| Base64- & Radix64-Codierung |
|
|
Letztmalig dran rumgefummelt: 17.04.26 11:39:57 |
|
|
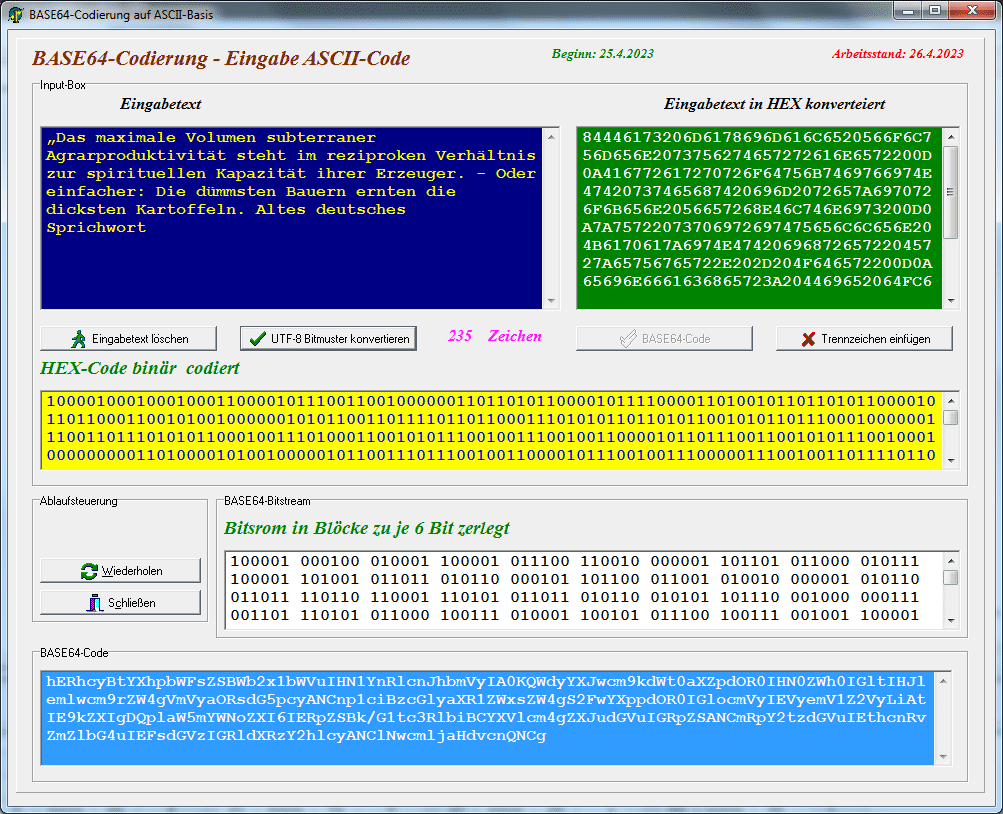
Base64 ist ein Begriff aus
dem Computerbereich und beschreibt ein Verfahren zur Kodierung von
8-Bit-Binärdaten (z. B. ausführbare Programme, ZIP-Dateien), in eine
Zeichenfolge, die nur aus lesbaren Codepage-unabhängigen ASCII-Zeichen
besteht. Im Zusammenhang mit OpenPGP wird noch eine Prüfsumme (CRC-24)
angehängt; dieses leicht modifizierte Verfahren trägt den Namen Radix-64. Es findet im Internet-Standard MIME (Multipurpose Internet Mail Extensions) Anwendung und wird damit hauptsächlich zum Versenden von E-Mail-Anhängen verwendet. Nötig ist dies, um den problemlosen Transport von beliebigen Binärdaten zu gewährleisten, da SMTP in seiner ursprünglichen Fassung nur für den Versand von 7-Bit-ASCII-Zeichen ausgelegt war. Durch die Kodierung steigt der Platzbedarf des Datenstroms um 33-36 % (33 % durch die Kodierung selbst, bis zu weitere 3 % durch die im kodierten Datenstrom eingefügten Zeilenumbrüche). Zur Kodierung werden die Zeichen A–Z, a–z, 0–9, + und / verwendet, sowie = am Ende. Da diese Zeichen auch in EBCDIC (Extended Binary Coded Decimals Interchange Code) vorkommen (wenn auch an anderen Code-Positionen), ist damit auch ein Datenaustausch zwischen nicht-ASCII-Plattformen möglich. nach WIKIPEDIA |
||||||
|
1. Zum technischen Verfahren 2. Der Base64-Code 3. Software zum Code 4. BASE64-Verfahren 5. Weitere äquivalente Codes |
|||||||
|
| 1. Zum technischen Verfahren |
|
|
|
|
|
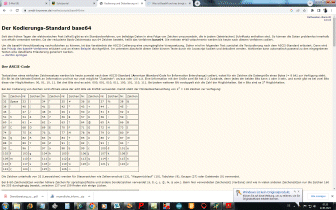
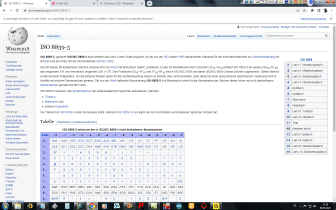
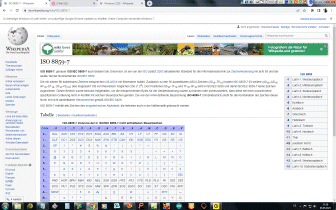
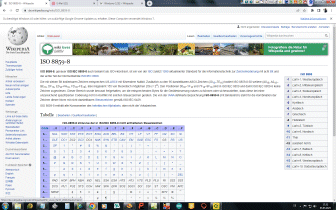
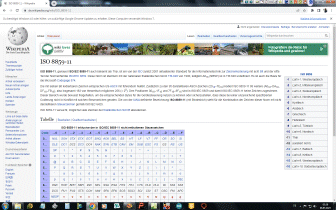
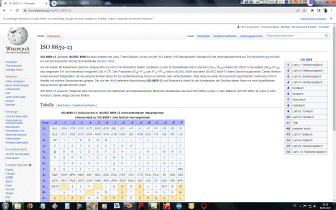
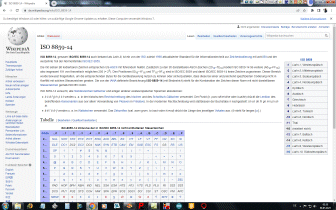
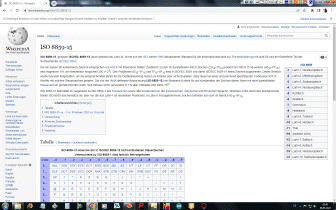
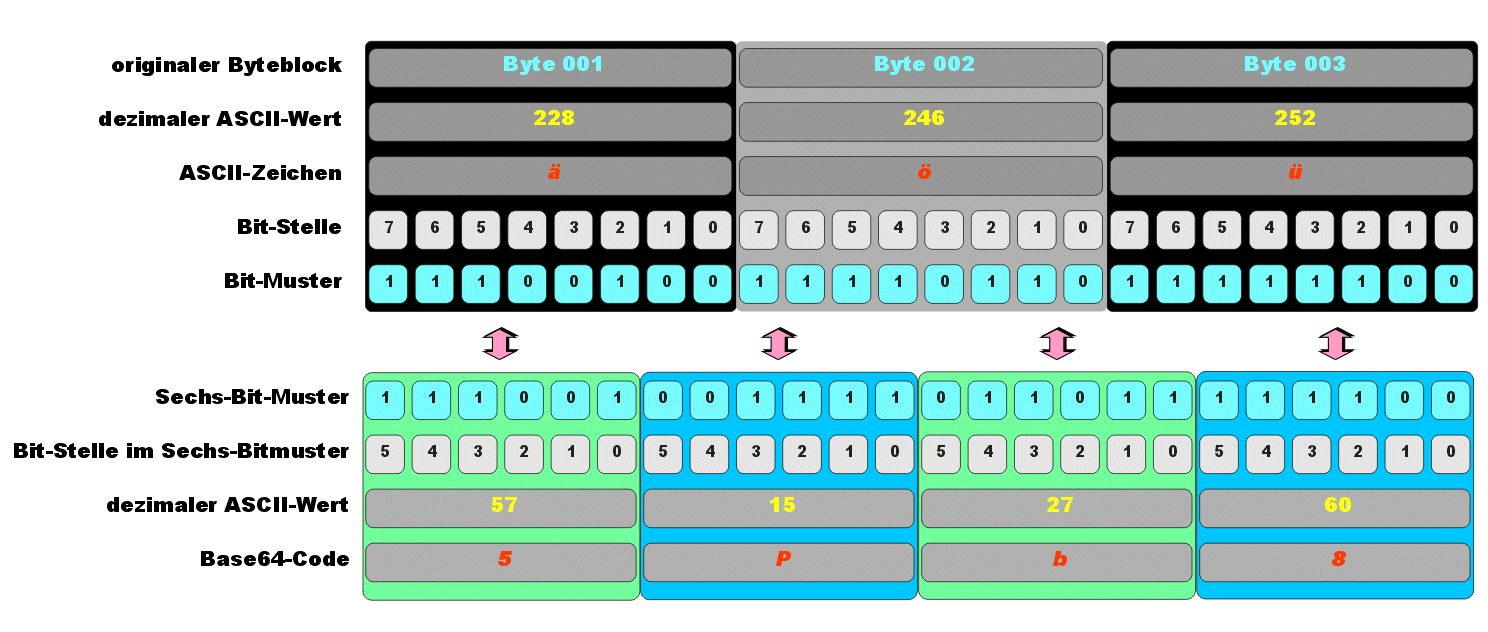
Eingegebener ASCII-Code wird in Hexadezimal-Format gewandelt, anschließend in die zugehörigen 8-Bit Muster. Diese werden in Gruppen zu je sechs Bit aufgelöst und anschließend nach der weiter unten stehenden Codetabelle wieder in Zeichen aus den Gruppen A bis Z, a bis z, 0 bis 9 sowie die Zeichen +, und / umcodiert. |
|||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
 |
||||||||||||||||||||||||||||||||||||
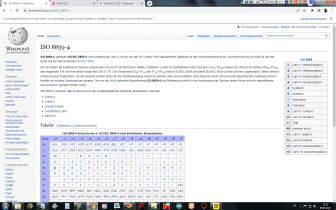
Padding
Falls die Gesamtanzahl der Eingabebytes nicht durch drei teilbar ist,
beinhaltet der letzte Eingabeblock weniger als 24 Bits. In diesem Fall ist
ein Padding der
Eingabedaten erforderlich. An den Eingabeblock werden Nullbits angehängt,
bis die Länge durch 6 teilbar ist. Anschließend wird die Ausgabe mit einem
oder zwei
Da sich die Anzahl der ursprünglichen Bytes immer eindeutig aus der Anzahl der Base64-Eingabe-Zeichen ermitteln lässt, wird in manchen Kontexten und Protokollen kein Padding verwendet (abweichend von der ursprünglichen Base64-Definition). |
||||||||||||||||||||||||||||||||||||
|
| 2. Der Base64-Code |
|
|
|
|
|
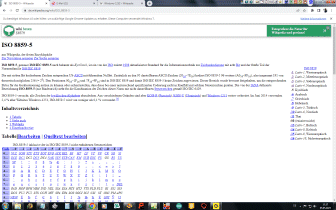
Der Code Maria Stuarts war eine Mischung aus Chiffre und Codes, wobei er in sich und für seine Zeit ziemlich komplex war. Heute würden wir von einem mächtigen Algorithmus sprechen auch war der Schlüssel sehr sicher. Das Verfahren war jedoch monoalphabetisch und damit wiederum leicht angreifbar. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
| 3. Software zum Code |
|
|
|
|
|
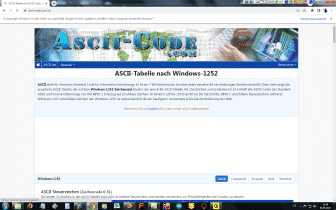
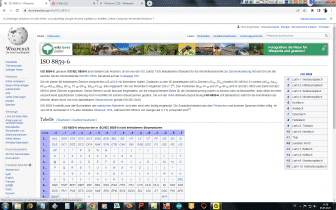
Eingabeformat ist Standard-ASCII-Text - die Ausgabe erfolgt im WINDOWS-1252 Format. Das sind beides Standardformate, welche auch von anderen Betriebssystemen gelesen werden können. Dies eben, weil es Standards sind. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4. BASE64-Verfahren |
|
|
|
|
|
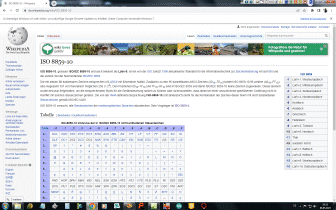
Base64 ist ein
Verfahren zur Kodierung von 8-Bit-Binärdaten (z. B. ausführbare Programme,
ZIP-Dateien oder Bilder) in eine Zeichenfolge, die nur aus lesbaren,
Codepage-unabhängigen ASCII-Zeichen besteht. Es findet im Internet-Standard Multipurpose Internet Mail Extensions (MIME) Anwendung und wird dort zum Versenden von E-Mail-Anhängen verwendet. Nötig ist dies, um den problemlosen Transport von beliebigen Binärdaten zu gewährleisten, da SMTP in seiner ursprünglichen Fassung nur für den Versand von 7-Bit-ASCII-Zeichen ausgelegt war. Durch die Kodierung steigt der Platzbedarf des Datenstroms um 33–36 % (33 % durch die Kodierung selbst, bis zu weitere 3 % durch die im kodierten Datenstrom eingefügten Zeilenumbrüche). Base64 wird zum Beispiel auch zur Kodierung von Benutzernamen und Passwort in der HTTP-Basisauthentifizierung und zur Übertragung von SSH-Server-Zertifikaten verwendet. |
||||||||||
|
| 5. Weitere äquivalente Codes |
|
|
|
|
|
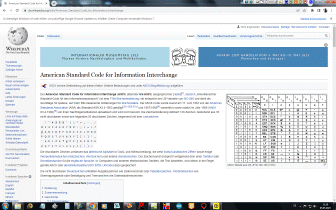
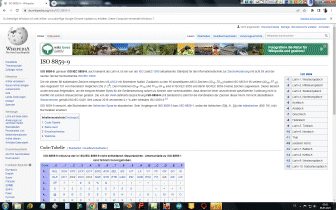
Mit dem Base64-Verfahren werden 8-Bit-Binärdaten in lesbare ASCII Zeichen kodiert. Zur Kodierung werden die Zeichen A-Z, a-z, 0-9, + und / verwendet, sowie 0, 1 oder 2 = am Ende des Base64-kodierten Strings, die die Anzahl der Füllbytes darstellen. Zur Kodierung werden jeweils 3 Byte der Eingabedaten in vier 6-Bit-Blöcke aufgeteilt und diese 64 möglichen Zeichen auf druckbare ASCII-Zeichen gemappt. Bei der Dekodierung werden nicht darstellbare Zeichen durch ein graues Rechteck ░ ersetzt. | ||||||||||||||||||||||||||||||||
| UTF-8 (UCS Transformation Format) und UCS-2 ( Universal Coded Character
Set) sowie UNICODE - https://de.wikipedia.org/wiki/UTF-8 RFC 3629 / STD 63 (2003) - 05.10.2016 — In der Theorie kann UTF-8 zwar Sequenzen aus bis zu 8 Bytes enthalten, RFC 3629 hat die erlaubte Anzahl aber auf 4 Bytes reduziert. The Unicode Standard, Version 4.0, §3.9–§3.10 (2003) ISO/IEC 10646-1:2000 Annex D (2000) UTF-16 Little Endian EBCDIC ASCII ISO-8859-2 ISO-8859-6 ISO-8859-15 UU-Encoding |
|||||||||||||||||||||||||||||||||
 Code-Übersicht - genial |
|||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||
|
zur Hauptseite |
© Samuel-von-Pufendorf-Gymnasium Flöha | © Frank Rost am 6. November 2010 um 11.21 Uhr |
|
... dieser Text wurde nach den Regeln irgendeiner Rechtschreibreform verfasst - ich hab' irgendwann einmal beschlossen, an diesem Zirkus nicht mehr teilzunehemn ;-) „Dieses Land braucht eine Steuerreform, dieses Land braucht eine Rentenreform - wir schreiben Schiffahrt mit drei „f“!“ Diddi Hallervorden, dt. Komiker und Kabarettist |
|
Diese Seite wurde ohne Zusatz irgendwelcher Konversationsstoffe erstellt ;-) |
![]()


{kind=link}
{kind=link}