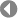


| Bucketsort | |
|
|
 |
Bucketsort: 1. Variante Gänzlich verschieden zu den bisher besprochenen Sortieralgorithmen arbeitet Bucketsort. Das Grundprinzip besteht darin, dass das Feld (Primärfeld) nicht in sich selbst sortiert sondern zwischenzeitlich auf ein zweites Feld (Sekundärfeld) abgebildet wird. Dabei werden die Elemente während des ersten Felddurchlaufs in Buckets (engl. Eimer, Behälter) einsortiert und anschließend während eines zweiten Durchlaufs wieder in das Ausgangsarray zurückgeschrieben. Bucketsort in seiner einfachsten Form könnte wie folgt aussehen.
|
|
|
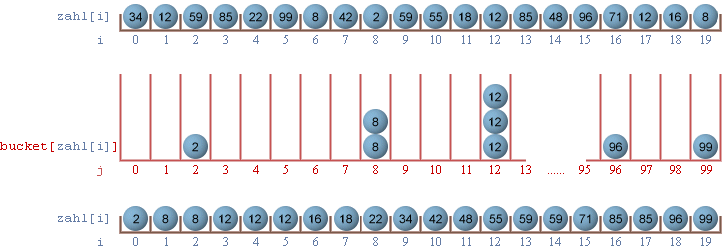
Handelt es sich bei den zu sortierenden Elementen wie in unserem Falle um Integerzahlen, so kann das Sekundärfeld einfach mitzählen, wie häufig eine Zahl im Primärfeld auftritt, z.B.
|
|
|
||
|
Vorteil von Bucketsort: Da das zu sortierende Feld nicht pausenlos hin und her geschichtet werden muss, ist Bucketsort (unter bestimmten Gegebenheiten) ein ausgesprochen flinker Sortieralgorithmus. Nachteile von Bucketsort: Die nähere Beschäftigung mit Bucket Sort bringt eine ganze Reihe von Nachteilen ans Tageslicht. So ist zum Beispiel die Dimensionierung des Bucket-Feldes von der Vielfalt der Werte im Primärfeld abhängig. Treten viele verschiedene Werte auf, so muss ein großes Bucket-Feld dimensioniert werden, obwohl dieses u.U. nur zu einem Bruchteil ausgelastet wird. Bucketsort wird sich also nur dort wirklich anbieten, wo die Wertevielfalt relativ gering ist. Legt man das Bucket-Feld als statisches Array an, so wird man häufig eine enorme Speicherplatzverschwendung in Kauf nehmen müssen. Jedes einzelne Bucket müsste im ungünstigsten Falle das gesamte Primärfeld aufnehmen können, wohingegen alle anderen Buckets leer blieben. Wenn man es mit Bucketsort wirklich ernst meint, kommt man an dynamischen Feldern nicht vorbei. Ein dritter Aspekt sei genannt. Während die Behandlung eines Integer-Feldes mit wenigen Programmzeilen erledigt ist, muss man bei Real-Zahlen oder gar Strings schon deutlich mehr Aufwand betreiben. Summa summarum lässt es Bucketsort auch an der nötigen Universalität fehlen.
|
|
|
Bucketsort: 2. Variante Erhöhen wir nun den Schwierigkeitsgrad ein bisschen und versuchen uns an einem Array aus zufällig erzeugten Real-Zahlen zwischen 0 und 100. Im Applikationsfenster ist das Prinzip dargestellt. Der Wertebereich ist in 10 gleichgroße Intervalle (analog Buckets) aufgeteilt. Jede Zahl wird an einem Kriterium (Schlüssel) gemessen, welches das richtige Bucket zuordnet. Ist dieses gefunden, wird die Zahl innerhalb des Buckets gleich noch mit Insertionsort einsortiert. Das anschließende Zurückschreiben in das Ausgangsfeld ist nun ein Kinderspiel.
|
|
|
Wir vereinbaren für die Buckets einen eigenen Typ (TBucket), der einerseits die Feldelemente aufnehmen kann und andererseits die Anzahl der im jeweiligen Bucket abgelegten Elemente erfasst.
|
|
|
||