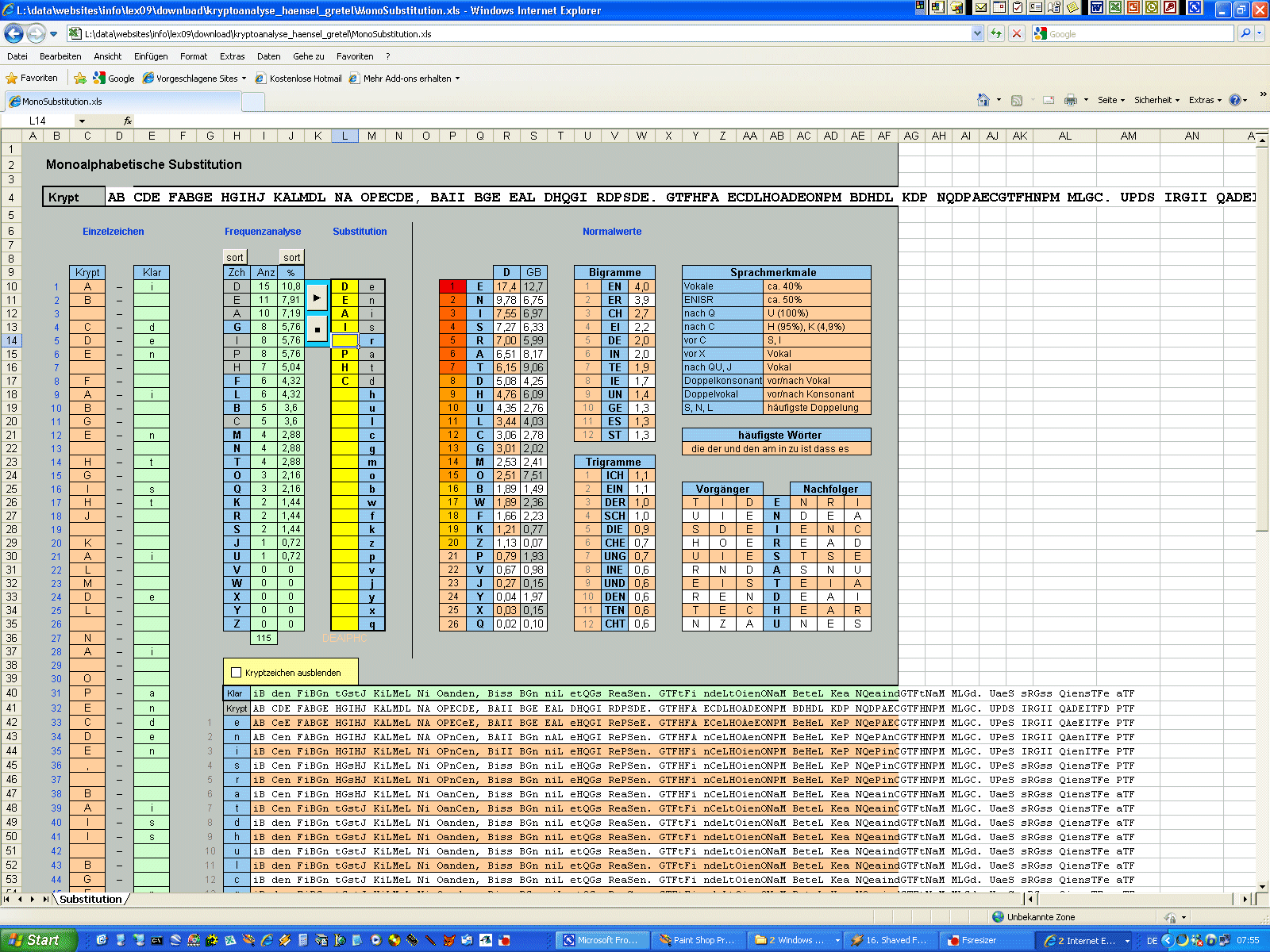
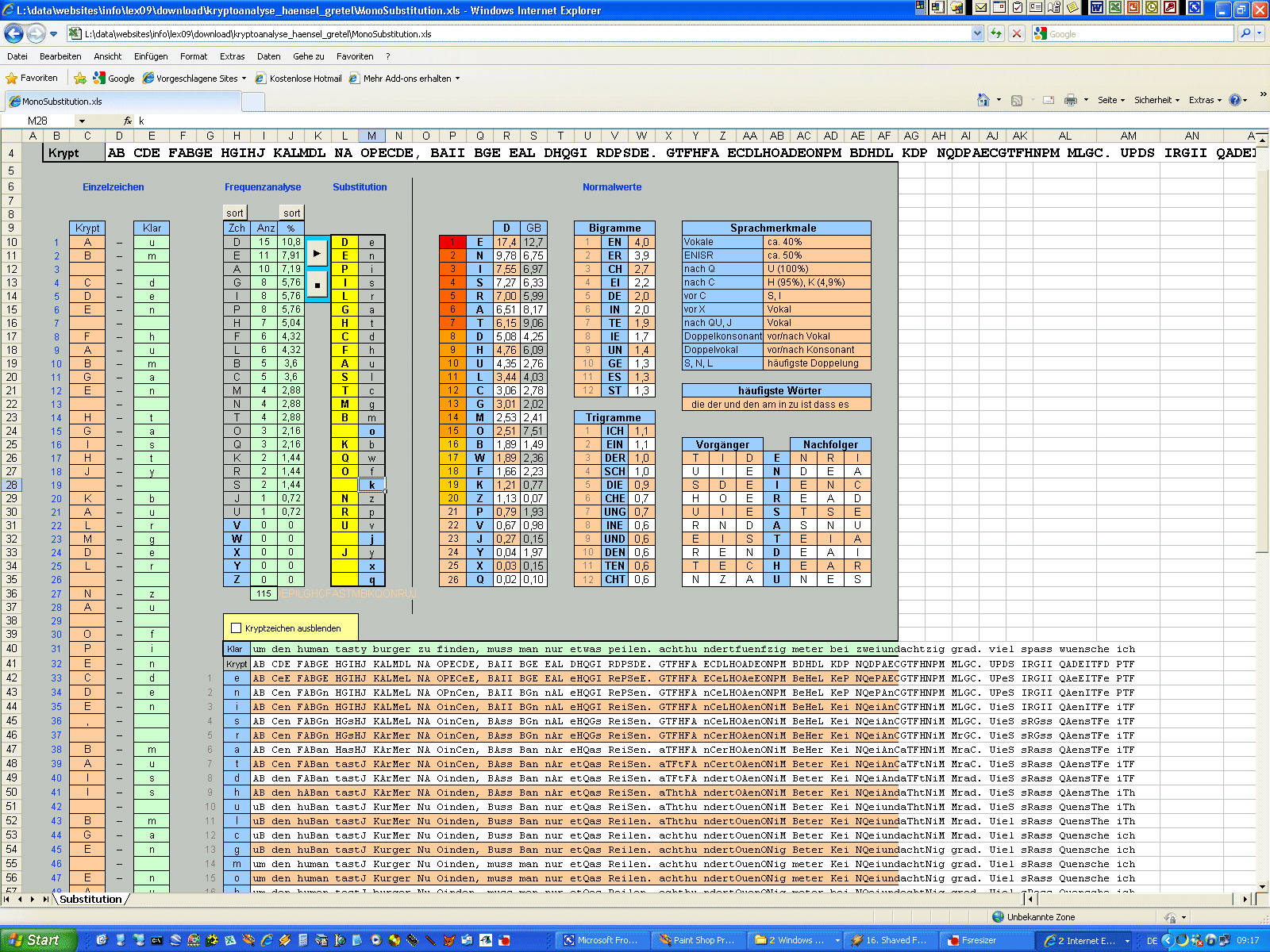
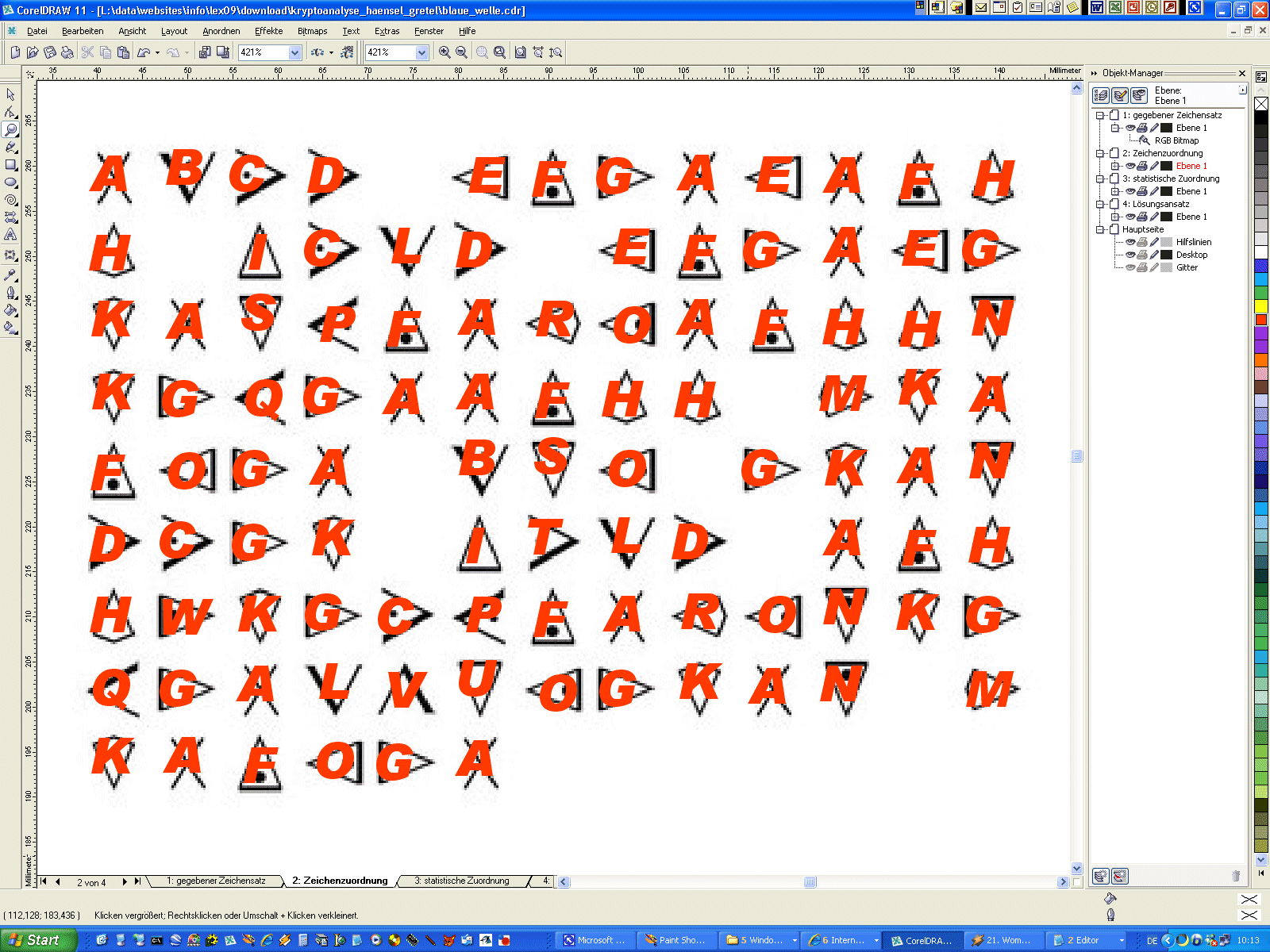
| Zunächst mal sehen wir auf der "Speisekarte" nur wirres Zeug. Schaut man
sich die Zeichen genauer an, wird schnell klar, dass es nicht allzu viele
unterschiedliche sind. Es sind auch Leerzeichen erhalten. Das deutet doch
recht deutlich auf eine simple Substitution hin. Jedes der merkwürdigen
Zeichen steht also wohl für einen Buchstaben. Damit dürfte das kein all zu
großes Problem werden. Randbemerkung: Die Sache ist im Grunde noch viel einfacher, weil es keine echte Substitution ist, sondern nur eine Codierung. Es wurde einfach statt des normalen ein anderer Zeichensatz verwendet. Dieser Zeichensatz heißt "Futurama" und ist im Web leicht zu finden. Aber zu Übungszwecken stellen wir uns erst mal dumm und gehen davon aus, die Sache ohne Kenntnis des Zeichensatzes lösen zu müssen. Zur Herkunft des Cache-Namens siehe http://www.kryptographiespielplatz.de/index.php?aG=3e19d3a084e42d6e4dcf3cd1d23254de039da751. Zunächst wandelt man in Handarbeit die merkwürdigen Zeichen in beliebige
Buchstaben um. Gleiche Zeichen erhalten natürlich immer den gleichen
Buchstaben. Das hab ich hier schon mal für euch erledigt. Das Ergebnis sieht
so aus:
monoalphabetische Kryptoanalyse
Kopiert diesen Krypttext in das Substitutions-Tool rüber. Schauen wir mal,
was hier passiert. In der Tabelle links werden die ersten 60 Zeichen des
Krypttextes als Liste ausgegeben. Diese Liste braucht man nur selten, aber
hin und wieder ist es doch ganz praktisch, auch eine Auswertung auf
Einzelzeichenbasis zu haben. Grade wenn irgendwelche Sonderzeichen
Schwierigkeiten machen, kann man hier am besten die Spur zum Problem
aufnehmen.
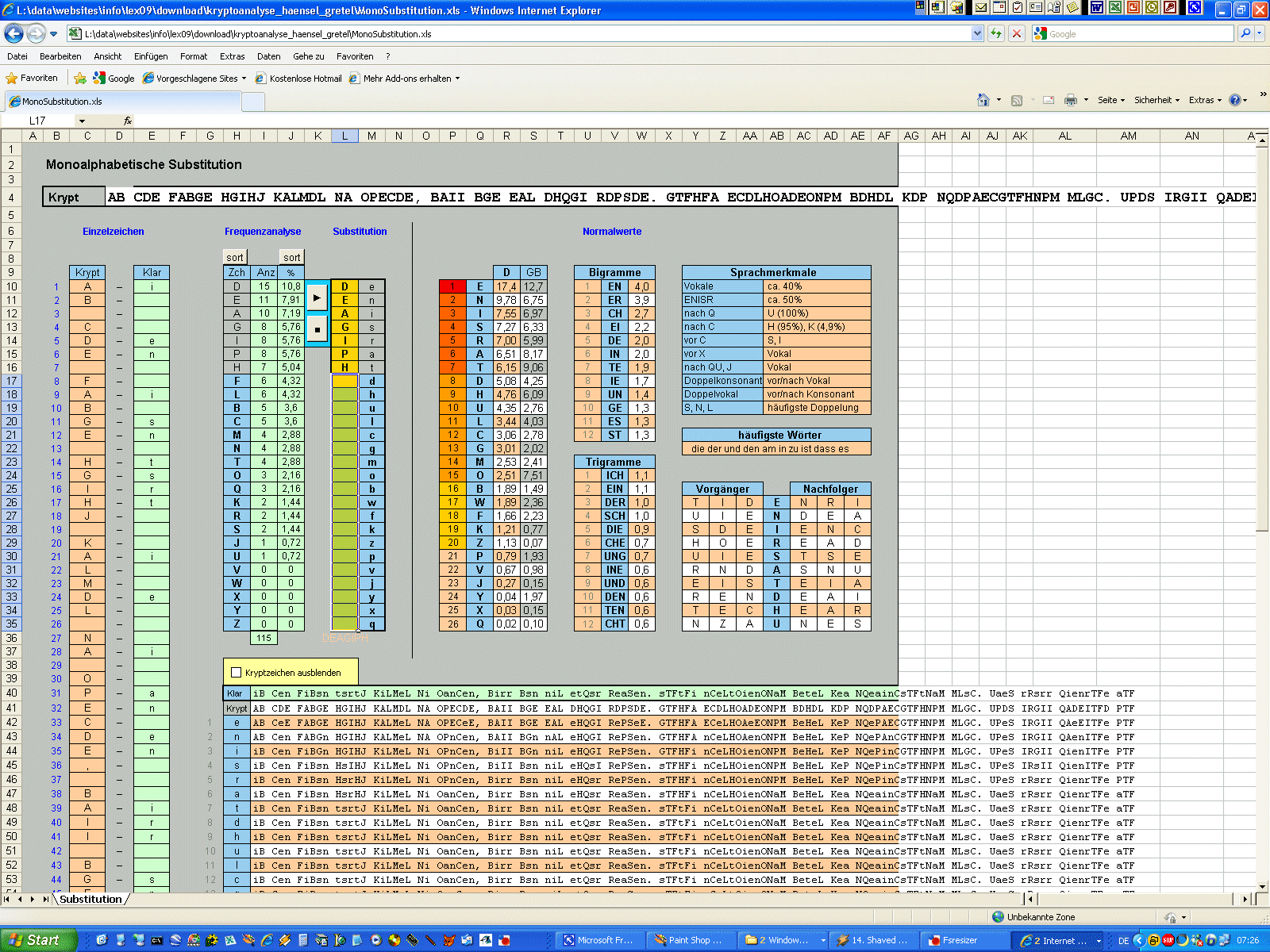
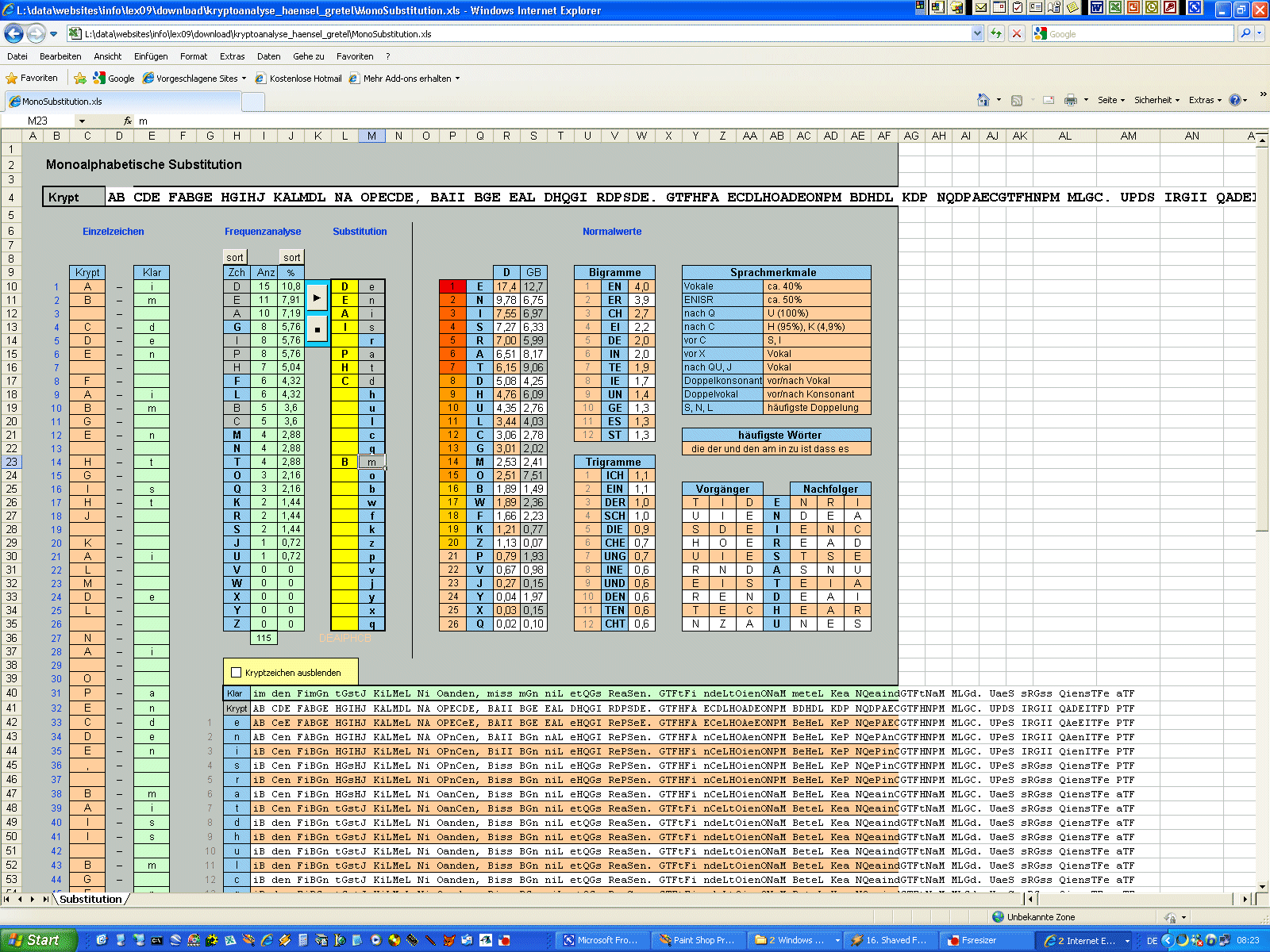
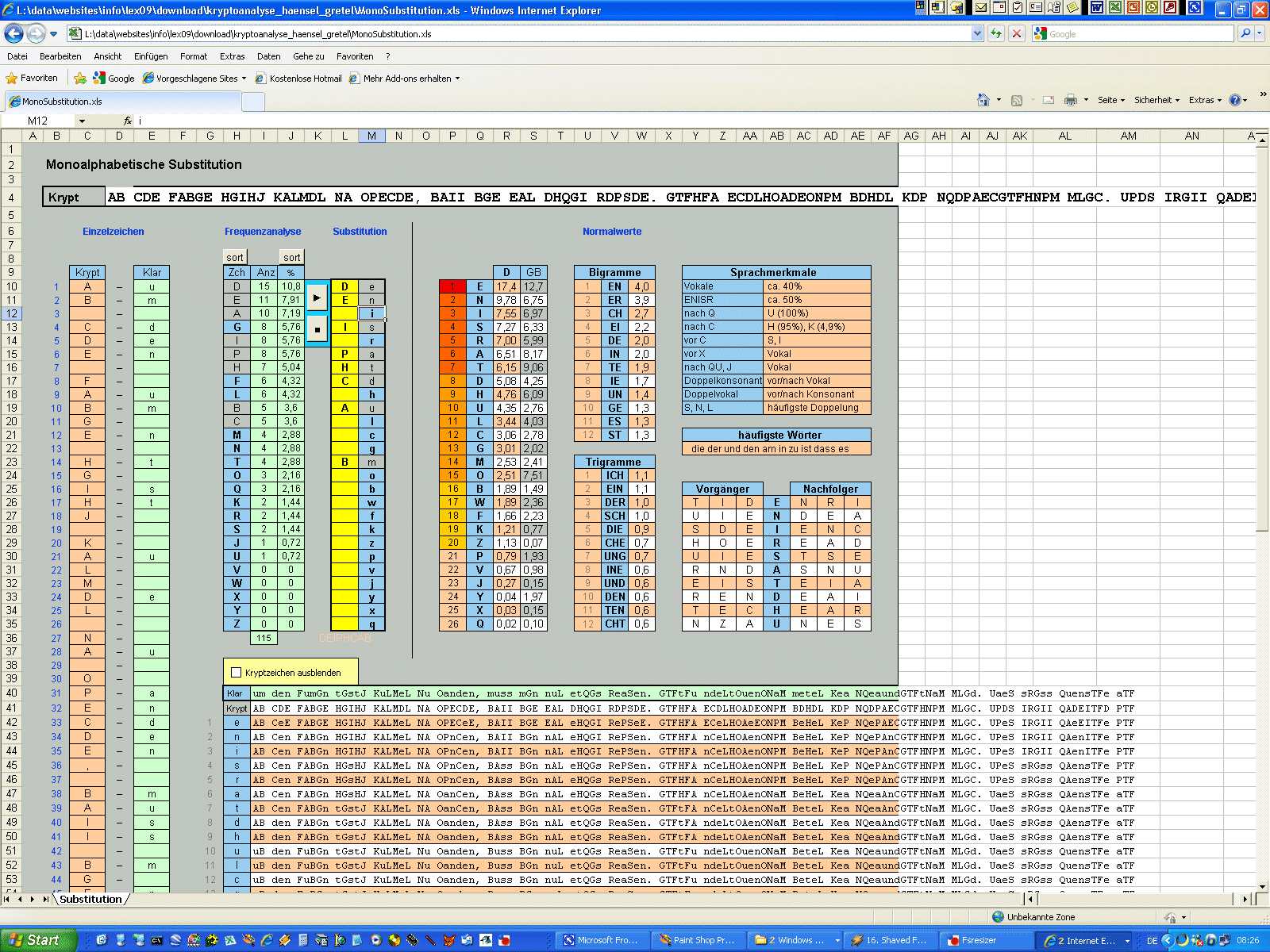
http://www.kreuzwort-raetsel.net/suche.php?m=lueckentext Für den Moment erscheint mir „muss“
als am plausibelsten. Also mal links neben
„m“
das „B“
eintragen und neben
„u“
das „A“.
Das „A“
ist doppelt, wie die rote Färbung zeigt, also das
„A“
beim „i“ löschen.
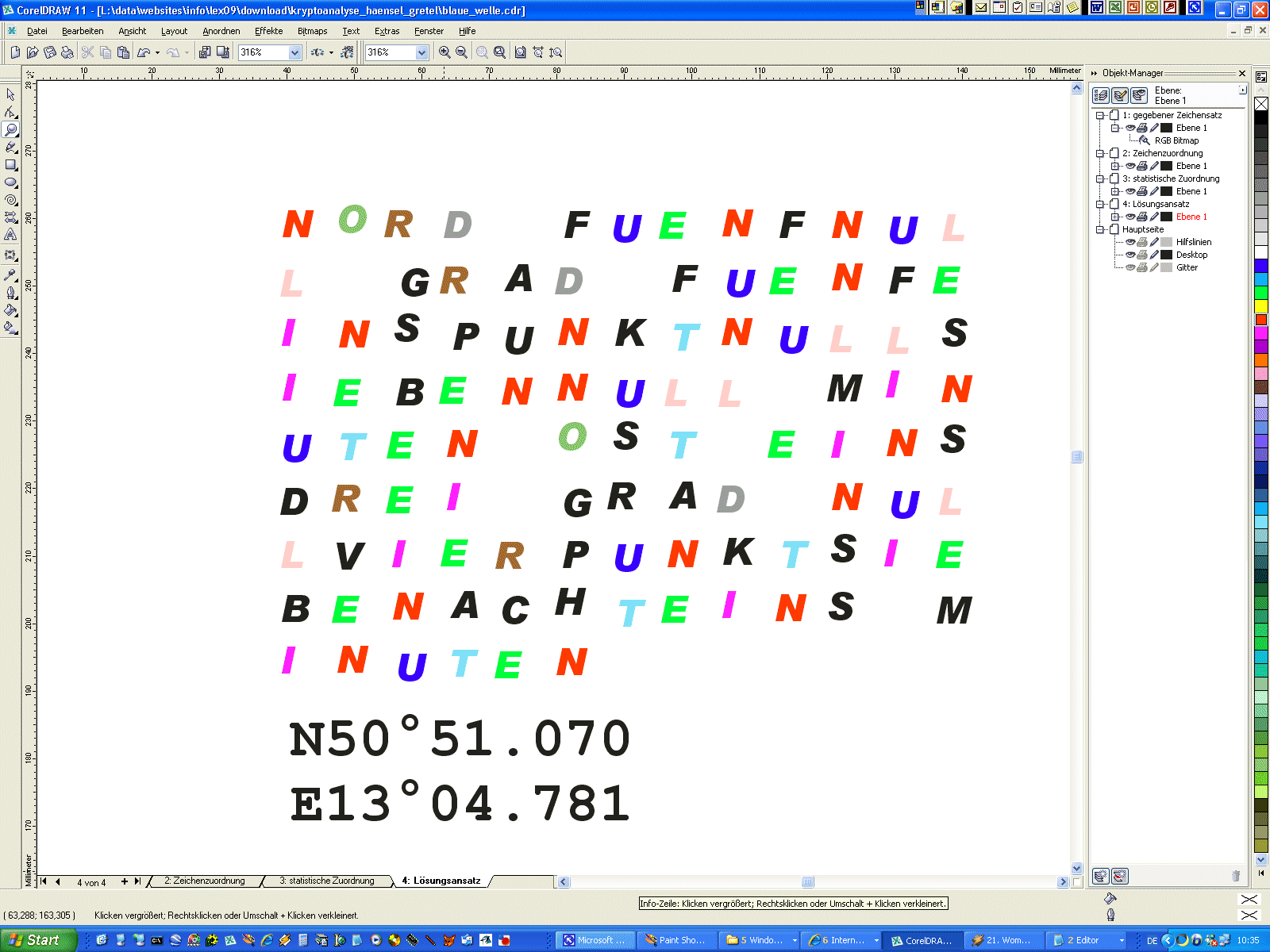
Na, das sieht doch schon gar nicht so schlecht aus. Als erstes Wort ergibt
sich „um“, nicht unplausibel. Nach dem "muss“
kommt „m-n“.
Könnte „man“
sein. Also für „a“
das „G“
statt dem „P“
eintragen. Ha, das sieht doch richtig gut aus. Es ergeben sich eine
ganze Reihe von Ansatzpunkten, um weiterzukommen. Gleich am Anfang kann man
vermuten, dass hier der Cache-Titel stehen muss:
„um den human tasty burger“.
Das 15. Wort
„BDHDL“
sieht schwer nach „meter“ aus. Nach und nach ergibt sich eins aus dem
anderen. Früher oder später gibt der Knoten nach.
Wir haben den Text geknackt - auch ganz ohne Kenntnis des Zeichensatzes. Die
statistische Methode funktioniert also nicht nur bei alphabetischen
Krypttexten, sondern auch bei Zeichen, die nicht dem Alphabet entstammen wie
eben z. B. dem Freimaurer-Code (z.B. www.coord.info/GC1A124) oder dem
Moon-Alphabet (z.B. www.coord.info/GC296J2,
www.coord.info/GC26G7B) oder was
auch immer. Man ersetzt willkürlich jedes Kryptzeichen durch einen
Buchstaben, macht eine Frequenzanalyse dieser Zeichenfolge und schon sollte
einem Brechen des Krypttextes nichts mehr im Wege stehen. Klar ist es
einfacher, wenn man den Code (bzw. den Zeichensatz) kennt, aber zur Not
kommt man eben auch so weiter. Ein weiteres Beispiel eines exotischen
Zeichensatzes ist der wirklich schön gemachte „Sonne, Mond und Sterne“ (www.coord.info/GCY6XR). |
|||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||
|
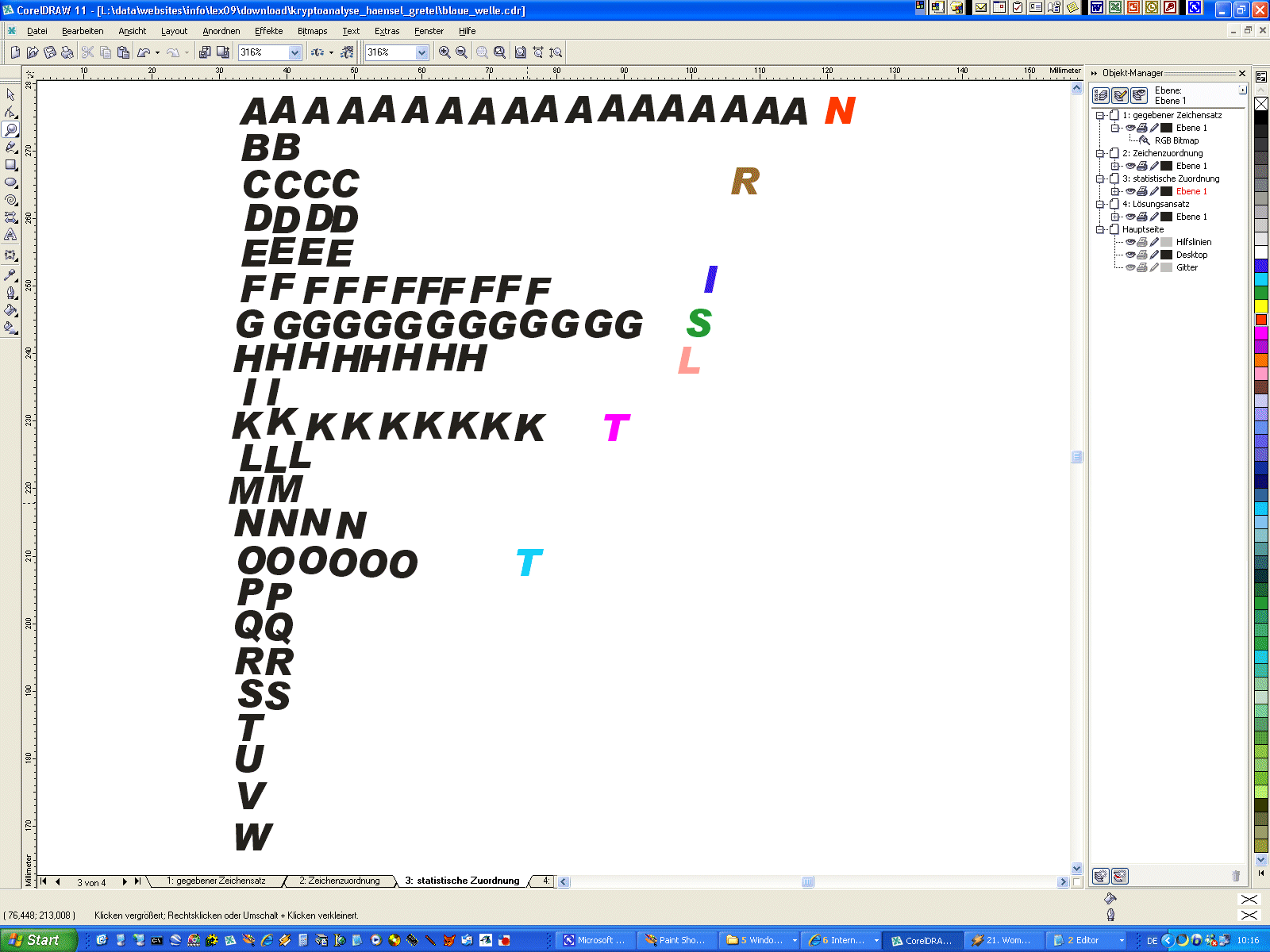
Bei der monoalphabetischen Substitution ist ja
das Problem, dass wir mit einem einzigen Tauschalphabet arbeiten, sodass die
sich die Zeichenhäufigkeiten vom Klartext auf den Krypttext übertragen.
Damit aber ist der Krypttext mit statistischen Methoden sehr leicht
angreifbar. Das ist im Prinzip auch schon lange bekannt.
Bereits im 9. Jahrhundert veröffentlichte der arabische Philosoph al-Kindi
in Bagdad das erste bekannte kryptoanalytische Werk überhaupt, in dem er die
Frequenzanalyse vorstellte. Es dauerte allerdings eine kleine Ewigkeit, bis
sich das auch in Europa rumgesprochen hatte. Und so galt hierzulande die
monoalphabetische Substitution noch lange als sicher. Es sollte bis zur
Renaissance dauern, bis dieses Problem angegangen wurde. Der Florentiner
Leon Batista Alberti stellte 1466 in seinem Werk "De cifris" schließlich ein
verbessertes Verfahren vor. Seine Idee war, statt mit nur einem
Tauschalphabet mit zweien zu arbeiten, zwischen denen man nach jedem dritten
oder vierten Wort wechselt. Damit bekommt jedes Klarzeichen zwei
verschiedene Austauschpartner. Dies ist die einfachste Form der
POLYALPHABETISCHEN Substitution, also einer Substitution, die mehr als nur
ein Tauschalphabet verwendet. Beispiel: Setzen wir als Tauschalphabet mal unseren SONNTAGSSPAZIERGANG ein, im
ersten Fall ab Position 1, im zweiten ab Position 10. Allerdings wechsle ich
hier die Tauschalphabete nicht wie von Alberti vorgeschlagen nur alle paar
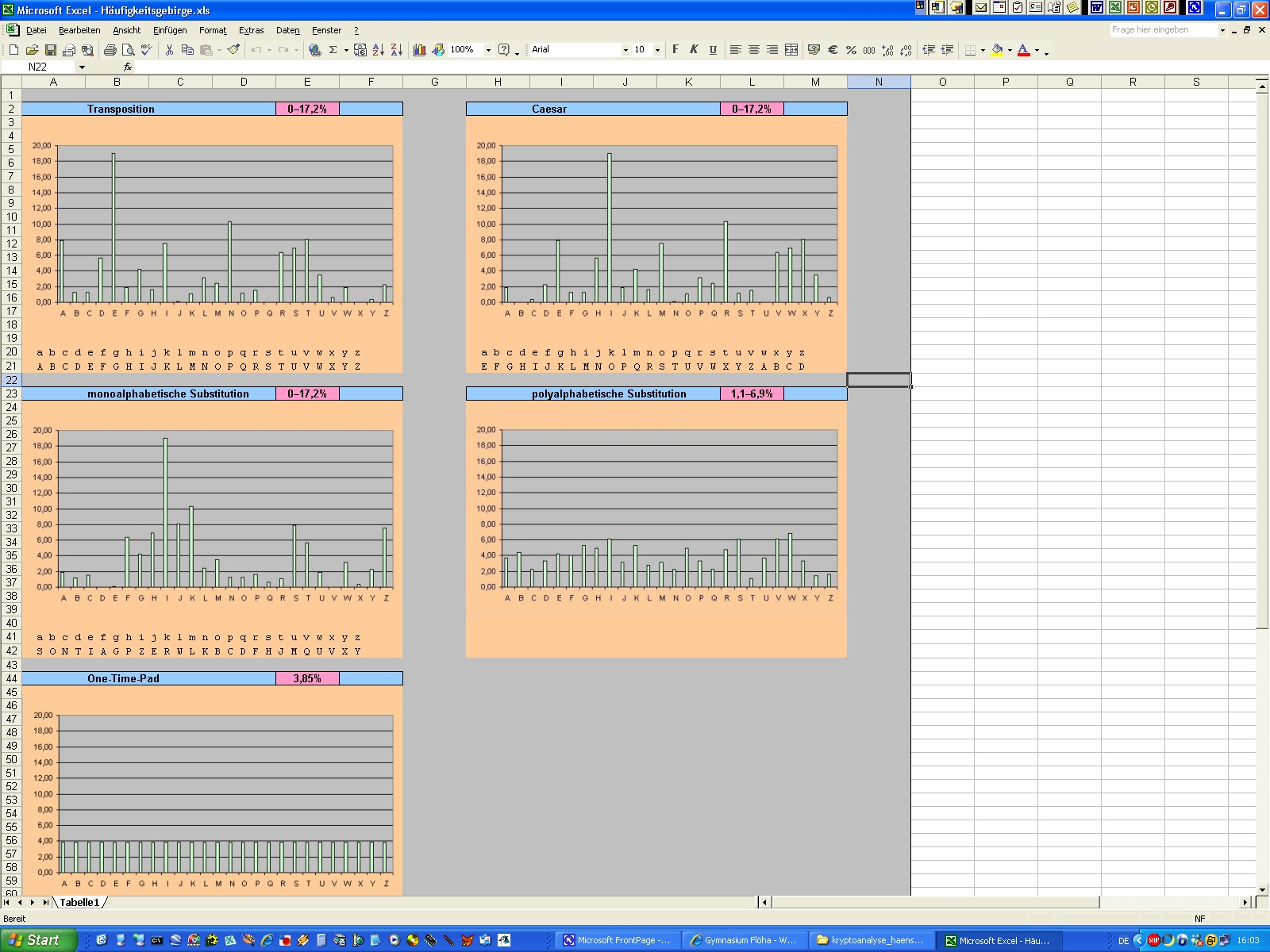
Wörter, sondern nach jedem Klarzeichen: Da wird dann aus "Heute ist ein schöner Tag": p heute ist ein schoener tag Zur besseren Orientierung hab ich mal die Leerzeichen stehen lassen. Man sieht z.B. gleich im ersten Wort, dass das erste "e" zu "U" wurde, das zweite aber zu "A". Wenn wir uns die Frequenzanalyse anschauen, wird deutlich, dass es jetzt nicht mehr so ohne Weiteres möglich ist, einen Tauschkandidaten für "e" zu finden:
Die fünf "e" haben sich aufgeteilt auf zwei "A" und drei "U". Beim Caesar
schwankten die Häufigkeiten beim gleichen kurzen Text zwischen einem und
fünf Vorkommen, hier nun nur noch zwischen einem und drei. Das ist ein
typisches und wichtiges Erkennungsmerkmal polyalphabetischer Verfahren: Die
Höhe der Gipfel und die Tiefe der Täler im Häufigkeitsgebirge wird geringer,
das gesamte Profil wird also gleichmäßiger und wirkt irgendwie eingeebnet.
Wir kommen darauf später noch ausführlicher zurück. |
|||||||||||||||||||||||||||||||
| 5. Systematik bei der Kryptoanalyse einer polyalphabetischen Substitution - Vigečre-Chiffre |
|
|
|
|
|
Über mehrere Zwischenstufen
hat sich die Sache dann weiterentwickelt. Bereits Ende des 15. Jahrhunderts
hatte Trithemius
eine Tafel mit 26 Tauschalphabeten entwickelt, die auf der simplen
Caesar-Verschiebung basieren. Der Einsatz der Caesar-Verschiebung ermöglicht
es, die benötigten Tauschalphabete ganz einfach und ohne Schlüssel oder
sonst was aus dem Kopf aufzustellen. Dabei kommen alle 26 möglichen
Varianten der Verschiebung zum Zug - also auch die Version, bei der jedes
Zeichen auf sich selbst abgebildet wird (das A-Alphabet). Diese Tafel nannte
er "tabula recta". 1553 schlug Giovanni Battista Belaso vor, mehr als zwei Tauschalphabete zu verwenden und sie anhand eines Schlüsselworts auszuwählen. Und schließlich kam Blaise de Vigenčre mit einer Idee, die sich letztlich durchgesetzt hat (1586 veröffentlicht in "Traicté des Chiffres"). Er kombiniert die Tafel von Trithemius mit der Schlüsselwort-Technik von Belaso. Und das geht so: In der Kopfzeile haben wir im Vigenčre-Quadrat die Klarzeichen, darunter stehen alle 26 Verschiebungen von 0 bis 25, also die Tauschalphabete A bis Z. Das Ganze entspricht also der tabula recta von Trithemius. |
| a b c d e f g h i j k l m n o p q r s t u v w x
y z A A B C D E F G H I J K L M N O P Q R S T U V W X Y Z B B C D E F G H I J K L M N O P Q R S T U V W X Y Z A C C D E F G H I J K L M N O P Q R S T U V W X Y Z A B D D E F G H I J K L M N O P Q R S T U V W X Y Z A B C E E F G H I J K L M N O P Q R S T U V W X Y Z A B C D F F G H I J K L M N O P Q R S T U V W X Y Z A B C D E G G H I J K L M N O P Q R S T U V W X Y Z A B C D E F H H I J K L M N O P Q R S T U V W X Y Z A B C D E F G I I J K L M N O P Q R S T U V W X Y Z A B C D E F G H J J K L M N O P Q R S T U V W X Y Z A B C D E F G H I K K L M N O P Q R S T U V W X Y Z A B C D E F G H I J L L M N O P Q R S T U V W X Y Z A B C D E F G H I J K M M N O P Q R S T U V W X Y Z A B C D E F G H I J K L N N O P Q R S T U V W X Y Z A B C D E F G H I J K L M O O P Q R S T U V W X Y Z A B C D E F G H I J K L M N P P Q R S T U V W X Y Z A B C D E F G H I J K L M N O Q Q R S T U V W X Y Z A B C D E F G H I J K L M N O P R R S T U V W X Y Z A B C D E F G H I J K L M N O P Q S S T U V W X Y Z A B C D E F G H I J K L M N O P Q R T T U V W X Y Z A B C D E F G H I J K L M N O P Q R S U U V W X Y Z A B C D E F G H I J K L M N O P Q R S T V V W X Y Z A B C D E F G H I J K L M N O P Q R S T U W W X Y Z A B C D E F G H I J K L M N O P Q R S T U V X X Y Z A B C D E F G H I J K L M N O P Q R S T U V W Y Y Z A B C D E F G H I J K L M N O P Q R S T U V W X Z Z A B C D E F G H I J K L M N O P Q R S T U V W X Y Tithemius
verwendet einfach alle Alphabete der Reihe nach. Der erste Klarbuchstabe
wird mit dem A-Alphabet codiert, der zweite mit dem B-Alphabet etc. Nach dem
Z-Alphabet geht es wieder mit dem A-Alphabet von vorne los. Das entspricht
einem Verfahren, das man heute als "Caesar mit laufendem Schlüssel"
bezeichnet (oder auf schlau: Verschiebechiffre mit inkrementiertem Vektor)
und das doch relativ leicht zu durchschauen ist. |
|
| Beispiel: Der Klartext sei wieder unser "Heute ist ein schöner Tag". Für den ersten Buchstaben des Klartextes bestimmt der erste Buchstabe des Schlüsselworts das Tauschalphabet. Erstes Klarzeichen ist "h", das wird mit dem G-Tauschalphabet codiert, also wird aus dem "h" ein "N", denn im Schnittpunkt von Spalte h und Zeile G steht eben "N". Das zweite Klarzeichen "e" wird mit dem Tauschalphabet codiert, das dem zweiten Schlüsselbuchstaben entspricht, also dem A-Alphabet. Dieses bildet jeden Buchstaben auf sich selbst ab, das "e" wird also "E". Das dritte Klarzeichen ist "u", es wird mit dem Tauschalphabet des dritten Schlüsselbuchstabens codiert, also mit dem R-Alphabet. Schnell ein Blick ins Vigenčre-Quadrat: Im Schnittpunkt von "u" und "R" steht unser drittes Kryptzeichen, und das ist "L". So geht das immer weiter. Das Prinzip ist klar, denke ich. Wenn man am Ende des Schlüsselworts angelangt ist, fängt man einfach wieder vorne bei ihm an: k G A R T E N G A R T E N G A R T E N G A R T p h e u t e i s t e i n s c h o e n e r t a g c N E L M I V Y T V B R F I H F X R R X T R Z Unser Krypttext lautet also: NELMI VYTVB RFIHF XRRXT RZ Jedes Klarzeichen hat jetzt potenziell so viele
Austauschpartner, wie das Schlüsselwort unterschiedliche Buchstaben hat. Das
versaut uns natürlich die Statistik ganz gehörig. Damit wird dann die
Frequenzanalyse zu einem stumpfen Schwert in der Hand des Kryptoanalytikers
- könnte man meinen. Weit gefehlt, es wird nur alles etwas komplizierter und
strapaziöser.
Vigenčre-Tool von haensel + gretel Ganz rechts gibt es noch die Funktion "Anzeige Zeichen". Das funktioniert
aber nur für das Verschlüsseln und ist daher weg gedimmt, wenn Entschlüsseln
eingestellt ist. Wenn hier z.B. 3 eingestellt ist, wird im Vigenčre-Quadrat
die Spalte mit dem dritten Klartextzeichen und die Zeile mit dem dafür
relevanten Schlüsselzeichen eingefärbt. Am Schnittpunkt der beiden
Markierungen kann man dann das Kryptzeichen ablesen. Das klappt aber nur
fehlerfrei, wenn zu verschlüsselnder Klartext und Schlüssel keine anderen
Zeichen als Buchstaben enthalten (auch keine Leerzeichen) - sonst kommt eine
falsche Anzeige zustande. |
|
| So, machen wir weiter! Wie immer
dran denken: nichtproportionale Schrift zur Anzeige verwenden (z.B.
Courier). Wir waren beim Vigenčre, also dem Klassiker der polyalphabetischen
Substitution, den wir heute nach allen Regeln der Kunst brechen werden. Wir
hatten letztes Mal besprochen, dass bei einem Vigenčre umso mehr
Tauschalphabete eingesetzt werden (und das Verfahren damit umso sicherer
wird), je mehr unterschiedliche Buchstaben das Schlüsselwort enthält, womit
es natürlich auch länger wird. Dem steht aber entgegen, dass das
Schlüsselwort möglichst gut zu merken sein soll und auch unauffällig zu
übergeben sein muss. Das wiederum ist mit möglichst kurzen Wörtern am besten
möglich. Der Kompromiss liegt wie immer in der Mitte. Üblich sind
Schlüsselwortlängen von acht bis fünfzehn Buchstaben. Das hat sich als am
praktikabelsten erwiesen.
Kürzere Schlüsselwörter sind zu unsicher, längere schlecht zu merken und zu
handhaben. |
|
| Nachtrag zu Lektion 6 aufgrund einiger Nachfragen Vom CrypTool gibt es eine Online- und eine Offline-Version. Empfehlenswert ist - wie in KrySem03 angemerkt - das Programm runterzuladen und zu installieren. Ist einfach bequemer und auch von der Datensicherheit her besser, als immer alles online zu machen. Also das Programm von http://www.cryptool.org/ct1download/SetupCrypTool_1_4_30_de.exe runterziehen und installieren. Wenn man das Programm dann laufen lässt, kann man entweder einen Krypttext reinladen oder - einfacher - den Text auf der Startseite einfach löschen und stattdessen den Krypttext da reinkopieren. Es ist übrigens empfehlenswert, den Text vor dem Reinkopieren etwas vorzubereiten (z.B. in einer Textverarbeitung). Der ganze Text sollte ein einziger Absatz sein. Also alle Buchstaben zusammenziehen ohne Absätze dazwischen. Außerdem ist es meist hilfreich, alle Satz- und Leerzeichen zu entfernen, sodas ein reiner Buchstabenstrang übrigbleibt. Den dann ins CrypTool reinkopieren. Dann zu "Analyse/ Symmetrische Verschlüsselung (klassisch)/ Ciphertext-only/ Vigenčre". CrypTool schlägt nun eine Schlüssellänge vor. Die kann man entweder akzeptieren ("Weiter") oder korrigieren. Als nächstes schlägt CrypTool ein Schlüsselwort vor. Wiederum entweder akzeptieren ("Weiter") oder korrigieren. Dann wird der Kryptext mit diesem Schlüsselwort entschlüsselt. Und jetzt kann man erkennen, ob das so hinkommt. Wenn perfekter Klartext entsteht ist alles gut. Wenn der Klartext Fehler aufweist, dann stimmt wohl was mit dem Schlüsselwort nicht. Dann sollte man versuchen rauszufinden, welche Schlüsselbuchstaben falsch sind und wie sie wohl richtig lauten müssten (s. KrySem06). Wenn überhaupt nichts Brauchbares erscheint, war entweder das Schlüsselwort völlig daneben oder bereits die Schlüssellänge falsch. Randbemerkung: CrypTool gibt unüblicherweise Klartext in Großbuchstaben aus, davon darf man sich nicht verwirren lassen. Bei dem genannten Beispielcache "Station X" ermittelt CrypTool die Schlüssellänge korrekt mit 10. Als Schlüsselwort schlägt es "NLANTJRING" vor, was wenig vertrauenserweckend ist. Wobei z.B. der Schluss ("...RING") ja nicht ganz schlecht aussieht. Die Schlüssellänge könnte also gestimmt haben. Also einfach mal entschlüsseln lassen. Im Klartext erkennt man, wo die Probleme liegen: GHECANHEISAOWHIODENOHTSIDPOUROSFICEHINDOJSTOP... Der Anfang wird wohl heißen müssen: THE CACHE IS ... Also stimmt das erste Klarzeichen nicht ("G" statt "T") und auch das sechste ist falsch ("N" statt "C"). In der Folge sind natürlich dann auch der 11., der 16. der 21. der 26. etc. Klarbuchstabe falsch, weil die ja jeweils auf den 1. bzw. 6. Schlüsselbuchstaben treffen (falsche Buchstaben mit * markiert, an nichtproportionale Schrift denken): 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 N L A N T J R I N G N L A N T J R I N G N L A N T J R I N G G H E C A N H E I S A O W H I O D E N O H T S I D P O U R O * * * * * * Nun kann man rumprobieren und einfach mal an den falschen Schlüsselbuchstaben rumspielen. Oder man kann rechnen. Die Rechnung geht wie folgt: Erst mal muss man beachten, dass beim Vigenčre das Klarzeichen im Alphabet nach vorne rückt, wenn man mit dem Schlüsselbuchstaben im Alphabet nach hinten rückt. Klarzeichen und Schlüsselzeichen bewegen sich also entgegengesetzt. Beispiel: Entschlüsseln wir das Kryptzeichen "F" mit dem Schlüsselzeichen "D", erhalten wir "c". Rücken wir mit dem Schlüsselzeichen im Alphabet um ein Zeichen nach hinten, also zu "E", landen wir beim Entschlüsseln von "F" bei "b". Schlüsselzeichen und Klarzeichen bewegen sich also entgegengesetzt. Wollen wir mit dem Klarzeichen nach vorne, muss das Schlüsselzeichen nach hinten rücken und umgekehrt. Das erste Klarzeichen in unserer Probeentschlüsselung ist "g", müsste aber "t" sein. Wir sind 13 Zeichen im Alphabet zu weit vorne, müssen damit also im Alphabet um 13 Stellen nach hinten rücken. Das heißt, wir müssen mit dem Schlüsselbuchstaben in die andere Richtung, sprich im Alphabet nach vorne. Der erste Schlüsselbuchstabe ist "N". Verlagern wir den mal 13 Buchstaben weiter nach vorne. Damit landen wir beim "A". Das Gleiche beim sechsten Klarzeichen. Wir haben ein "n", brauchen aber ein "c". Wir sind mit dem Klarzeichen elf Stellen zu weit hinten im Alphabet, müssen also weiter nach vorne (und damit mit dem Schlüsselbuchstaben nach hinten). Der sechste Schlüsselbuchstabe ist "J". Zählen wir elf Stellen nach hinten im Alphabet, landen wir bei "U". Unser Schlüsselwort muss also "ALANTURING" lauten. Also das CrypTool nochmal mit dem Krypttext starten. Schlüssellänge 10 bestätigen. Dann das falsch ermittelte Schlüsselwort korrigieren und entschlüsseln lassen. Schon haben wir den Klartext. Das Rumfummeln am Schlüssel kann man auch in unserem Vigenčre-Tool machen. Da geht es noch etwas besser, weil man bei Veränderungen des Schlüsselworts gleich das Ergebnis sieht und nicht jedesmal vor vorne beginnen muss. Allerdings verhaspelt sich das CrypTool recht oft bei der Bestimmung der Schlüssellänge. Daher hab ich jetzt doch noch ein Kasiski-Tool gebastelt. Bei unserem Beispiel "Station X" ist die bei den meisten Fundstellen vertretene Primfaktorenkombination 2 x 5. Die ergibt die Schlüssellänge 10. |
|
| ****************** 7 ****************** Noch ein kurzer Nachtrag zum letzten Mal. Habt Ihr die angegebenen Beispiele ausprobiert? Ist es Euch gelungen, der "kryptos" zu knacken? Falls nicht, dann liegt heute der Kasiski-Test dafür bei. Damit sollte es dann keine Hürden mehr geben ("WSD", "JGR" und "CWG" sind Zufallstreffer, aber das erkennt Ihr ja inzwischen selbst). Nachdem wir jetzt die mono- und die polyalphabetische Substitution in ihren Grundlagen durchgesprochen haben, kommen wir dieses Mal noch zu vier etwas spezielleren Substitutionsformen - drei polyalphabetischen und einer monoalphabetischen. Diese sind zwar beim Cachen nur selten anzutreffen, aber man sollte dennoch zumindest mal davon gehört haben. Das gehört einfach zum kleinen Einmaleins der Kryptologie. Stellen wir erst mal paar Überlegungen zur Sicherheit der Verschlüsselungsmethoden an, die wir bisher besprochen haben. Beim Caesar gibt es ja nur 25 Schlüssel. Da ist der schnellste Weg zum Klartext ein Brute-force-Angriff, also einfach das Durchprobieren aller erdenklichen Möglichkeiten - das ist sogar noch schneller als die statistische Methode. Von Sicherheit kann hierbei natürlich keine Rede sein. Bei der allgemeinen monoalphabetischen Substitution beträgt der Schlüsselraum 26! (Fakultät 26, also 2 x 3 x 4 x 5 x 6 ... x 25 x 26), das ist eine gewaltige Zahl, nämlich 400 Quadrillionen - eine 4 mit 26 Nullen. Ein Brute-force-Angriff wäre in diesem Fall selbst mit einem ganzen Rechenzentrum völlig aussichtslos. Doch hier gibt es ja eine nette Abkürzung: die statistische Methode. Beim Vigenčre hängt die Größe des Schlüsselraums von der Schlüssellänge ab und beträgt 26^d (26 hoch Schlüssellänge). Bei einer Schlüssellänge von sechs sind das also immerhin rund 309 Millionen Möglichkeiten. Wenn man nun alle Möglichkeiten mit einer Schlüssellänge von sagen wir mal vier bis sieben durchprobieren will, sind das gut 83 Milliarden Möglichkeiten. Moderne Großrechner schaffen gut eine Million Versuche pro Sekunde inklusive der Auswertung, ob sinnvoller Text dabei rauskam. In knapp drei Stunden müsste man also ein Ergebnis haben. Will man aber z.B. alle Möglichkeiten mit einer Schlüssellänge von vier bis fünfzehn durchnudeln, kommt man auf rund 1,7 Trilliarden mögliche Schlüssel. Bei einer Million Versuchen pro Sekunde wären also gut 55 Millionen Jahre notwendig, um alles durchzuprobieren. Klarer Fall: brute-force-mäßig keine Chance. Doch auch der Vigenčre ist wie gesehen statistisch angreifbar, sofern die Textlänge nicht zu kurz ist. Was also kann man tun, um die Sicherheit zu erhöhen? Natürlich kann man wilde Systeme ersinnen, aber das Verfahren muss ja neben der Sicherheit auch einige weitere Bedingungen erfüllen. Es muss relativ einfach, schnell und unauffällig zu handhaben sein (wohlgemerkt möglichst auch ohne Computer). Es muss mit einem Schlüssel arbeiten, den man sicher und problemlos übermitteln kann und der möglichst auch gut zu merken sein sollte. Das Verfahren sollte auch unter widrigen Umständen gut funktionieren, z.B. auf hoher See, an der Front oder bei Expeditionen. Ohne elektronische Unterstützung ist das keine leichte Aufgabe und die Kryptographen haben sich damit zu allen Zeiten redlich abgemüht. |
|
|
One-Time-Pad und Vigenčre-Autokey Dieses Problem erkannte auch bereits Vigenčre selbst. Er hatte schon in "Traicté des Chiffres" (1586) ein verbessertes Verfahren beschrieben, dass sich aber aus unerfindlichen Gründen nie recht durchsetzen konnte. Die zugrundeliegende Überlegung ist ebenso einfach wie genial. Je länger das Schlüsselwort, desto sicherer das Verfahren. Ideal wäre es, für jedes Klarzeichen ein anderes Schlüsselzeichen zu verwenden, am besten nach einer rein zufälligen Abfolge. Es gibt dabei nur ein Problem: Wenn wir so vorgehen, dann wird der Schlüssel ebenso lang wie der Klartext. Damit haben wir ein ernsthaftes Problem, denn wir müssen dem Empfänger den Schlüssel ja auf einem absolut sicheren Kanal übermitteln. Wenn der Schlüssel aber so lang ist wie die Botschaft selbst und einen sicheren Kanal erfordert, dann können wir uns das Verschlüsseln auch sparen und gleich die Botschaft selbst übermitteln. Ist also für den regulären Gebrauch unpraktikabel, denn einen so sicheren Kanal gibt es im Regelfall einfach nicht. Trotzdem gibt es diese Methode im praktischen Einsatz. Sie heißt "One-Time-Pad" und ist tatsächlich nicht zu brechen - das lässt sich mathematisch beweisen. Voraussetzung ist aber eben, dass der Schlüssel wirklich so lang wie der Klartext ist, dass es sich bei ihm um eine rein zufällige Zeichenfolge handelt und dass jeder Schlüssel nur ein einziges Mal verwendet wird (daher auch der Name). Dann - und nur dann - ist das Ganze definitiv nicht zu knacken. Das One-Time-Pad ist sehr aufwendig, wurde und wird aber dennoch zum Nachrichtenaustausch auf höchster Ebene genutzt. Hochrangige diplomatische Kanäle, besonders heikle Agentennetze und auch der berühmte heiße Draht zwischen Washington und Moskau verwenden es. Das One-Time-Pad ist also ein wirklich absolut sicheres Verfahren, sofern es korrekt eingesetzt wird. Das Hauptproblem ist und bleibt aber die sichere Übergabe und Verwahrung des ausgesprochen unhandlichen Schlüssels. Merken kann man sich einen solchen Schlüssel natürlich nicht. Also braucht man verräterische Unterlagen. Und in der Tat sind schon zahlreiche Agenten dadurch aufgeflogen, dass man bei ihnen solche Schlüssellisten gefunden hat. Wie könnte man dieses Problem umgehen? Vigenčres wirklich bestechende Idee ist eigentlich recht simpel, man muss nur drauf kommen: Das Problem ist ja der endlos lange und damit unmerkbare Schlüssel. Vigenčre versuchte sich der Sache zu nähern, indem er zwar keine Zufallsfolge, aber doch ein sehr langes Schlüsselwort erdachte, das man sich natürlich nicht merken kann, aber auch gar nicht muss. Und das geht so: Man hat ein Schlüsselwort von sagen wir mal der Länge sechs - etwa unser GARTEN. Mit dem wird ganz normal nach Vigenčre verschlüsselt. Bis zum sechsten Buchstaben. Für den siebten Buchstaben würde man beim klassischen Verfahren wieder mit dem ersten Schlüsselbuchstaben anfangen. Bei Vigenčres Trick geht es aber einfach mit dem Klartext weiter. Der Klartext wird quasi mit sich selbst als Schlüsselwort verschlüsselt, nur dass Klartext und Schlüssel um die sechs Stellen des Schlüsselworts gegeneinander verschoben sind. Ganz schön pfiffig, was? Dieses Verfahren ist heute bekannt unter der Bezeichnung "Vigenčre-Autokey" oder auch einfach "Autokey". Das Verfahren ist etwas umständlicher als der klassische Viegenčre, aber wirklich enorm viel sicherer. Allerdings erreicht es bei Weitem nicht die Sicherheit des echten "One-Time-Pad", denn beim Schlüssel handelt es sich ja eben gerade nicht um eine Zufallsfolge, sondern um sinnvollen Text, der damit durch die in ihm enthaltene Information auch ein Muster aufgeprägt bekommt. Allerdings ist das Brechen eines Autokey auch mit Computerunterstützung wahrlich kein Spaziergang. |
| 6. Dechiffrierprojekt Vigenčre-Code Informatikkurs 2006/07 |
|
|
|
|
|
Auch hier verdanken wir die Masse der Zuarbeit eine Fortbildung für Informatiklehrer im Jahre 2005 in Dresden. Aber auch das JEFFERSON-Rad oder andere Verschiebetabellen sind gut geeignet, um Nachrichten nach Vigenčre-Code zu chiffrieren. Ganz raffiniert lässt sich natürlich auch hier wieder das Krypto-Tool einsetzen. |
| 7. Web-Links zum Thema Vigenčre und weiteren Polyalphabetischen Chiffren |
|
|
|
|
|
|
| 8. Aufgaben zum Thema Vigenčre |
|
|
|
|
|
Der Vigenčre- Ciffre ist eine polyalphabetischer Substiutionscode, das heißt, das ein und derselbe Buchstabe auf mehrere verschiedene Möglichkeiten hin verschlüsselt werden kann. Das macht diesen Chiffre auch heute noch und besonders bei kurzen Texten sehr schwer angreifbar. Aber für die ersten Aufgaben nutzen wir ja die Kenntnis der Schlüssel ;-) |
| 9. Verwandte Themen |
|
|
|
|
|
Da monoalphebetische Chiffren die Mutter alles Verschlüsselungstechniken waren, sind sie zu faktisch jedem Bereich der Kryptologie verwandt. Und da via Computer die Krptologie auch etwas mit Binärmustern zu tun hat, gibt es auch ein reizvolles Verhältnis zur Logik. | |||
|
||||
|
|
zur Hauptseite |
© Samuel-von-Pufendorf-Gymnasium Flöha | © Frank Rost am 5. Juli 2012 um 22.19 Uhr |
|
... dieser Text wurde nach den Regeln irgendeiner Rechtschreibreform verfasst - ich hab' irgendwann einmal beschlossen, an diesem Zirkus nicht mehr teilzunehmen ;-) „Dieses Land braucht eine Steuerreform, dieses Land braucht eine Rentenreform - wir schreiben Schiffahrt mit drei „f“!“ Diddi Hallervorden, dt. Komiker und Kabarettist |
|
Diese Seite wurde ohne Zusatz irgendwelcher Konversationsstoffe erstellt ;-) |